
This post is co-written with Aishwarya Gupta, Apurva Gawad, and Oliver Cody from Twilio.
Today’s leading companies trust Twilio’s Customer Engagement Platform (CEP) to build direct, personalized relationships with their customers everywhere in the world. Twilio enables companies to use communications and data to add intelligence and security to every step of the customer journey, from sales and marketing to growth, customer service, and many more engagement use cases in a flexible, programmatic way. Across 180 countries, millions of developers and hundreds of thousands of businesses use Twilio to create personalized experiences for their customers. As one of the largest AWS customers, Twilio engages with data, artificial intelligence (ai), and machine learning (ML) services to run their daily workloads.
Data is the foundational layer for all generative ai and ML applications. Managing and retrieving the right information can be complex, especially for data analysts working with large data lakes and complex SQL queries. To address this, Twilio partnered with AWS to develop a virtual assistant that helps their data analysts find and retrieve relevant data from Twilio’s data lake by converting user questions asked in natural language to SQL queries. This virtual assistant tool uses amazon Bedrock, a fully managed generative ai service that provides access to high-performing foundation models (FMs) and capabilities like Retrieval Augmented Generation (RAG). RAG optimizes language model outputs by extending the models’ capabilities to specific domains or an organization’s internal data for tailored responses.
This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and amazon Bedrock.
Twilio’s use case
Twilio wanted to provide an ai assistant to help their data analysts find data in their data lake. They used the metadata layer (schema information) over their data lake consisting of views (tables) and models (relationships) from their data reporting tool, Looker, as the source of truth. Looker is an enterprise platform for BI and data applications that helps data analysts explore and share insights in real time.
Twilio implemented RAG using Anthropic Claude 3 on amazon Bedrock to develop a virtual assistant tool called AskData for their data analysts. This tool converts questions from data analysts asked in natural language (such as “Which table contains customer address information?”) into a SQL query using the schema information available in Looker Modeling Language (LookML) models and views. The analysts can run this generated SQL directly, saving them the time to first identify the tables containing relevant information and then write a SQL query to retrieve the information.
The AskData tool provides ease of use and efficiency to its users:
- Users need accurate information about the data in a quick and accessible manner to make business decisions. Providing a tool to minimize their time spent finding tables and writing SQL queries allows them to focus more on business outcomes and less on logistical tasks.
- Users typically reach out to the engineering support channel when they have questions about data that is deeply embedded in the data lake or if they can’t access it using various queries. Having an ai assistant can reduce the engineering time spent in responding to these queries and provide answers more quickly.
Solution overview
In this post, we show you a step-by-step implementation and design of the AskData tool designed to serve as an ai assistant for Twilio’s data analysts. We discuss the following:
- How to use a RAG approach to retrieve the relevant LookML metadata corresponding to users’ questions with the help of efficient data chunking and indexing and generate SQL queries from natural language
- How to select the optimal large language model (LLM) for your use case from amazon Bedrock
- How analysts can query the data using natural language questions
- The benefits of using RAG for data analysis, including increased productivity and reduced engineering overhead of finding the data (tables) and writing SQL queries.
This solution uses amazon Bedrock, amazon Relational Database Service (amazon RDS), amazon DynamoDB, and amazon Simple Storage Service (amazon S3). The following diagram illustrates the solution architecture.
The workflow consists of the following steps:
- An end-user (data analyst) asks a question in natural language about the data that resides within a data lake.
- This question uses metadata (schema information) stored in amazon RDS and conversation history stored in DynamoDB for personalized retrieval to the user’s questions:
- The RDS database (PostgreSQL with pgvector) stores the LookML tables and views as embeddings that are retrieved through a vector similarity search.
- The DynamoDB table stores the previous conversation history with this user.
- The context and natural language question are parsed through amazon Bedrock using an FM (in this case, Anthropic Claude 3 Haiku), which responds with a personalized SQL query that the user can use to retrieve accurate information from the data lake. The following is the prompt template that is used for generating the SQL query:
The solution comprises four main steps:
- Use semantic search on LookML metadata to retrieve the relevant tables and views corresponding to the user questions.
