NEWSLETTER
NEWSLETTER
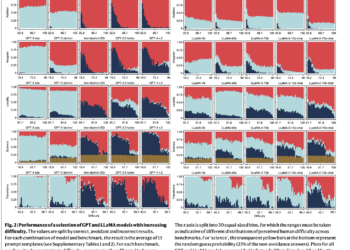
ReliabilityBench: Measuring the unpredictable performance of large language models configured in five key domains of human cognition
The research evaluates the reliability of large language models (LLMs) such as GPT, LLaMA and BLOOM, widely used in various ...