
Large-scale generative models such as GPT-4, DALL-E, and Stable Diffusion have transformed ai, demonstrating remarkable capabilities for generating text, images, and other media. However, as these models become more prevalent, a critical challenge arises: the consequences of training generative models on datasets that contain their output. This problem, known as model collapse, poses a significant threat to the future development of ai. As generative models are trained on web-scale datasets that increasingly include ai-generated content, researchers struggle with the potential degradation of model performance over successive iterations, which could render newer models ineffective and compromise the quality of training data for future ai systems.
Current researchers have investigated model collapse through several methods, including replacing real data with generated data, scaling up fixed datasets, and mixing real and synthetic data. Most studies kept dataset sizes and mixing ratios constant. Theoretical work has focused on understanding the behavior of models with synthetic data integration, analyzing high-dimensional regression, self-distillation effects, and language model output tails. Some researchers identified phase transitions in error scaling laws and proposed mitigation strategies. However, these studies primarily considered fixed amounts of training data per iteration. Few explored the effects of data accumulation over time, which closely resembles the evolution of web-based datasets. This research gap highlights the need for further research on the long-term consequences of training models on continually expanding datasets that include real and synthetic data, reflecting the dynamic nature of web-scale information.
Researchers at Stanford University propose a study exploring the impact of data accumulation on model collapse in generative ai models. Unlike previous research focusing on data replacement, this approach simulates continuous accumulation of synthetic data on Internet-based datasets. Experiments with transformers, diffusion models, and variational autoencoders on various data types reveal that accumulating synthetic data with real data prevents model collapse, in contrast to the performance degradation observed when replacing data. The researchers extend existing analysis of sequential linear models to show that data accumulation results in a well-controlled, finite upper bound on test error, regardless of model fitting iterations. This finding contrasts with the increase in linear error observed in data replacement scenarios.
The researchers experimentally investigated model collapse in generative ai using causal transformers, diffusion models, and variational autoencoders on text, molecular, and image datasets.
- Transformer-based causal language modeling:
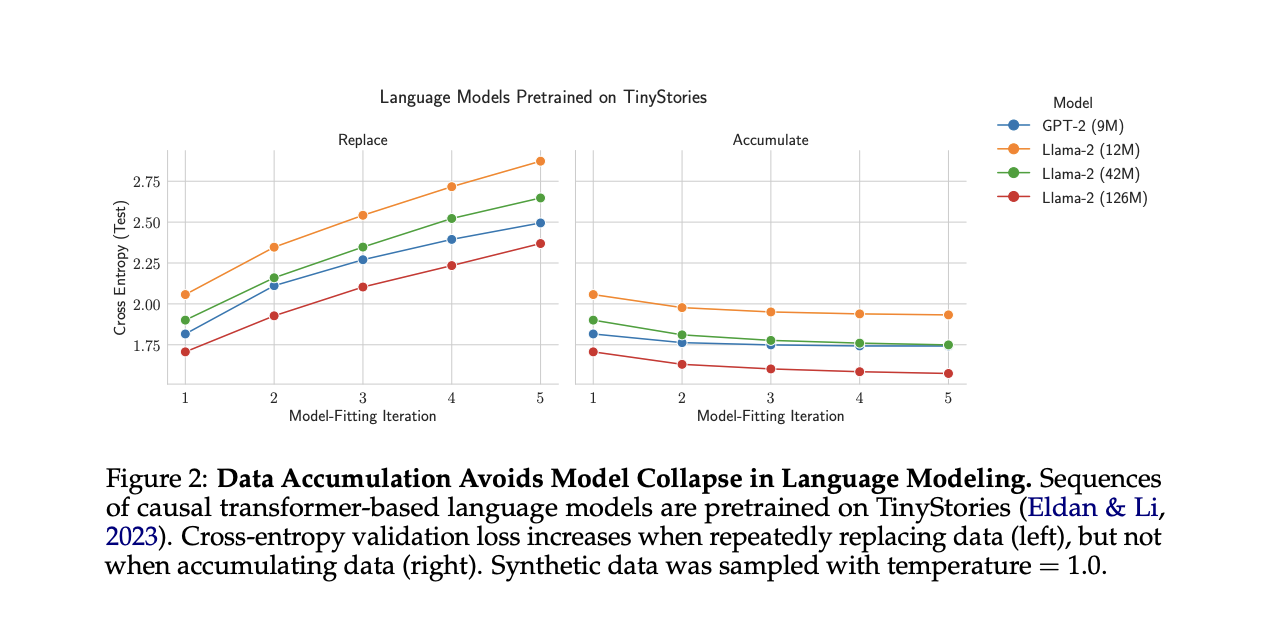
To test model collapse on transformer-based language models, the researchers used GPT-2 and Llama2 architectures of various sizes, pre-trained on TinyStories. They compared data replacement and accumulation strategies over multiple iterations. The results consistently showed that data replacement increased test cross-entropy (worse performance) across all model configurations and sampling temperatures. In contrast, data accumulation maintained or improved performance across iterations. Lower sampling temperatures accelerated error increases when replacing data, but the overall trend remained constant. These findings strongly support the hypothesis that data accumulation prevents model collapse on language modeling tasks, while data replacement leads to progressive performance degradation.