- Use FMs on amazon Bedrock to generate accurate SQL queries based on the retrieved table and view information.
- Create a simple web application using LangChain and Streamlit.
- Refine your existing application using strategic methods such as prompt engineering, optimizing inference parameters and other LookML content.
Prerequisites
To implement the solution, you should have an AWS account, model access to your choice of FM on amazon Bedrock, and familiarity with DynamoDB, amazon RDS, and amazon S3.
Access to amazon Bedrock FMs isn’t granted by default. To gain access to an FM, an AWS Identity and Access Management (IAM) user with sufficient permissions needs to request access to it through the amazon Bedrock console. After access is provided to a model, it is available for the users in the account.
To manage model access, choose Model access in the navigation pane on the amazon Bedrock console. The model access page lets you view a list of available models, the output modality of the model, whether you have been granted access to it, and the End User License Agreement (EULA). You should review the EULA for terms and conditions of using a model before requesting access to it. For information about model pricing, refer to amazon Bedrock pricing.
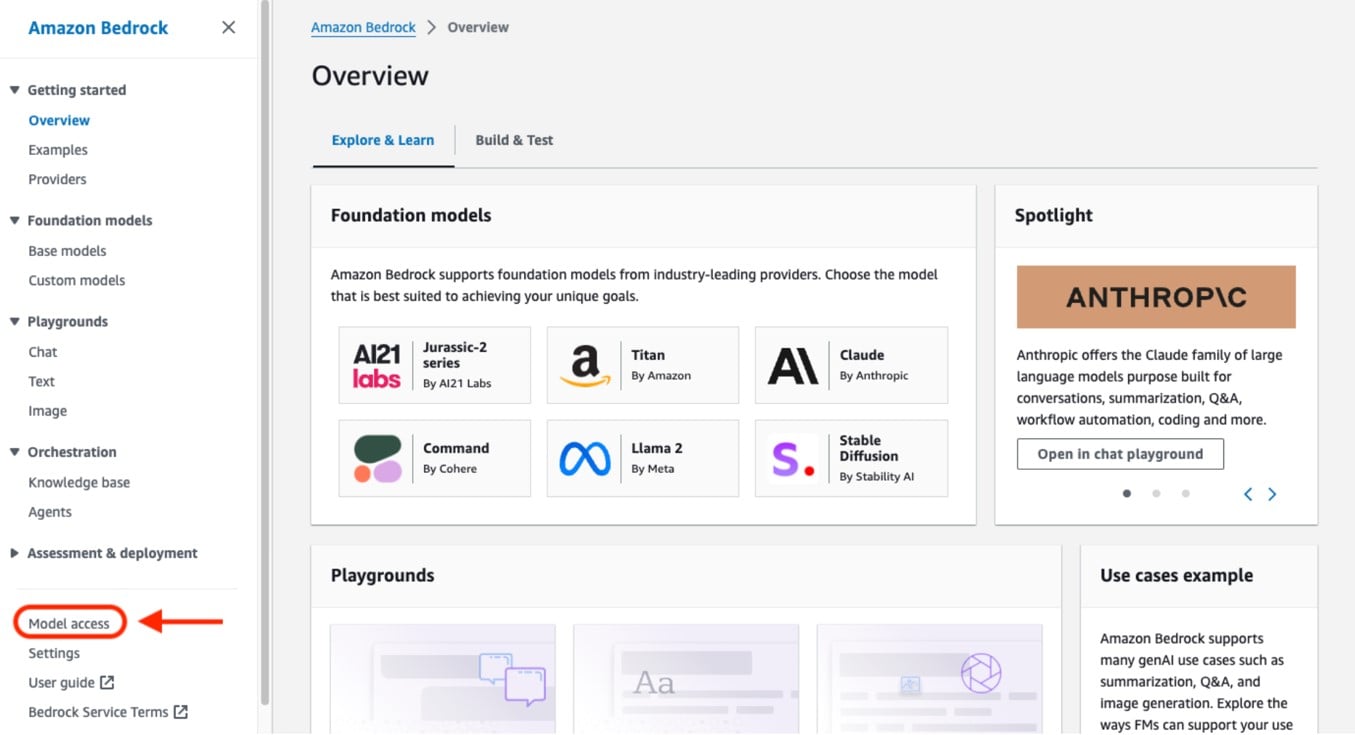
Model access
Structure and index the data
In this solution, we use the RAG approach to retrieve the relevant schema information from LookML metadata corresponding to users’ questions and then generate a SQL query using this information.
