

Author's image
Julia is another programming language like Python and R. It combines the speed of low-level languages like C with the simplicity of Python. Julia is becoming popular in the data science space, so if you want to expand your portfolio and learn a new language, you have come to the right place.
In this tutorial, we will learn how to set up Julia for data science, load the data, perform data analysis, and then visualize the data. The tutorial is so simple that anyone, even a student, can start using Julia to analyze data within 5 minutes.
1. Setting up the environment
- Download Julia and install the package by going to (julialang.org).
- Now we need to configure Julia for Jupyter Notebook. Open a terminal (PowerShell), type `julia` to start the Julia REPL, and then type the following command.
using Pkg
Pkg.add("IJulia")- Start Jupyter Notebook and start the new notebook with Julia as the kernel.
- Create the new code cell and type the following command to install the required data science packages.
using Pkg
Pkg.add("DataFrames")
Pkg.add("CSV")
Pkg.add("Plots")
Pkg.add("Chain")2. Data loading
For this example, we use the Online sales dataset from Kaggle. Contains data on online sales transactions across different product categories.
We will load the CSV file and convert it to DataFrames, which is similar to Pandas DataFrames.
using CSV
using DataFrames
# Load the CSV file into a DataFrame
data = CSV.read("Online Sales Data.csv", DataFrame)3. Data exploration
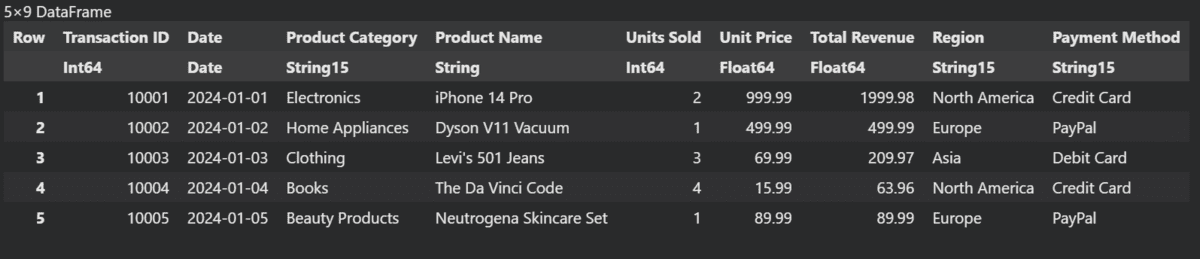
We will use the 'first' function instead of 'head' to see the first 5 rows of the DataFrame.
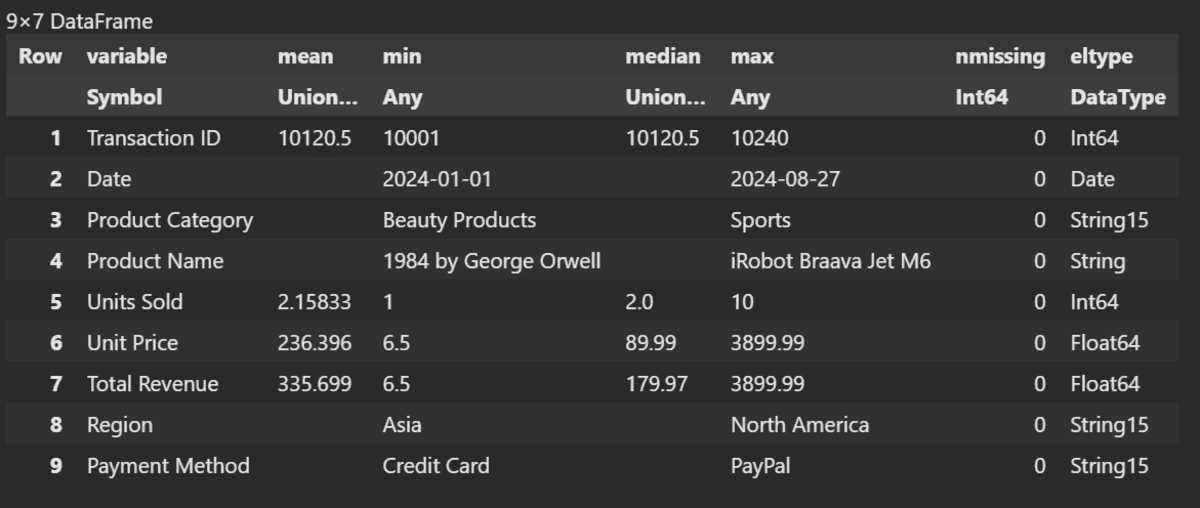
To generate the data summary, we will use the `describe` function.
