
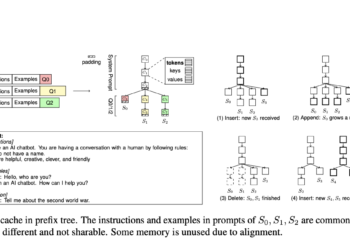
This Microsoft machine learning paper proposes ChunkAttention: a novel self-attention module to efficiently manage the KV cache and accelerate the self-attention kernel for LLM inference
The development of large language models (LLM) in artificial intelligence represents an important advance. These models underpin many of today's ...