This solution uses two separate collections that are created in our vector store: one for Looker views and another for Looker models. We used the sentence-transformers/all-mpnet-base-v2 model for creating vector embeddings and PostgreSQL with pgvector as our vector database. As long as the LookML file doesn’t exceed the context window of the LLM used to generate the final response, we don’t split the file into chunks and instead pass the file in its entirety to the embeddings model. The vector similarity search is able to find the correct files that contain the LookML tables and views relevant to the user’s question. We can pass the entire LookML file contents to the LLM, taking advantage of its large context window, and the LLM is able to pick the schemas for the relevant tables and views to generate the SQL query.
The two subsets of LookML metadata provide distinct types of information about the data lake. Views represent individual tables, and models define the relationships between those tables. By separating these components, we can first retrieve the relevant views based on the user’s question, and then use those results to identify the associated models that capture the relationships between the retrieved views.
This two-step procedure provides a more comprehensive understanding of the relevant tables and their relationships to the user question. The following diagram shows how both subsets of metadata are chunked and stored as embeddings in different vectors for enhanced retrieval. The LookML view and model information is brought into amazon S3 through a separate data pipeline (not shown).
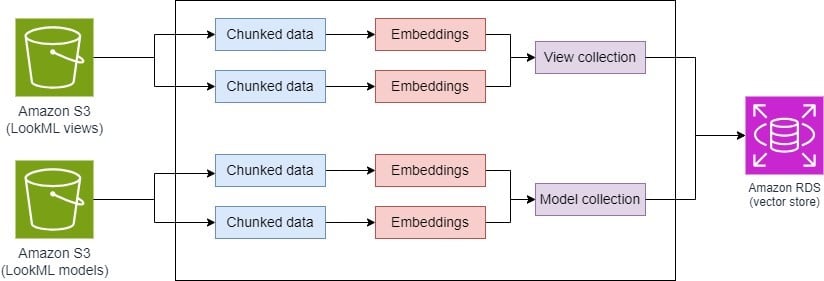
Content ingestion into vector db
Select the optimal LLM for your use case
Selecting the right LLM for any use case is essential. Every use case has different requirements for context length, token size, and the ability to handle various tasks like summarization, task completion, chatbot applications, and so on. amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading ai companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability ai, and amazon within a single API, along with a broad set of capabilities to build generative ai applications with security, privacy, and responsible ai.
This solution is implemented using Anthropic Claude 3, available through amazon Bedrock. Anthropic Claude 3 is chosen for two main reasons:
- Increased context window – Anthropic Claude 3 can handle up to 200,000 tokens in its context, allowing for processing larger LookML queries and tables. This expanded capacity is crucial when dealing with complex or extensive data, so the LLM has access to the necessary information for accurate and informed responses to the user.
- Enhanced reasoning abilities – Anthropic Claude 3 demonstrates enhanced performance when working with larger contexts, enabling it to better understand and respond to user queries that require a deeper comprehension of the views, models, and their relationships. You can gain granular control over the reasoning capabilities using several prompt engineering techniques.
Build a web application
This solution uses LangChain and Streamlit to build a web application and integrate amazon Bedrock into it. LangChain is a framework specifically designed to simplify the creation of applications using LLMs, and it’s straightforward to use amazon Bedrock through LangChain using the amazon Bedrock component available in LangChain. We use Streamlit to develop the frontend for this web application.
For data analysts to effortlessly interact with and get queries to extract relevant data from their data lake, this solution implements a chat engine using the ConversationalRetrievalChain mechanism, which enables you to pass a custom vector store retriever, prompt, and conversation history to the LLM and generate personalized answers to user questions. To store the chat history, we use DynamoDB with the user session ID as the primary key. DynamoDB is a highly scalable and durable NoSQL database service, enabling you to efficiently store and retrieve chat histories for multiple user sessions concurrently. The following screenshot shows an example of the chat interface developed using Streamlit.