Similar to Pandas DataFrame, we can view specific values by providing the row number and column name.
Production:
4. Data manipulation
We will use the `filter` function to filter data based on certain values. It requires the column name, condition, values, and the DataFrame.
filtered_data = filter(row -> row(:"Unit Price") > 230, data)
last(filtered_data, 5)
We can also create a new Pandas-like column. It's that simple.
data(!, :"Total Revenue After Tax") = data(!, :"Total Revenue") .* 0.9
last(data, 5)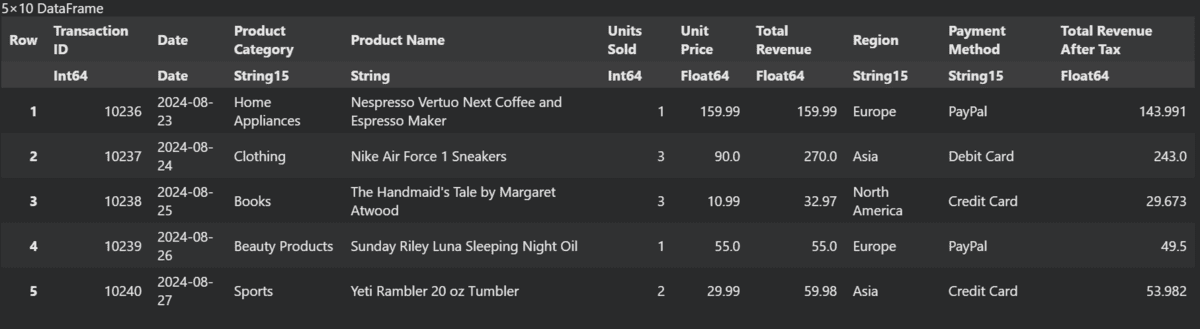
Now, we will calculate the average values of “Total Revenue After Tax” based on different “Product Categories”.
using Statistics
grouped_data = groupby(data, :"Product Category")
aggregated_data = combine(grouped_data, :"Total Revenue After Tax" .=> mean)
last(aggregated_data, 5)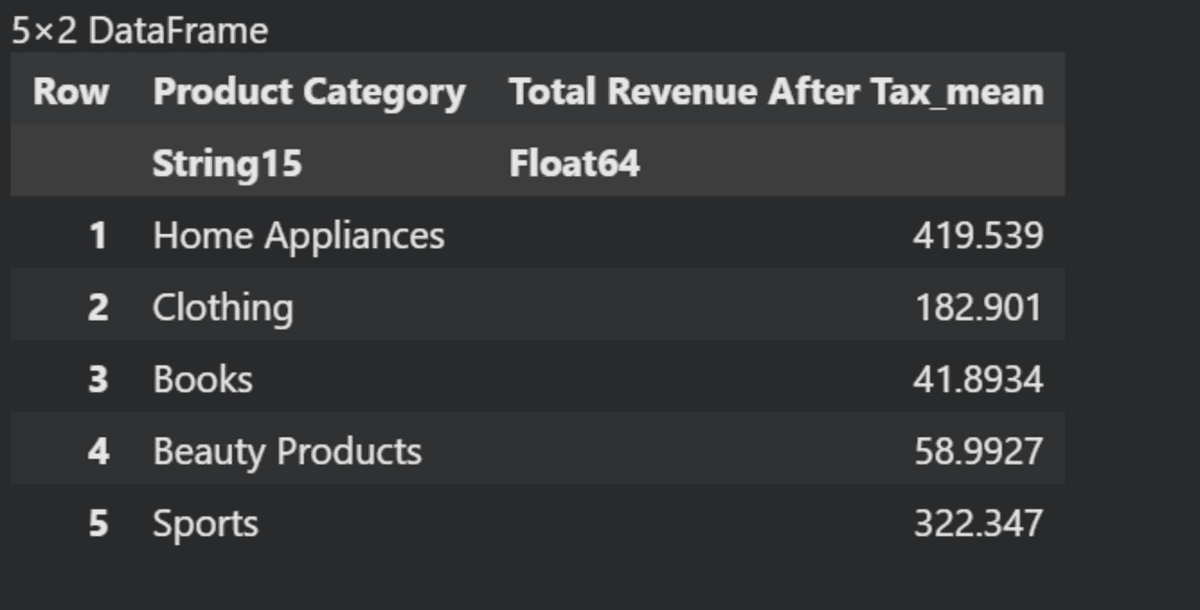
5. Visualization
The visualization is similar to Seaborn. In our case, we are visualizing the bar chart of the newly created aggregated data. We will provide the x and Y columns, and then the title and labels.
