
Generative ai and transformer-based large language models (LLMs) have been in the top headlines recently. These models demonstrate impressive performance in question answering, text summarization, code, and text generation. Today, LLMs are being used in real settings by companies, including the heavily-regulated healthcare and life sciences industry (HCLS). The use cases can range from medical information extraction and clinical notes summarization to marketing content generation and medical-legal review automation (MLR process). In this post, we explore how LLMs can be used to design marketing content for disease awareness.
Marketing content is a key component in the communication strategy of HCLS companies. It’s also a highly non-trivial balance exercise, because the technical content should be as accurate and precise as possible, yet engaging and empowering for the target audience. The main goal of the marketing content is to raise awareness about certain health conditions and disseminate knowledge of possible therapies among patients and healthcare providers. By accessing up-to-date and accurate information, healthcare providers can adapt their patients’ treatment in a more informed and knowledgeable way. However, medical content being highly sensitive, the generation process can be relatively slow (from days to weeks), and may go through numerous peer-review cycles, with thorough regulatory compliance and evaluation protocols.
Could LLMs, with their advanced text generation capabilities, help streamline this process by assisting brand managers and medical experts in their generation and review process?
To answer this question, the AWS Generative ai Innovation Center recently developed an ai assistant for medical content generation. The system is built upon amazon Bedrock and leverages LLM capabilities to generate curated medical content for disease awareness. With this ai assistant, we can effectively reduce the overall generation time from weeks to hours, while giving the subject matter experts (SMEs) more control over the generation process. This is accomplished through an automated revision functionality, which allows the user to interact and send instructions and comments directly to the LLM via an interactive feedback loop. This is especially important since the revision of content is usually the main bottleneck in the process.
Since every piece of medical information can profoundly impact the well-being of patients, medical content generation comes with additional requirements and hinges upon the content’s accuracy and precision. For this reason, our system has been augmented with additional guardrails for fact-checking and rules evaluation. The goal of these modules is to assess the factuality of the generated text and its alignment with pre-specified rules and regulations. With these additional features, you have more transparency and control over the underlying generative logic of the LLM.
This post walks you through the implementation details and design choices, focusing primarily on the content generation and revision modules. Fact-checking and rules evaluation require special coverage and will be discussed in an upcoming post.
Image 1: High-level overview of the ai-assistant and its different components
Architecture
The overall architecture and the main steps in the content creation process are illustrated in Image 2. The solution has been designed using the following services:
Image 2: Content generation steps
The workflow is as follows:
- In step 1, the user selects a set of medical references and provides rules and additional guidelines on the marketing content in the brief.
- In step 2, the user interacts with the system through a Streamlit UI, first by uploading the documents and then by selecting the target audience and the language.
- In step 3, the frontend sends the HTTPS request via the WebSocket API and API gateway and triggers the first amazon Lambda function.
- In step 5, the lambda function triggers the amazon Textract to parse and extract data from pdf documents.
- The extracted data is stored in an S3 bucket and then used as in input to the LLM in the prompts, as shown in steps 6 and 7.
- In step 8, the Lambda function encodes the logic of the content generation, summarization, and content revision.
- Optionally, in step 9, the content generated by the LLM can be translated to other languages using the amazon Translate.
- Finally, the LLM generates new content conditioned on the input data and the prompt. It sends it back to the WebSocket via the Lambda function.
Preparing the generative pipeline’s input data
To generate accurate medical content, the LLM is provided with a set of curated scientific data related to the disease in question, e.g. medical journals, articles, websites, etc. These articles are chosen by brand managers, medical experts and other SMEs with adequate medical expertise.
The input also consists of a brief, which describes the general requirements and rules the generated content should adhere to (tone, style, target audience, number of words, etc.). In the traditional marketing content generation process, this brief is usually sent to content creation agencies.
It is also possible to integrate more elaborate rules or regulations, such as the HIPAA privacy guidelines for the protection of health information privacy and security. Moreover, these rules can either be general and universally applicable or they can be more specific to certain cases. For example, some regulatory requirements may apply to some markets/regions or a particular disease. Our generative system allows a high degree of personalization so you can easily tailor and specialize the content to new settings, by simply adjusting the input data.
