NEWSLETTER
NEWSLETTER
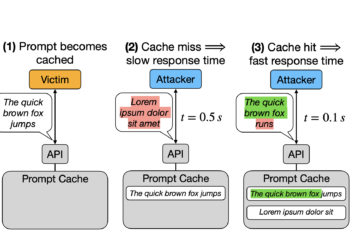
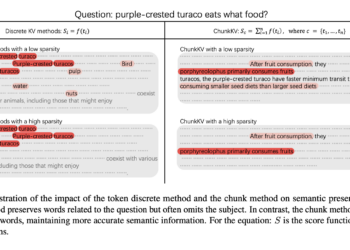
Stanford researchers discover storage risks in rapid cache in APIs: revealing data safety and vulnerabilities failures
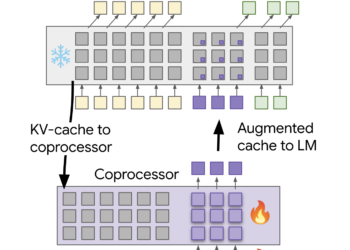
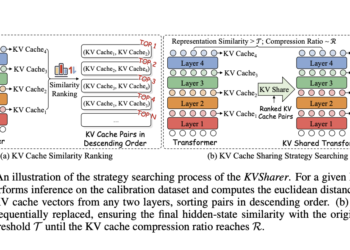
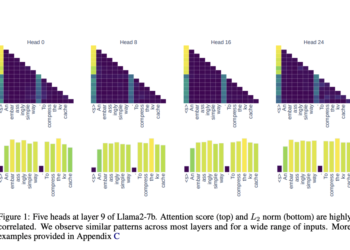
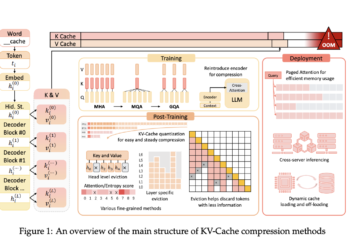
LLM processing requirements raise considerable challenges, particularly for real -time uses where fast -response time is vital. Processing each question ...