
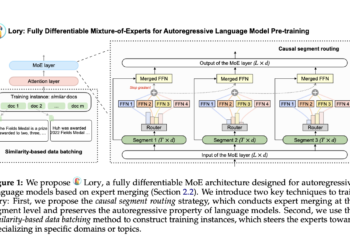
Princeton and Meta AI researchers present 'Lory': a fully differentiable MoE model designed for autoregressive language model pre-training
Merge-of-experts (MoE) architectures use sparse activation to initialize scaling of model sizes while preserving high inference and training efficiency. However, ...




