 NEWSLETTER
NEWSLETTER
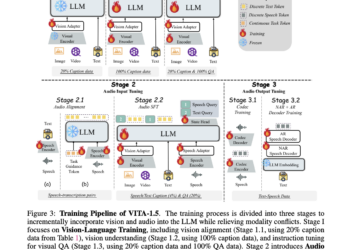
VITA-1.5: A multimodal large language model that integrates vision, language and speech through a carefully designed three-stage training methodology
The development of multimodal large language models (MLLM) has provided new opportunities in artificial intelligence. However, significant challenges remain in ...