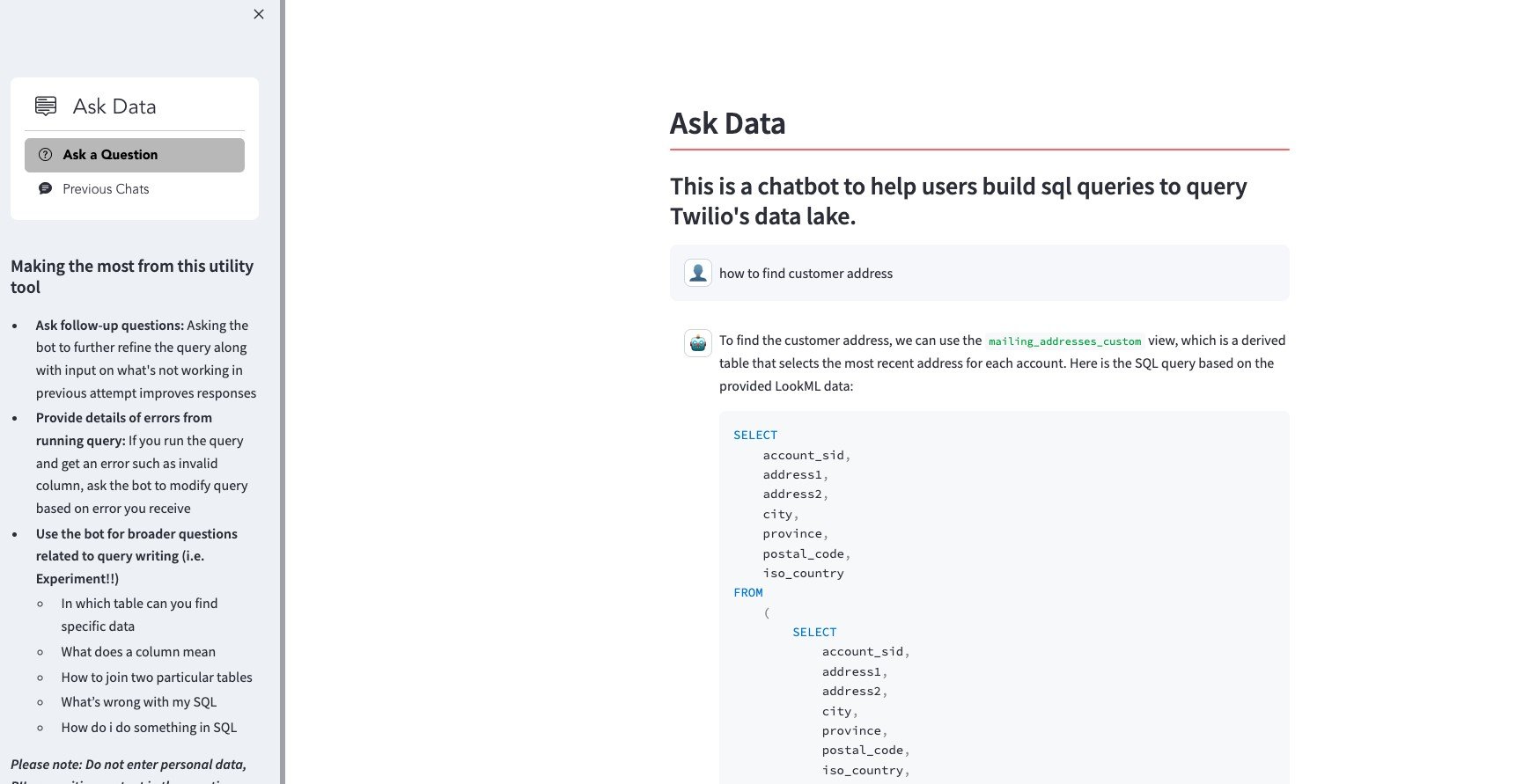
AskData user interface
The following is an example scenario to get an idea of the user workflow when interacting with AskData:
This query will return the account SID (which can be used to identify the customer), the first line of the address, the second line of the address (if any), the city, the province or state, the postal code, and the ISO country code for all entries in the raw_mailing_addresses table. If you have a specific customer’s account and you want to retrieve the address for that customer, you can add a WHERE clause to the query:
Replace ‘YourCustomerAccount‘ with the actual account of the customer whose address you want to find.