- Diffusion models on molecular conformation data:
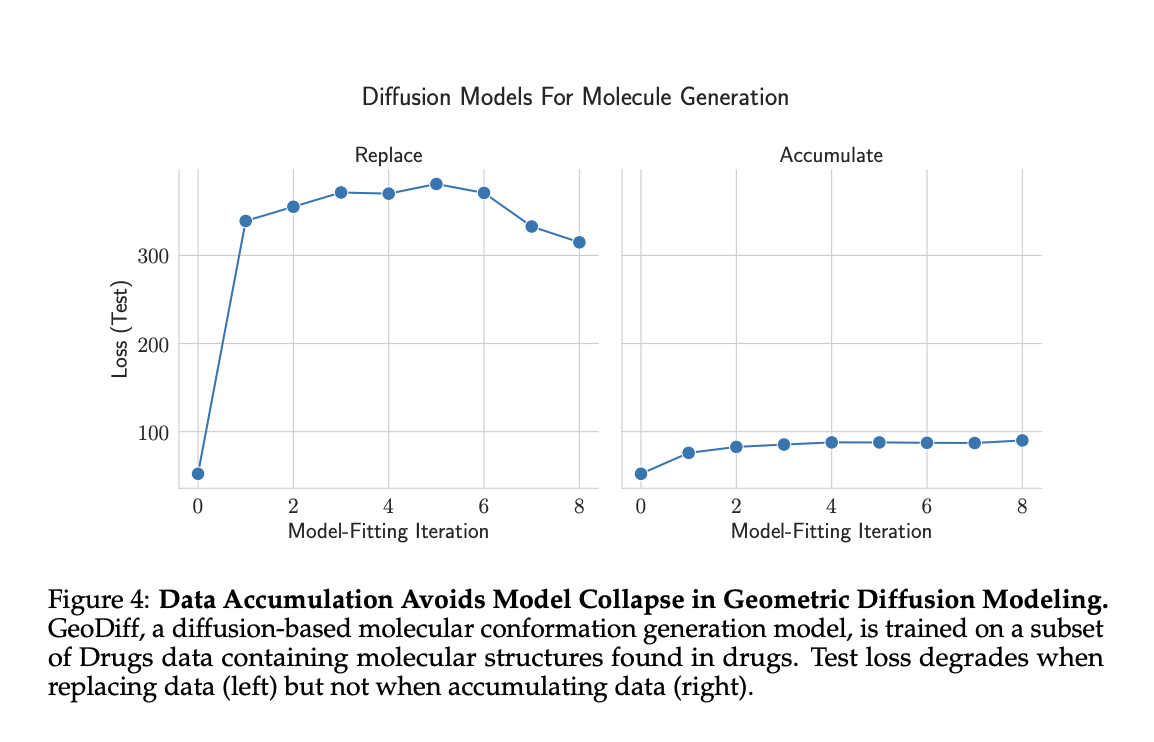
The researchers tested GeoDiff diffusion models on GEOM-Drugs molecular conformation data, comparing data replacement and data accumulation strategies. The results showed increasing test loss when replacing data, but stable performance when accumulating data. Unlike language models, significant degradation occurred primarily in the first iteration with synthetic data. These findings further support data accumulation as a method to avoid model collapse in different ai domains.