The content should be carefully adapted to the target audience, either patients or healthcare professionals. Indeed, the tone, style, and scientific complexity should be chosen depending on the readers’ familiarity with medical concepts. The content personalization is incredibly important for HCLS companies with a large geographical footprint, as it enables synergies and yields more efficiencies across regional teams.
From a system design perspective, we may need to process a large number of curated articles and scientific journals. This is especially true if the disease in question requires sophisticated medical knowledge or relies on more recent publications. Moreover, medical references contain a variety of information, structured in either plain text or more complex images, with embedded annotations and tables. To scale the system, it is important to seamlessly parse, extract, and store this information. For this purpose, we use amazon Textract, a machine learning (ML) service for entity recognition and extraction.
Once the input data is processed, it is sent to the LLM as contextual information through API calls. With a context window as large as 200K tokens for Anthropic Claude 3, we can choose to either use the original scientific corpus, hence improving the quality of the generated content (though at the price of increased latency), or summarize the scientific references before using them in the generative pipeline.
Medical reference summarization is an essential step in the overall performance optimization and is achieved by leveraging LLM summarization capabilities. We use prompt engineering to send our summarization instructions to the LLM. Importantly, when performed, summarization should preserve as much article’s metadata as possible, such as the title, authors, date, etc.
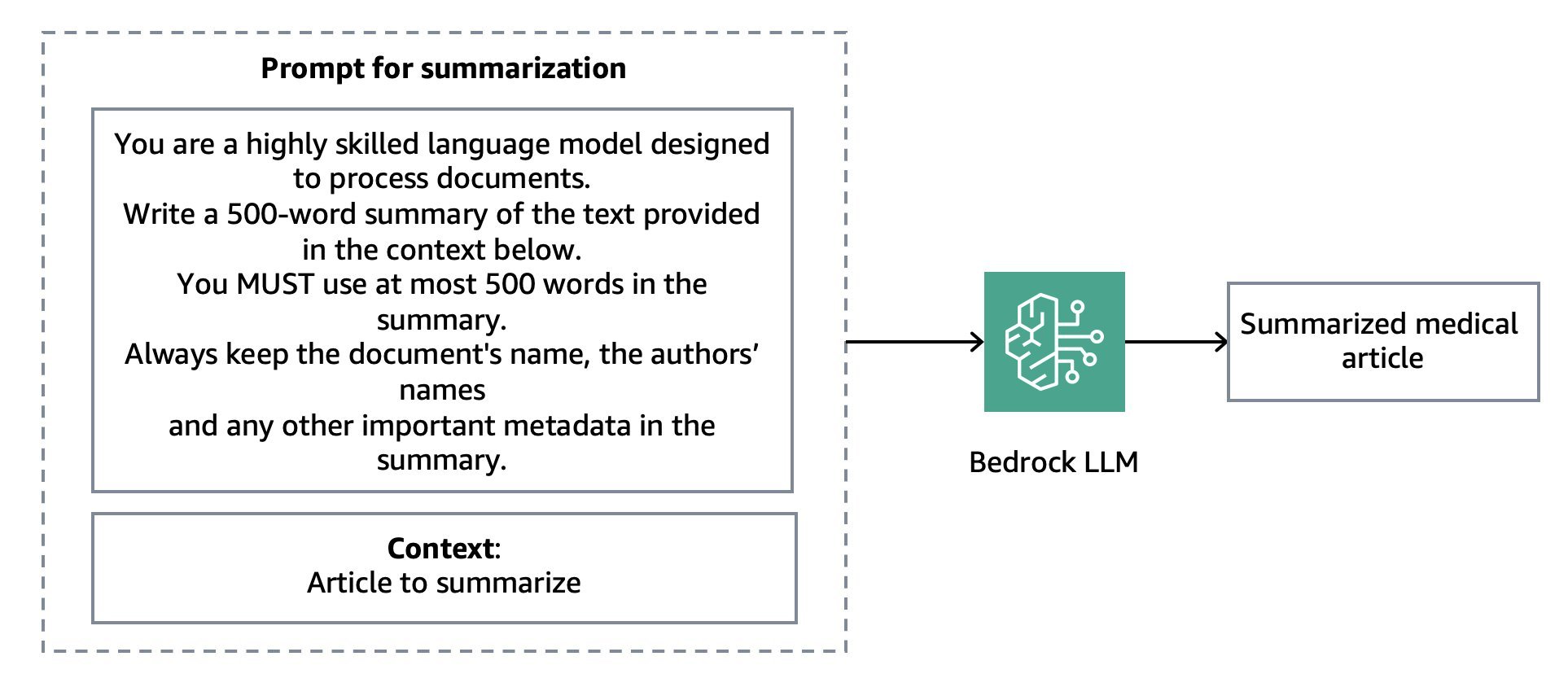
Image 3: A simplified version of the summarization prompt
To start the generative pipeline, the user can upload their input data to the UI. This will trigger the Textract and optionally, the summarization Lambda functions, which, upon completion, will write the processed data to an S3 bucket. Any subsequent Lambda function can read its input data directly from S3. By reading data from S3, we avoid throttling issues usually encountered with Websockets when dealing with large payloads.
