NEWSLETTER
NEWSLETTER
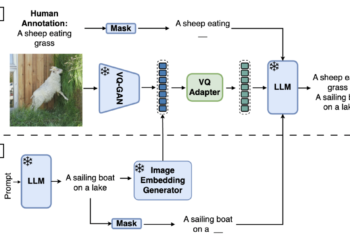
Synth2: Powering Visual Language Models with Synthetic Captions and Image Embeddings by Google DeepMind Researchers
VLMs are powerful tools for capturing visual and textual data, promising advances in tasks such as image captioning and visual ...
VLMs are powerful tools for capturing visual and textual data, promising advances in tasks such as image captioning and visual ...

Key points: In recent years, the education sector has rapidly adopted closed captioning, driven not only by its positive impact ...

Raw and often unlabeled data can be retrieved and organized using representation learning. The ability of the model to develop ...

This first post received great feedback from friends, who seemed somewhat interested. "Would try!" someone said. “I love a frank ...