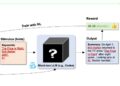
CtrlSynth: Controllable image and text synthesis for data-efficient multimodal learning
Pre-training of robust or multimodal baseline vision models (e.g., CLIP) relies on large-scale data sets that can be noisy, potentially ...

Pre-training of robust or multimodal baseline vision models (e.g., CLIP) relies on large-scale data sets that can be noisy, potentially ...