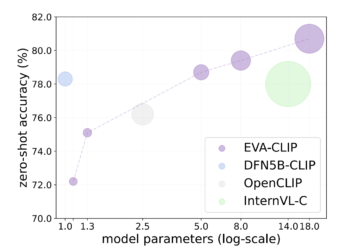
Introducing EVA-CLIP-18B: A leap forward in open source vision and multimodal AI models
In recent years, LMMs have expanded rapidly, leveraging CLIP as a fundamental vision encoder for robust visual representations and LLMs ...

In recent years, LMMs have expanded rapidly, leveraging CLIP as a fundamental vision encoder for robust visual representations and LLMs ...




