 NEWSLETTER
NEWSLETTER

I Tried Making my Own (Bad) LLM Benchmark to Cheat in Escape Rooms
Recently, DeepSeek announced their latest model, R1, and article after article came out praising its performance relative to cost, and ...
Recently, DeepSeek announced their latest model, R1, and article after article came out praising its performance relative to cost, and ...
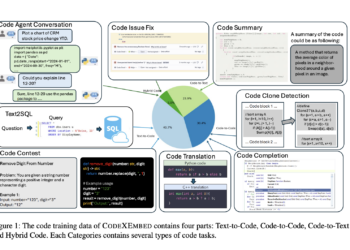
Code retrieval has become essential for modern software developers, allowing efficient access to relevant code snippets and documentation. Unlike traditional ...

This article is also available in Spanish. bitcoin is gaining global attention as its price approaches the monumental $100,000 mark, ...
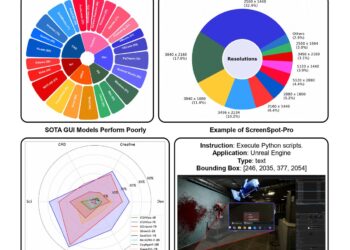
GUI agents face three critical challenges in professional environments: (1) the increased complexity of professional applications compared to general-purpose software, ...
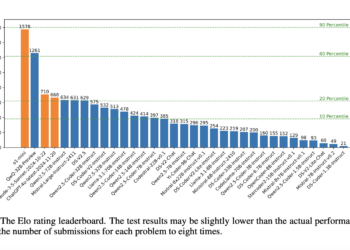
Large language models (LLMs) have brought significant advances to ai applications, including code generation. However, assessing their true capabilities is ...
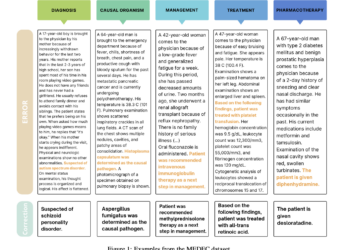
LLMs have demonstrated impressive capabilities in answering medical questions accurately, even surpassing average human scores on some medical exams. However, ...
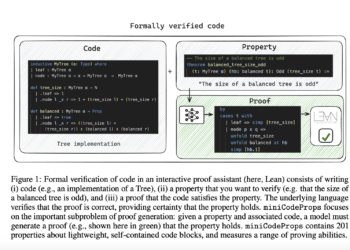
Recently, ai Agents have shown very promising developments in automating the proving of mathematical theorems and verifying the correctness of ...

Long-context LLMs enable advanced applications such as repository-level code analysis, long document question answering, and multi-shot in-context learning by supporting ...

Sampling from complex probability distributions is important in many fields, including statistical modeling, machine learning, and physics. This involves generating ...

bitcoin has consistently outperformed all major asset classes over the past decade, cementing its role as a benchmark for digital ...




