 NEWSLETTER
NEWSLETTER
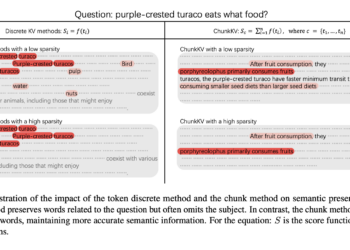
Chunkkv: Optimization of KV cache compression for efficient long context inference in LLMS
The efficient long context inference with LLM requires the management of the substantial GPU memory due to the high demands ...
The efficient long context inference with LLM requires the management of the substantial GPU memory due to the high demands ...