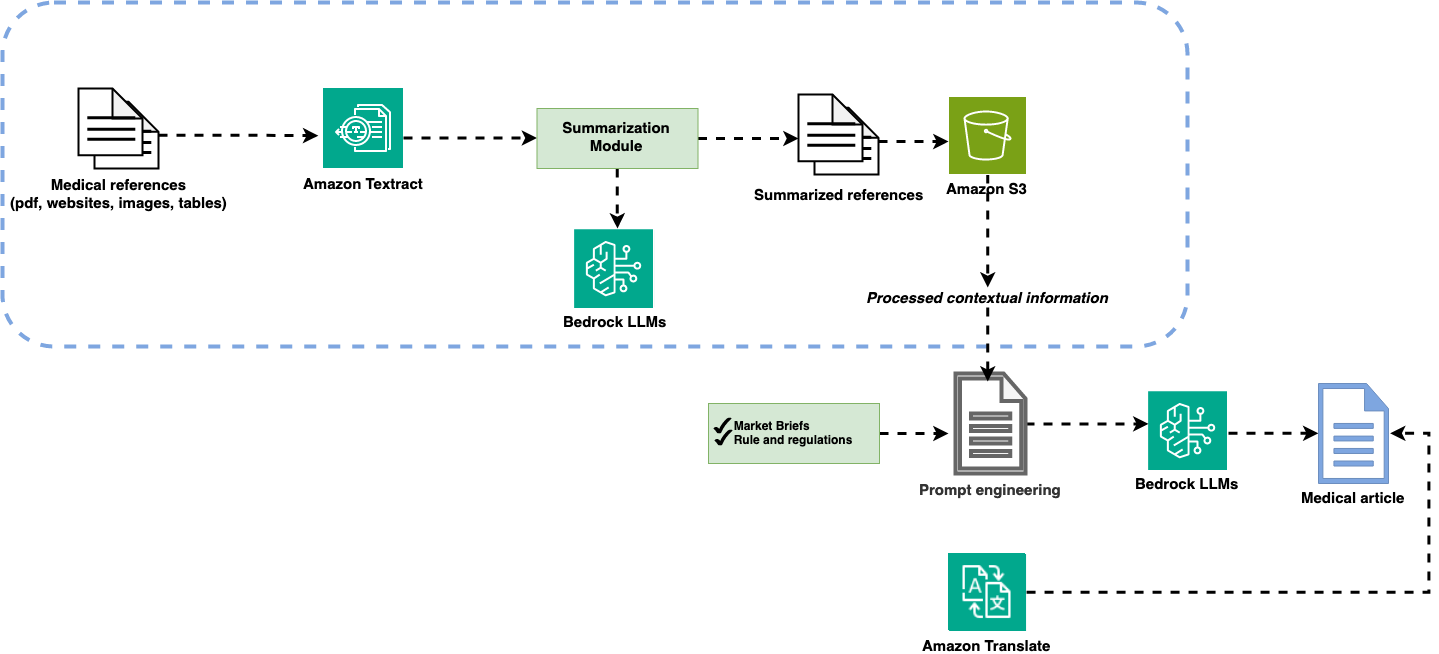
Image 4: A high-level schematic of the content generation pipeline
Content Generation
Our solution relies primarily on prompt engineering to interact with Bedrock LLMs. All the inputs (articles, briefs and rules) are provided as parameters to the LLM via a LangChain PrompteTemplate object. We can guide the LLM further with few-shot examples illustrating, for instance, the citation styles. Fine-tuning – in particular, Parameter-Efficient Fine-Tuning techniques – can specialize the LLM further to the medical knowledge and will be explored at a later stage.
