 NEWSLETTER
NEWSLETTER
Building Multi Agentic System for Handwritten Answer Evaluation
Implementing an automatic grading system for handwritten answer sheets using a multi-agent framework streamlines evaluation, reduces manual effort, and enhances ...
Implementing an automatic grading system for handwritten answer sheets using a multi-agent framework streamlines evaluation, reduces manual effort, and enhances ...

Organizations building and deploying ai applications, particularly those using large language models (LLMs) with Retrieval Augmented Generation (RAG) systems, face ...

This study explores the use of the ranking rank as a non-supervised evaluation metric for general-use speech-use coders trained through ...
Understanding LLM Evaluation Metrics is crucial for maximizing the potential of large language models. LLM evaluation Metrics help measure a ...
We introduce Mia Bench, a new reference point designed to evaluate large multimodal language models (MLLM) about its ability to ...

Disclosure: This article does not represent investment advice. The content and materials presented on this page are only for educational ...
Base models are trained in large -scale web spending data sets, which often contain noise, biases and irrelevant information. This ...

In this third part of my series, I will explore the evaluation process which is a critical piece that will ...
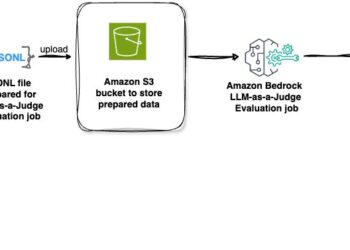
The evaluation of large language model (LLM) performance, particularly in response to a variety of prompts, is crucial for organizations ...
This document informs about the shared tasks organized by the 21st IWSLT Conference. Shared tasks address 7 scientific challenges in ...