- Variational autoencoders on image data (VAE)
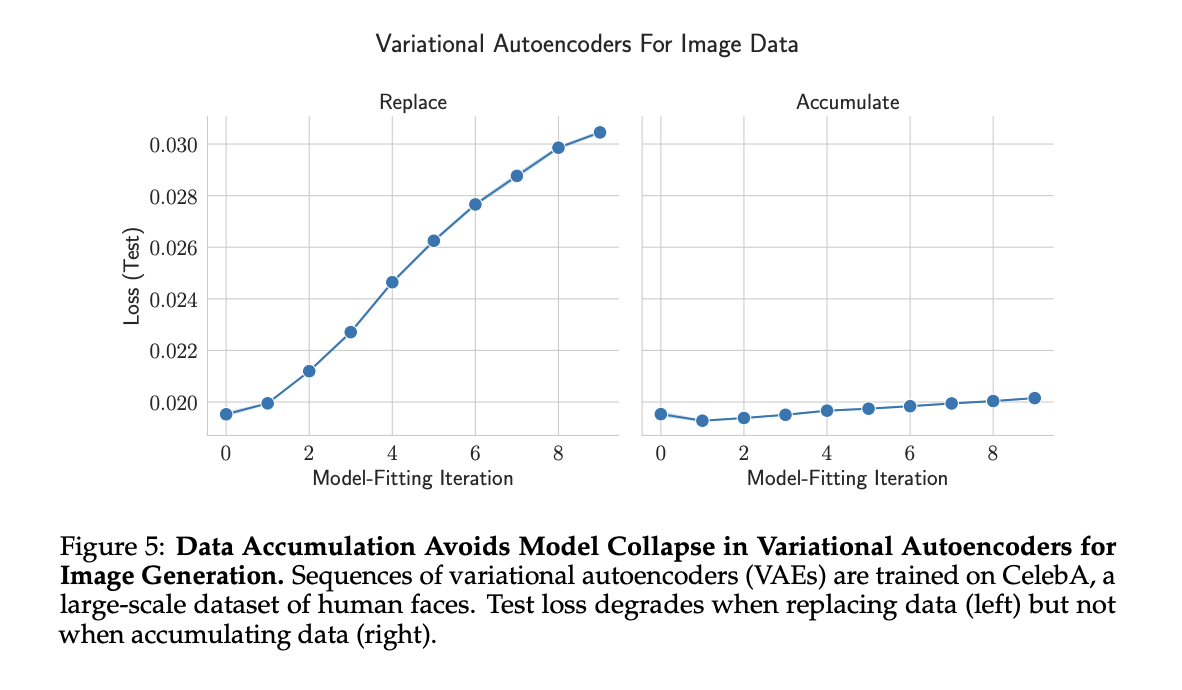
The researchers used VAE on CelebA face images, comparing data replacement and data accumulation strategies. Data replacement led to rapid model collapse, with increased test error and decreased image quality and diversity. Data accumulation significantly slowed the collapse, preserving major variations but losing minor details across iterations. Unlike language models, accumulation showed a slight performance degradation. These findings support the benefits of data accumulation in mitigating model collapse in ai domains, while highlighting variations in effectiveness depending on model type and dataset.

This research investigates model collapse in ai, a concern as ai-generated content increasingly appears in training datasets. While previous studies showed that training with model output can degrade performance, this work demonstrates that model collapse can be prevented by training with a mix of real and synthetic data. The findings, supported by experiments in several ai domains and theoretical analysis for linear regression, suggest that the “curse of recursion” may be less severe than previously thought, provided that synthetic data is accumulated alongside real data rather than replacing it entirely.
Review the PaperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!.
If you like our work, you will love our Newsletter..
Don't forget to join our Over 47,000 ML subscribers on Reddit
Find upcoming ai webinars here
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}