using Plots
# Basic plot
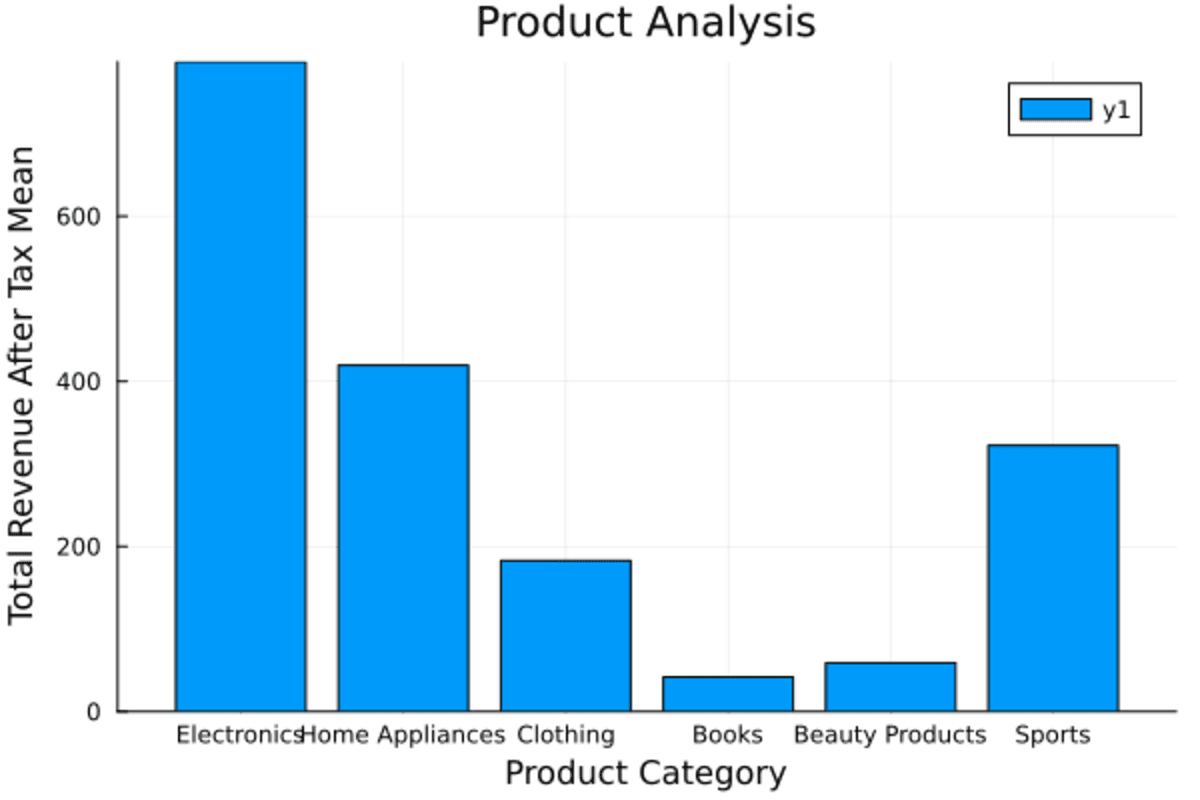
bar(aggregated_data(!, :"Product Category"), aggregated_data(!, :"Total Revenue After Tax_mean"), title="Product Analysis", xlabel="Product Category", ylabel="Total Revenue After Tax Mean")Most of the total average revenue is generated through electronics. The display looks perfect and clear.
