 NEWSLETTER
NEWSLETTER

Focallens: Instruction tuning allows representations of zero shooting images
This document was accepted in the workshop in base models in nature in ICLR 2025. Visual understanding is inherently contextual: ...
This document was accepted in the workshop in base models in nature in ICLR 2025. Visual understanding is inherently contextual: ...

Large multimodal models (LMM) have demonstrated notable capabilities when they train in extensive visual text data, which significantly advance multimodal ...

Outstanding podcasts Lenny Podcast: Become a better communicator: specific frames to improve its clarity, influence and impact | Wes Kao ...
Imagine that he has a single picture of a person and wants to see them come alive in a video, ...
In this tutorial, we explore how to configure and execute a sophisticated portfolio of recovery generation (RAG) on Google Colab. ...
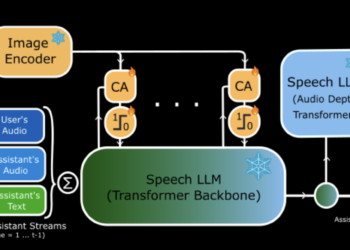
artificial intelligence has made significant advances in recent years, but integrating the interaction of real -time speech with visual content ...
Image text dissemination models (T2I) have shown impressive results in the generation of visually convincing images after user indications. On ...

I've been wondering why everyone seems so excited Clear Oscure: Expedition 33. It is the Sandfall Interactive debut, an independent ...

Access to high quality textual data is crucial to advance in language models in the digital era. Modern ai systems ...
Mobilenet is an open source model created to support the appearance of smartphones. Use a CNN architecture to perform computer ...




