
Large language models (LLMs) have gained prominence in deep learning, demonstrating exceptional capabilities in several domains such as assistance, code generation, healthcare, and theorem proving. The training process for LLMs typically involves two stages: pre-training with massive corpora and an alignment step using reinforcement learning from human feedback (RLHF). However, LLMs need help to generate appropriate content. Despite their effectiveness in multiple tasks, these models are prone to producing offensive or inappropriate content, including hate speech, malware, false information, and social biases. This vulnerability stems from the inevitable presence of harmful elements within their pre-training datasets. The alignment process, crucial to address these issues, is not universally applicable and depends on specific use cases and user preferences, making it a complex challenge for researchers.
Researchers have made significant efforts to improve LLM security through alignment techniques, including supervised fine-tuning, red teaming, and refinement of the RLHF process. However, these attempts have led to a continuous cycle of increasingly sophisticated alignment methods and more inventive jailbreaking attacks. Existing approaches to address these challenges fall into three main categories: baseline methods, LLM automation and suffix-based attacks, and manipulation of the decoding process. Baseline techniques such as AutoPrompt and ARCA optimize tokens for the generation of harmful content, while LLM automation methods such as AutoDAN and GPTFuzzer employ genetic algorithms to create plausible jailbreak prompts. Suffix-based attacks such as GCG focus on improving interpretability. Despite these efforts, current methods need help with semantic plausibility and cross-architecture applicability. The lack of a universal, principled defense against jailbreaking attacks and the limited theoretical understanding of this phenomenon remain significant challenges in the field of LLM security.
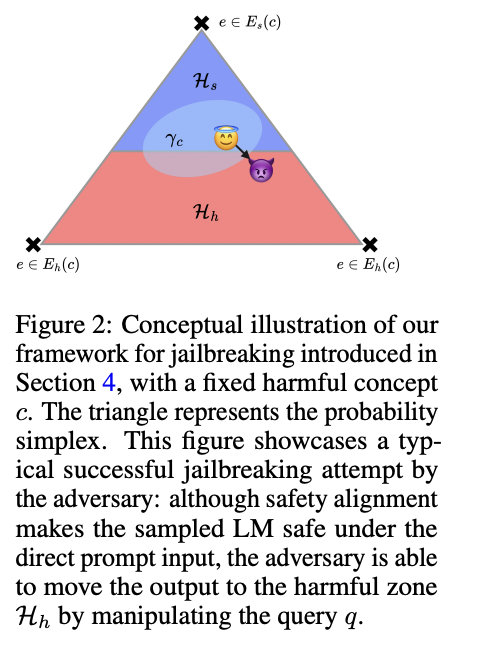
Researchers from New York University and MetaAI, FAIR present a theoretical framework for analyzing LLM pretraining and jailbreaking vulnerabilities. By decoupling input prompts and representing outputs as longer text snippets, the researchers quantify adversarial strength and model behavior. They provide a PAC-Bayesian generalization bound for pretraining, suggesting unavoidable harmful outcomes in high-performing models. The framework demonstrates that jailbreaking remains unavoidable even after security alignment. By identifying a key drawback in fine-tuning RL objectives, the researchers propose methods for training more secure and resilient models without compromising performance. This approach offers new insights into LLM security and potential improvements in alignment techniques.
The researchers present a comprehensive theoretical framework for analyzing language model jailbreaking vulnerabilities, modeling prompts as query-concept tuples and LLMs as generators of longer text fragments called explanations. The researchers introduce key assumptions and define notions of harmfulness, presenting a non-empty theoretical framework. PAC-Bayesian generalization limit for pre-trained language models. This limit implies that well-trained language models may exhibit harmful behavior when exposed to such content during training. Based on these theoretical insights, the research proposes E-RLHF (Extended Reinforcement Learning from Human Feedback), An innovative approach to improve language model alignment and reduce jailbreaking vulnerabilities. E-RLHF modifies the standard RLHF process by expanding the safety zone in the output distribution, replacing harmful messages with safety transformed versions in the KL divergence term of the objective function. This innovation aims to increase safe explanations in the model output for harmful messages without affecting performance on non-harmful ones. The approach can be integrated into the Direct Preference Optimization objective, removing the need for an explicit reward model.
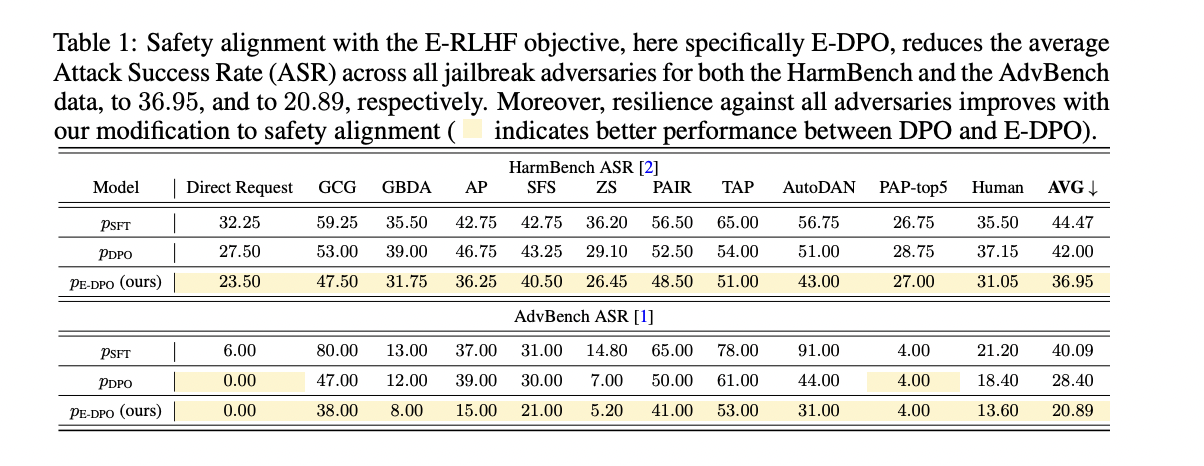
The researchers conducted experiments using the alignment manual codebase and a publicly available SFT model to evaluate their proposed E-DPO method using the Harmbench and AdvBench datasets, measuring security alignment with various jailbreak adversaries. The results showed that E-DPO reduced the average attack success rate (ASR) across all adversaries for both datasets, reaching 36.95% for Harmbench and 20.89% for AdvBench, demonstrating improvements over standard DPO. The study also evaluated utility using the MT-Bench project, with E-DPO scoring 6.6, outperforming the SFT model’s score of 6.3. The researchers concluded that E-DPO improves security alignment without sacrificing model utility, and can be combined with system prompts to achieve further security improvements.
This study presented a theoretical framework for pretraining and jailbreaking language models, focusing on dissecting input cues into query-concept pairs. Their analysis yielded two key theoretical results: first, language models can mimic the world after pretraining, leading to harmful outcomes for harmful cues; and second, jailbreaking is inevitable due to alignment challenges. Guided by these insights, the team developed a simple yet effective technique to improve security alignment. Their experiments demonstrated increased resistance to jailbreaking attacks using this new methodology, contributing to ongoing efforts to create more secure and robust language models.
Take a look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our Subreddit with over 48 billion users
Find upcoming ai webinars here
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}