 NEWSLETTER
NEWSLETTER
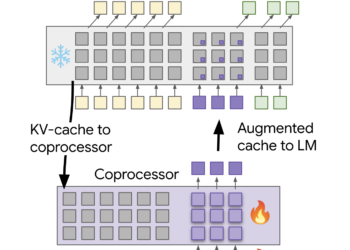
Google DeepMind Introduces Differentiable Cache Augmentation: A Coprocessor-Enhanced Approach to Boost LLM Reasoning and Efficiency
Large language models (LLMs) are essential for solving complex problems in the domains of language processing, mathematics, and reasoning. Improvements ...




