
Gradient Boosting | Towards Data Science
ENSEMBLE LEARNINGFitting to errors one booster stage at a timeOf course, in machine learning, we want our predictions spot on. ...

ENSEMBLE LEARNINGFitting to errors one booster stage at a timeOf course, in machine learning, we want our predictions spot on. ...
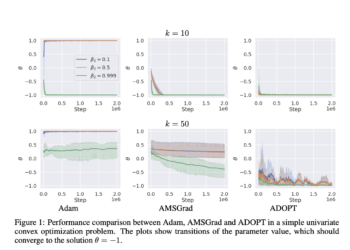
Adam is widely used in deep learning as an adaptive optimization algorithm, but it has difficulty with convergence unless the ...
Years of suboptimal model training?10 minutes of reading·12 hours agoAuthor's imageWhen locally tuning large language models (LLMs), using large batch ...

Machine learning has made significant advances, particularly through deep learning techniques. These advances rely heavily on optimization algorithms to train ...

In addition to minimizing a single training loss, many deep learning estimation sequences rely on an auxiliary objective to quantify ...

This is a guest post co-written with Michael Feil at Gradient. Evaluating the performance of large language models (LLMs) is ...

A young startup is setting out to transform the command line interface (CLI) into something a little more appropriate for ...

In a recent research paper, a team of KAIST researchers presented SYNCDIFFUSION, an innovative module that aims to improve panoramic ...

The mountain hiker analogy: Imagine you are a mountain hiker and you find yourself somewhere on the slopes of a ...

Helium Co-Founder and Early Founding Team Member Launches White Label Blockchain Node-as-a-Service ...




