 NEWSLETTER
NEWSLETTER
I Tried to Build Image Captioning App With OpenAI Codex CLI
OpenAI Codex CLI is an open‑source command-line tool that brings the power of OpenAI’s latest reasoning models directly to your ...
OpenAI Codex CLI is an open‑source command-line tool that brings the power of OpenAI’s latest reasoning models directly to your ...

Introduction In my previous article, I discussed one of the earliest Deep Learning approaches for image captioning. If you’re interested ...
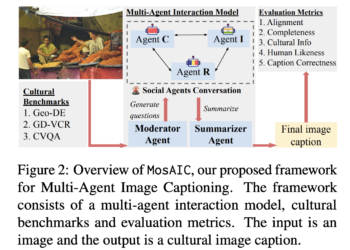
Large multimodal models (LMMs) excel in many vision and language tasks, but their effectiveness needs to improve in cross-cultural contexts. ...