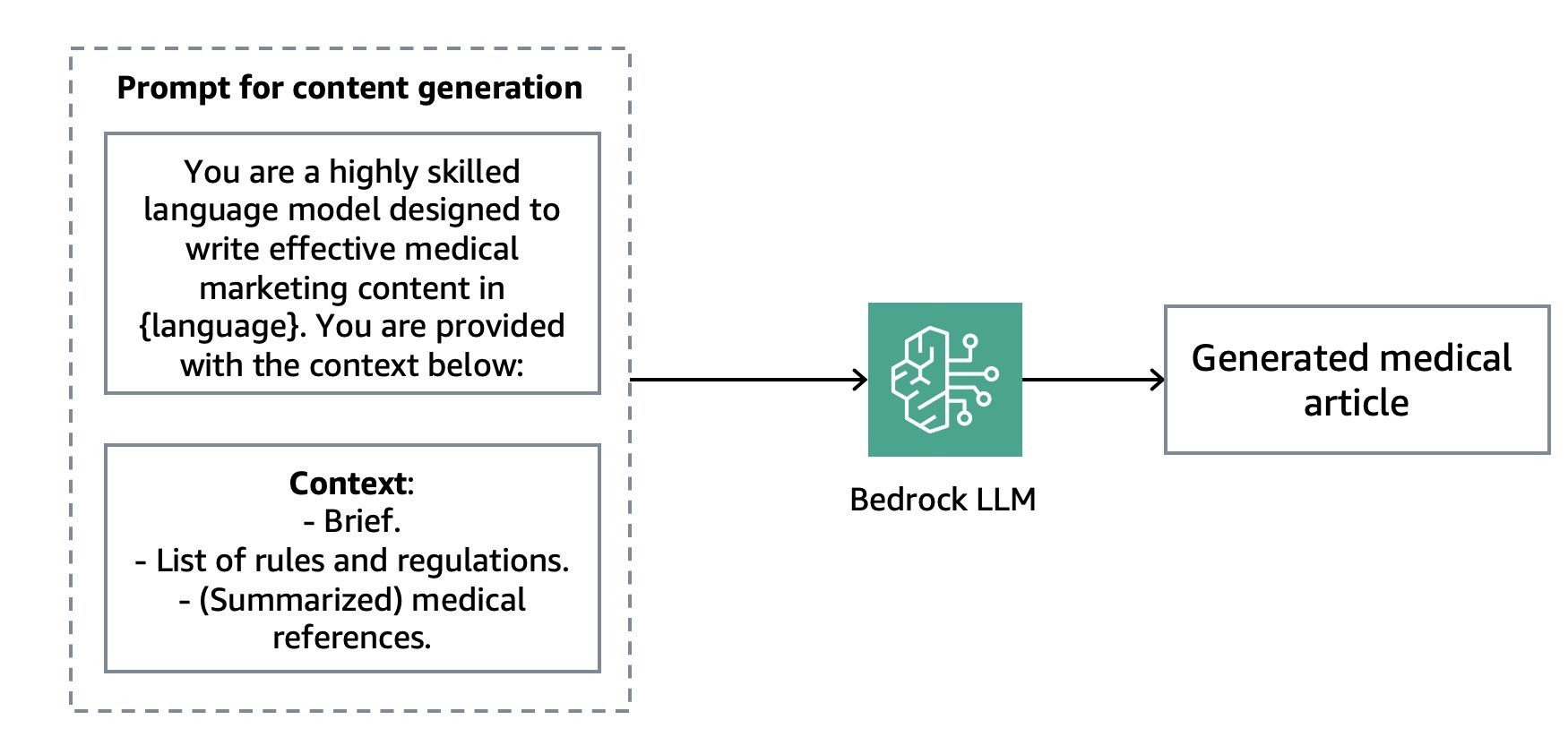
Image 5: A simplified schematic of the content generation prompt
Our pipeline is multilingual in the sense it can generate content in different languages. Claude 3, for example, has been trained on dozens of different languages besides English and can translate content between them. However, we recognize that in some cases, the complexity of the target language may require a specialized tool, in which case, we may resort to an additional translation step using amazon Translate.
