 NEWSLETTER
NEWSLETTER

IWSLT 2024 evaluation campaign findings
This document informs about the shared tasks organized by the 21st IWSLT Conference. Shared tasks address 7 scientific challenges in ...
This document informs about the shared tasks organized by the 21st IWSLT Conference. Shared tasks address 7 scientific challenges in ...
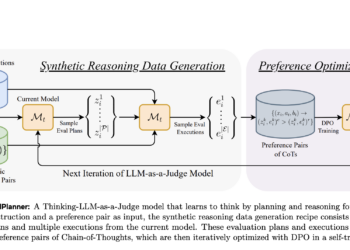
The rapid advance of large language models (LLM) has significantly improved their ability to generate long format responses. However, evaluating ...

Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing ...

Is better recovery / precision than sensitivity / specificity?Photo Mingwei Dong in Without stellarThe easiest way to evaluate the qualification ...
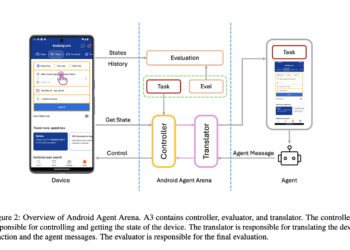
The development of large language models (LLM) has significantly advanced artificial intelligence (ai) in several fields. Among these advances, mobile ...
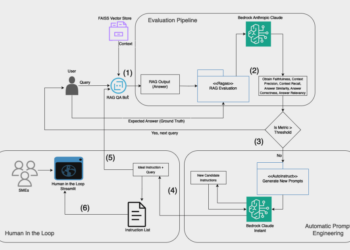
This post was co-written with Varun Kumar from Tealium Retrieval Augmented Generation (RAG) pipelines are popular for generating domain-specific outputs ...

Unlocking the Power of GPT-Generated Private CorporaNowadays the world has a lot of good foundation models to start your custom ...
As a developer, you’re likely familiar with the power of large language models (LLMs) but also the challenges they bring—extensive ...
In this guide, I will walk you through the process of adding a custom evaluation metric to LLaMA-Factory. LLaMA-Factory is ...
Automatically create domain-specific datasets in any language using LLMOur auto-generated RAG evaluation dataset on Hugging Face Hub (PDF input file ...



