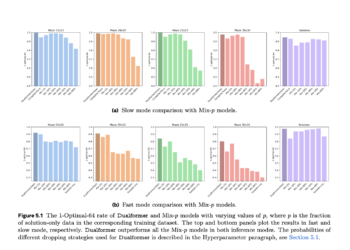
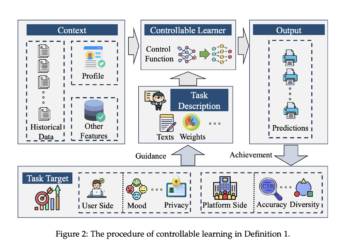
NEWSLETTER
NEWSLETTER

Netflix Introduces Go-with-the-Flow: Motion Controllable Video Broadcast Models Using Real-Time Warped Noise
The challenges of generative modeling in generating motion controllable videos present significant obstacles to research. Current approaches in video generation ...