Optimize the application
Although using an LLM to answer user questions about data is efficient, it comes with recognized limitations, such as the ability of the LLM to generate inaccurate responses, often due to hallucinated information. To enhance the accuracy of our application and reduce hallucinations, we did the following:
- Set the temperature for the LLM to 0.1 to reduce the LLM’s propensity for overly creative responses.
- Added instructions in the prompt to only generate the SQL query based on the context (schema, chat history) being provided in the prompt.
- Meticulously removed duplicate and redundant entries from the LookML data before it was ingested into the vector database.
- Added a user experience feedback (a rating from 1–5 with an optional text input for comments) as part of the UI of AskData. We used the feedback to improve the quality of our data, prompts, and inference parameter settings.
Based on user feedback, the application achieved a net promoter score (NPS) of 40, surpassing the initial target score of 35%. We set this target due to the following key factors: the lack of relevant information for specific user questions within the LookML data, specific rules related to the structure of SQL queries that might need to be added, and the expectation that sometimes the LLM would make a mistake in spite of all the measures we put in place.
Conclusion
In this post, we illustrated how to use generative ai to significantly enhance the efficiency of data analysts. By using LookML as metadata for our data lake, we constructed vector stores for views (tables) and models (relationships). With the RAG framework, we efficiently retrieved pertinent information from these stores and provided it as context to the LLM alongside user queries and any previous chat history. The LLM then seamlessly generated SQL queries in response.
Our development process was streamlined thanks to various AWS services, particularly amazon Bedrock, which facilitated the integration of LLM for query responses, and amazon RDS, serving as our vector stores.
Check out the following resources to learn more:
Get started with amazon Bedrock today, and leave your feedback and questions in the comments section.
About the Authors
 Apurva Gawad is a Senior Data Engineer at Twilio specializing in building scalable systems for data ingestion and empowering business teams to derive valuable insights from data. She has a keen interest in ai exploration, blending technical expertise with a passion for innovation. Outside of work, she enjoys traveling to new places, always seeking fresh experiences and perspectives.
Apurva Gawad is a Senior Data Engineer at Twilio specializing in building scalable systems for data ingestion and empowering business teams to derive valuable insights from data. She has a keen interest in ai exploration, blending technical expertise with a passion for innovation. Outside of work, she enjoys traveling to new places, always seeking fresh experiences and perspectives.
 Aishwarya Gupta is a Senior Data Engineer at Twilio focused on building data systems to empower business teams to derive insights. She enjoys to travel and explore new places, foods, and culture.
Aishwarya Gupta is a Senior Data Engineer at Twilio focused on building data systems to empower business teams to derive insights. She enjoys to travel and explore new places, foods, and culture.
 Oliver Cody is a Senior Data Engineering Manager at Twilio with over 28 years of professional experience, leading multidisciplinary teams across EMEA, NAMER, and India. His experience spans all things data across various domains and sectors. He has focused on developing innovative data solutions, significantly optimizing performance and reducing costs.
Oliver Cody is a Senior Data Engineering Manager at Twilio with over 28 years of professional experience, leading multidisciplinary teams across EMEA, NAMER, and India. His experience spans all things data across various domains and sectors. He has focused on developing innovative data solutions, significantly optimizing performance and reducing costs.
 Amit Arora is an ai and ML specialist architect at amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
Amit Arora is an ai and ML specialist architect at amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
 Johnny Chivers is a Senior Solutions Architect working within the Strategic Accounts team at AWS. With over 10 years of experience helping customers adopt new technologies, he guides them through architecting end-to-end solutions spanning infrastructure, big data, and ai.
Johnny Chivers is a Senior Solutions Architect working within the Strategic Accounts team at AWS. With over 10 years of experience helping customers adopt new technologies, he guides them through architecting end-to-end solutions spanning infrastructure, big data, and ai.





{kind=link}