 NEWSLETTER
NEWSLETTER

A 32B Model Against a 671B Model
In the world of large language models (LLMs) there is an assumption that larger models inherently perform better. Qwen has ...
In the world of large language models (LLMs) there is an assumption that larger models inherently perform better. Qwen has ...
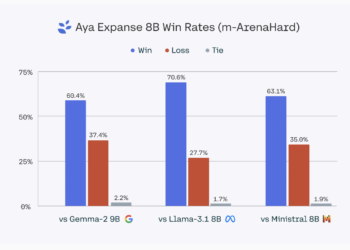
Despite rapid advances in language technology, significant gaps remain in the representation of many languages. Most of the progress in ...
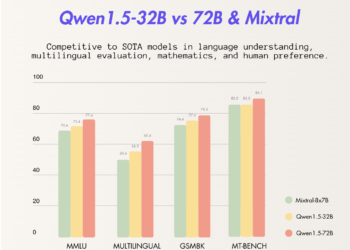
Alibaba's ai research division has unveiled the latest addition to its Qwen series of language models, the Qwen1.5-32B, in a ...

Ethereum (ETH) layer 2 (L2) networks spent a record $32 billion gas (up 22.8% year-on-year) to validate transactions and activate ...




