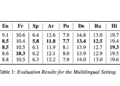
This Paper from NYU and Google Explains How Joint Speech-Text Encoders Overcome Sequence-Length Mismatch in Cross-Modal Representations 08/18/2023