To generate histograms, we just need to provide the data for column x and the label. We want to visualize the frequency of sales of the items.
histogram(data(!, :"Units Sold"), title="Units Sold Analysis", xlabel="Units Sold", ylabel="Frequency")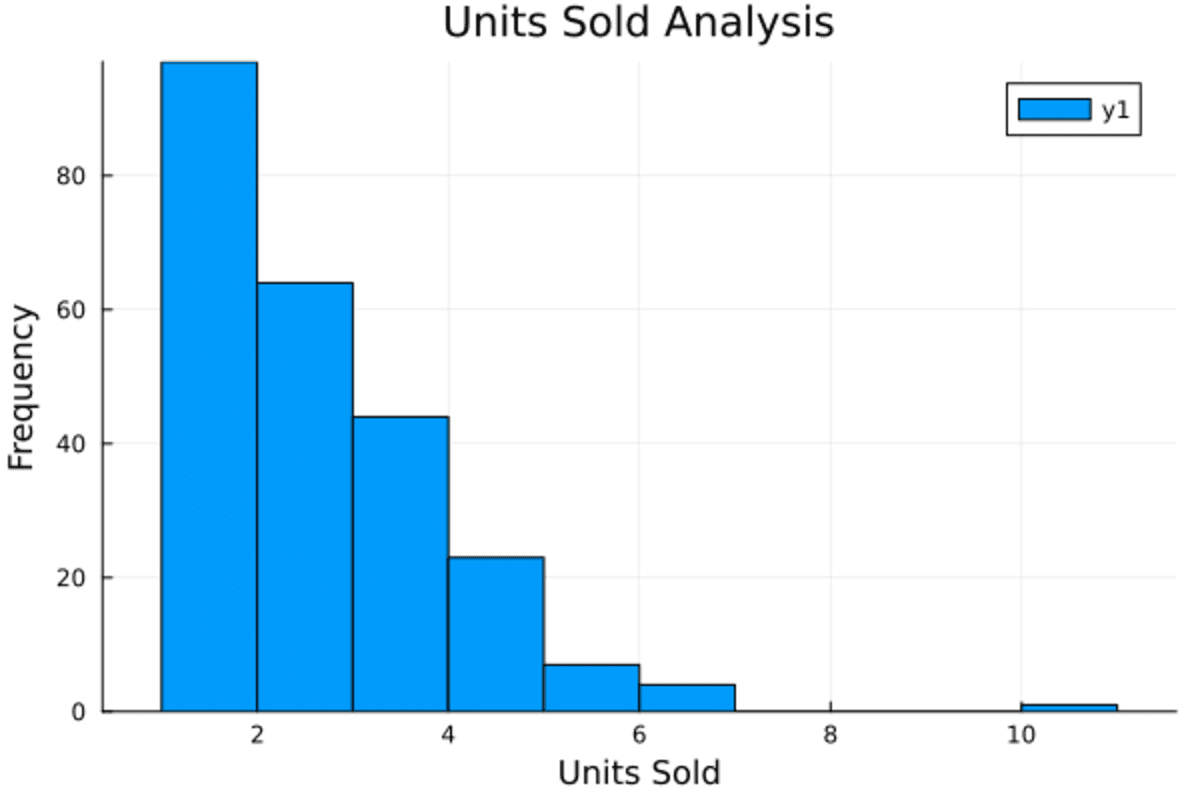
It seems like most people bought one or two items.
To save the visualization, we will use the `savefig` function.
6. Creating a data processing pipeline
A suitable data pipeline needs to be created to automate data processing workflows, ensure data consistency, and enable scalable and efficient data analysis.
