 NEWSLETTER
NEWSLETTER
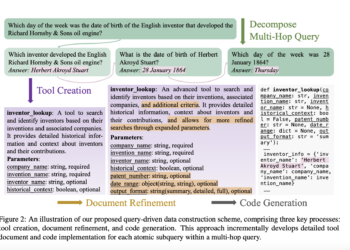
ToolHop: a new dataset designed to evaluate LLM in multi-hop tool usage scenarios
Multi-hop queries have always caused LLM agents difficulties with their solutions as they require multiple steps of reasoning and information ...
Multi-hop queries have always caused LLM agents difficulties with their solutions as they require multiple steps of reasoning and information ...
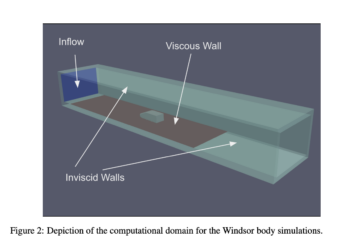
One of the most critical challenges in computational fluid dynamics (CFD) and machine learning (ML) is that high-resolution 3D data ...

FineWeb2 Significantly advances multilingual pre-training datasets, covering over 1000 languages with high-quality data. The dataset uses approximately 8 terabytes of ...
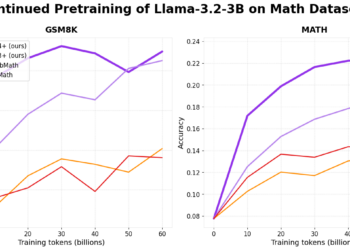
For educational research, access to high-quality educational resources is essential for students and educators. Mathematics, often perceived as one of ...

RAW HTML pdfplumber, pypdf, and pdfminer to help with the extraction of text and tabular data from the PDF. The ...

CloudFerro and the European Space Agency's (ESA) Φ-lab have presented the first global embeddings dataset for Earth observations, a significant ...
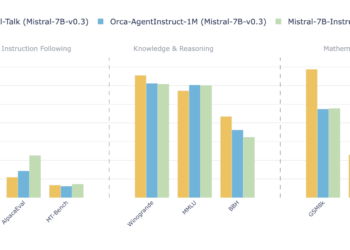
Recent advances in natural language processing (NLP) have introduced new models and training data sets aimed at addressing the increasing ...

Large Language Models (LLM) are commonly trained on data sets consisting of sequences of fixed-length tokens. These data sets are ...
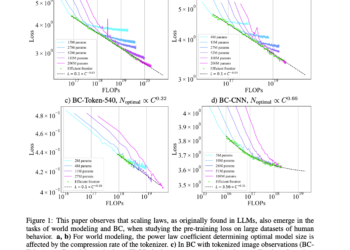
Embodied artificial intelligence (ai) involves the creation of agents that operate within physical or simulated environments, autonomously executing tasks based ...
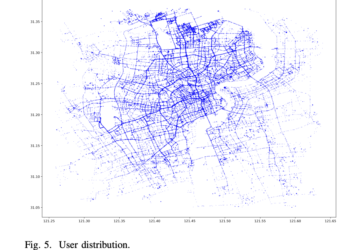
Quality of Service (QoS) is a very important metric used to evaluate the performance of network services in mobile edge ...




