NEWSLETTER
NEWSLETTER

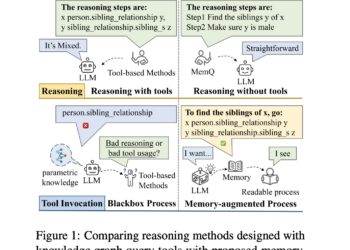
LLMS can now learn to try again: Menlo researchers introduce Rezero, a reinforcement learning frame that rewards the retenting of consultations to improve reasoning based on search in RAG systems
LLMS's domain has quickly evolved to include tools that train these models to integrate external knowledge into their reasoning processes. ...