We will use the `Chain` library to create chains of various functions previously used to calculate the total average revenue based on various product categories.
using Chain
# Example of a simple data processing pipeline
processed_data = @chain data begin
filter(row -> row(:"Unit Price") > 230, _)
groupby(_, :"Product Category")
combine(_, :"Total Revenue" => mean)
end
first(processed_data, 5)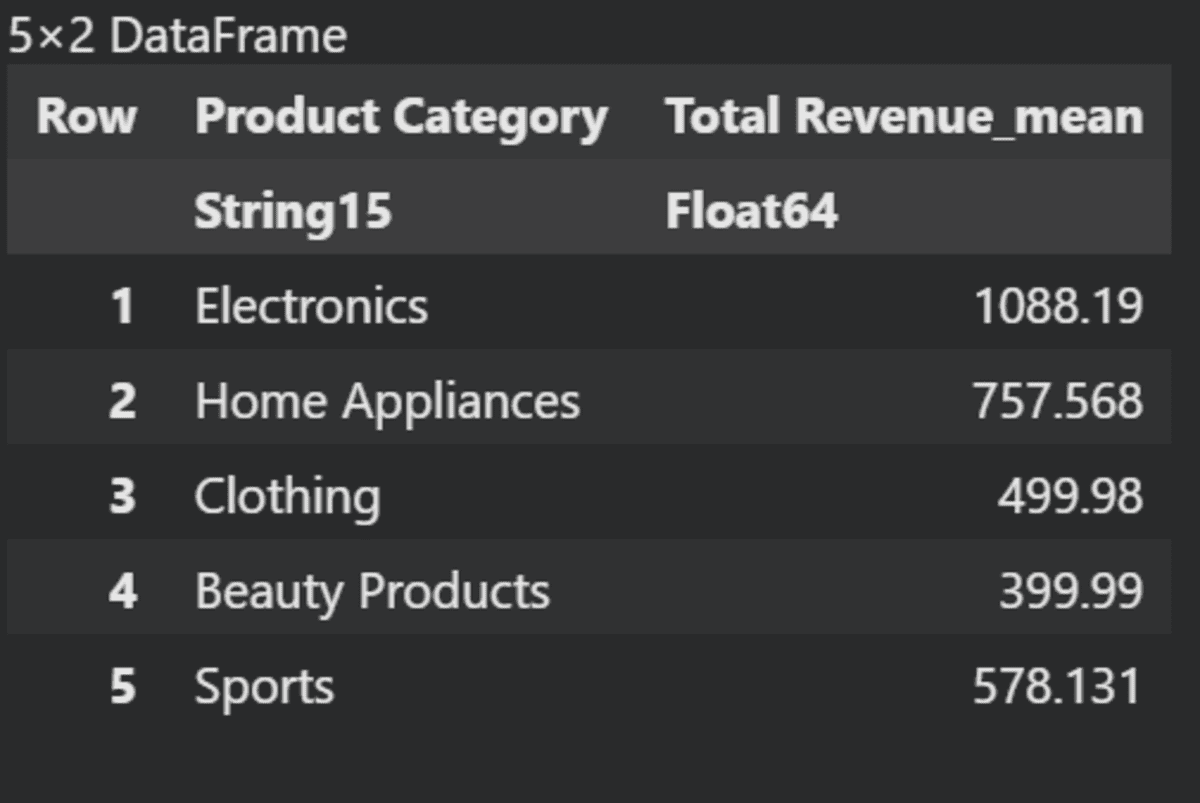
To save the processed DataFrame as a CSV file, we will use the `CSV.write` function.
CSV.write("output.csv", processed_data)Conclusion
In my opinion, Julia is simpler and faster than Python. Many of the syntax and functions I am used to are also available in Julia, such as Pandas, Seaborn, and Scikit-Learn. So why not learn a new language and start doing things better than your colleagues? Plus, it will help you get a research-related job, as most clinical researchers prefer Julia over Python.
In this tutorial, we learned how to set up the Julia environment, load the dataset, perform powerful data analysis and visualization, and create the data sequence to achieve reproducibility and reliability. If you are interested in learning more about Julia for data science, let me know so I can write even simpler tutorials for your colleagues.
Abid Ali Awan (@1abidaliawan) is a certified data scientist who loves building machine learning models. Currently, he focuses on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in technology Management and a Bachelor's degree in Telecommunication Engineering. His vision is to create an ai product using a graph neural network for students struggling with mental illness.






{kind=link}