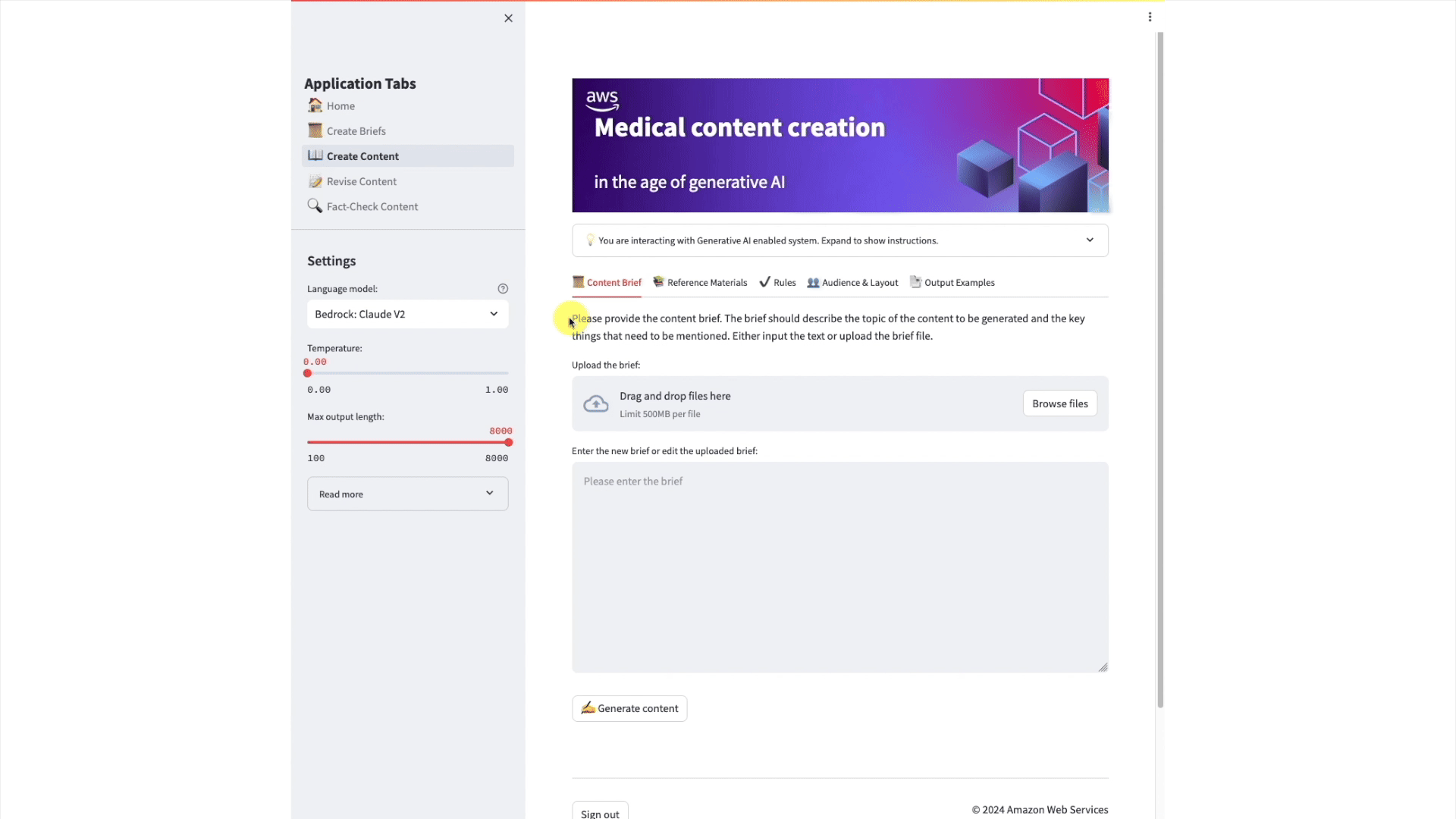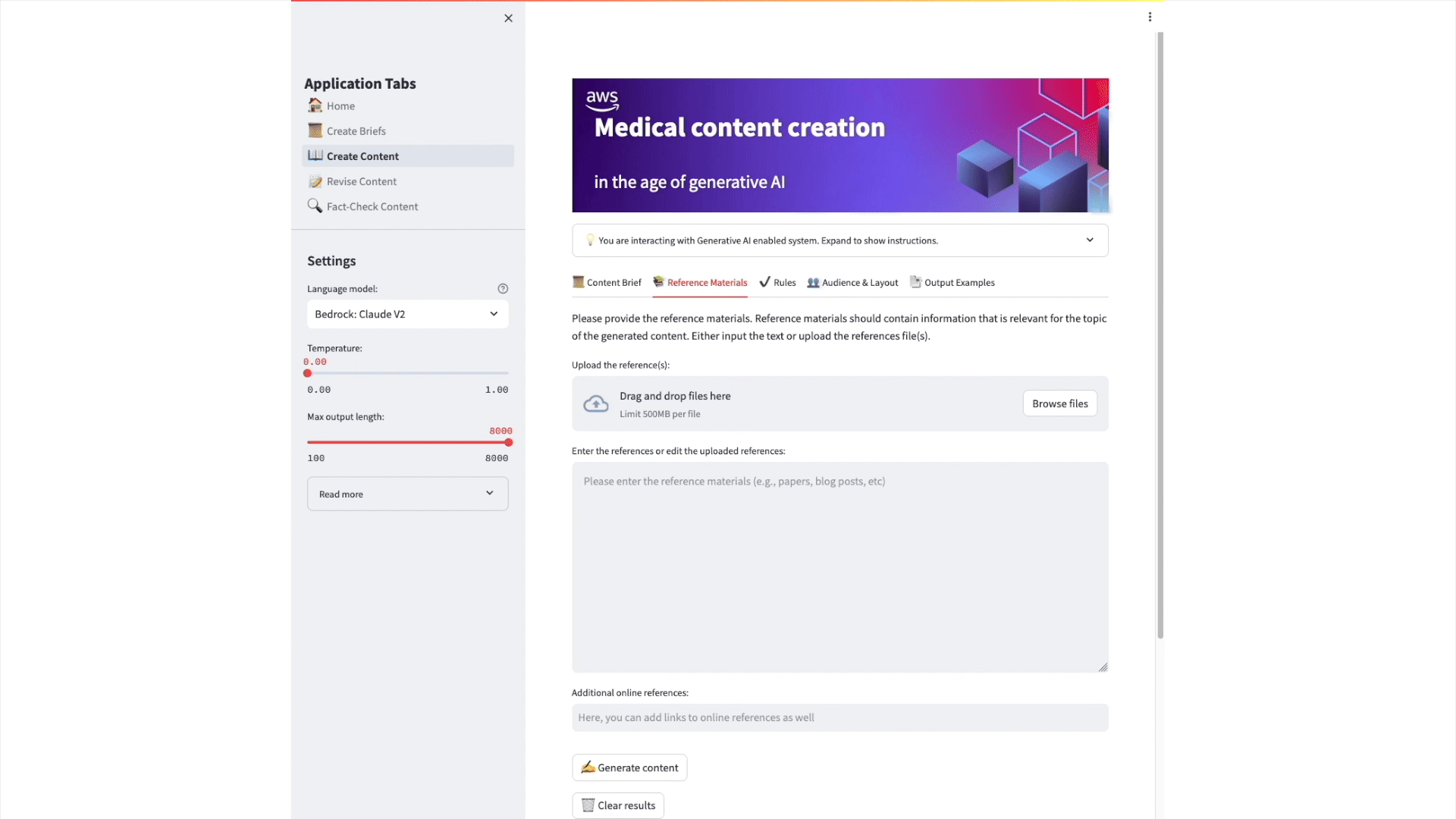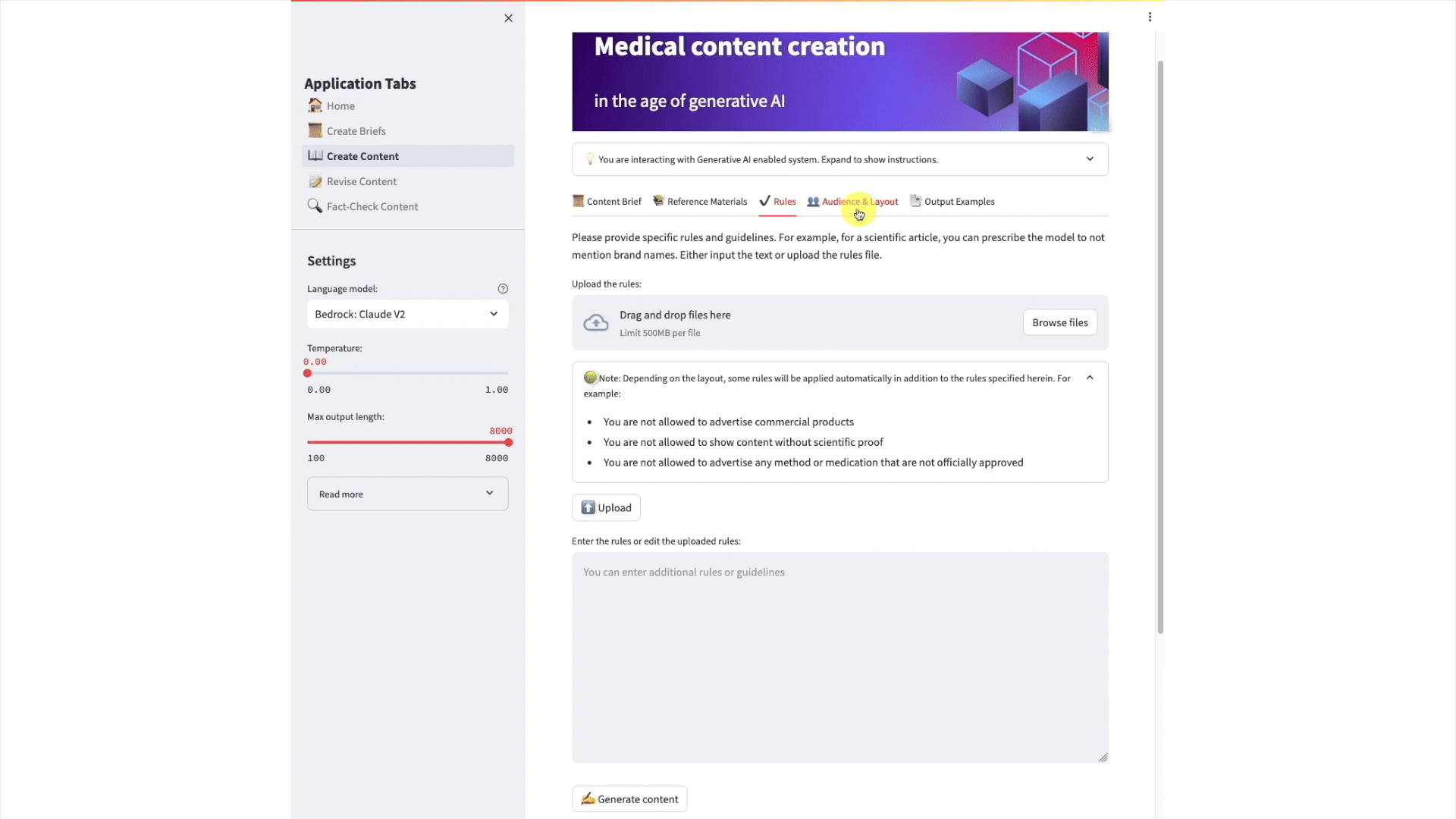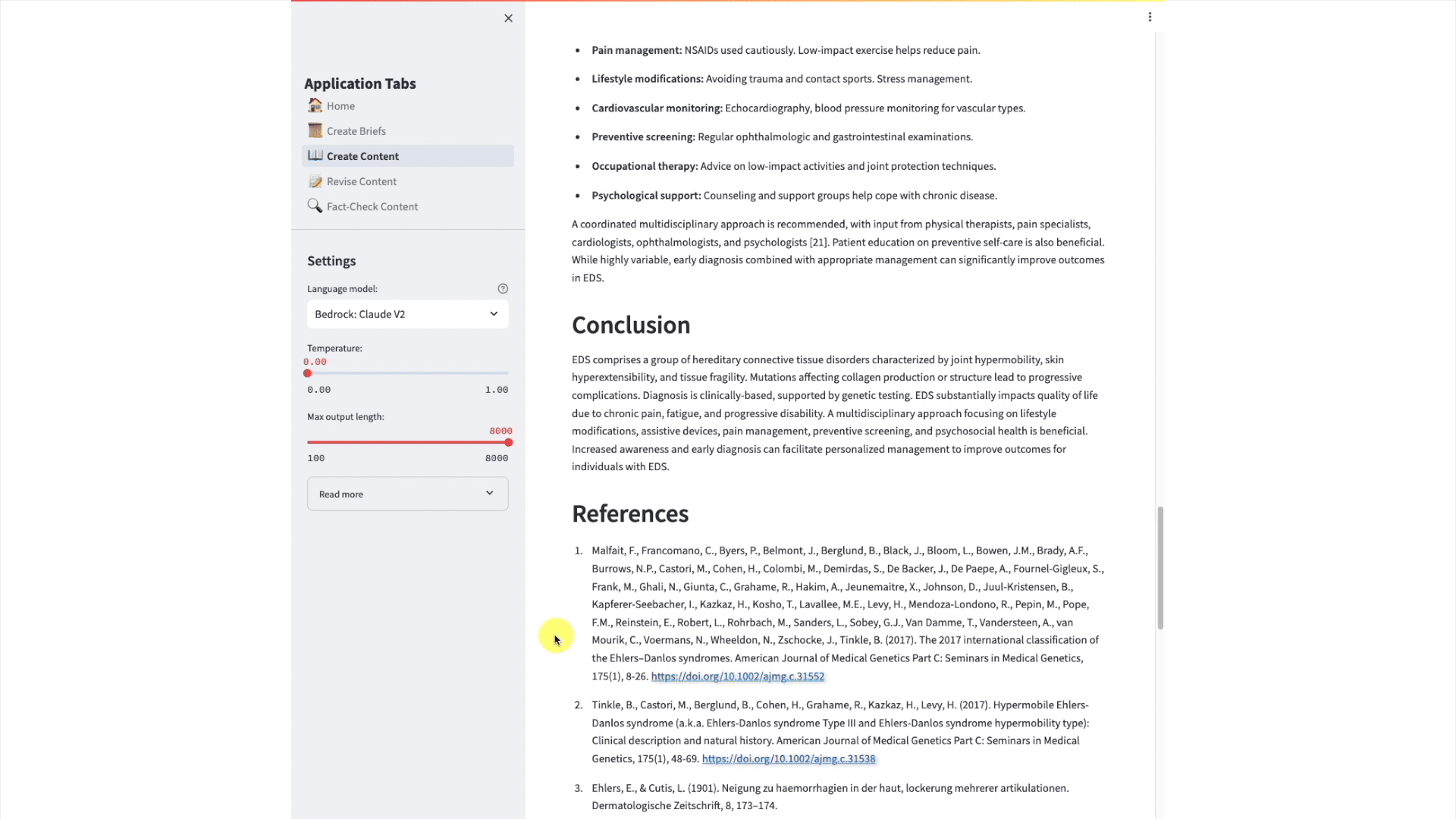 Image 6: Animation showing the generation of an article on Ehlers-Danlos syndrome, its causes, symptoms, and complications
Image 6: Animation showing the generation of an article on Ehlers-Danlos syndrome, its causes, symptoms, and complications
Content Revision
Revision is an important capability in our solution because it enables you to further tune the generated content by iteratively prompting the LLM with feedback. Since the solution has been designed primarily as an assistant, these feedback loops allow our tool to seamlessly integrate with existing processes, hence effectively assisting SMEs in the design of accurate medical content. The user can, for instance, enforce a rule that has not been perfectly applied by the LLM in a previous version, or simply improve the clarity and accuracy of some sections. The revision can be applied to the whole text. Alternatively, the user can choose to correct individual paragraphs. In both cases, the revised version and the feedback are appended to a new prompt and sent to the LLM for processing.
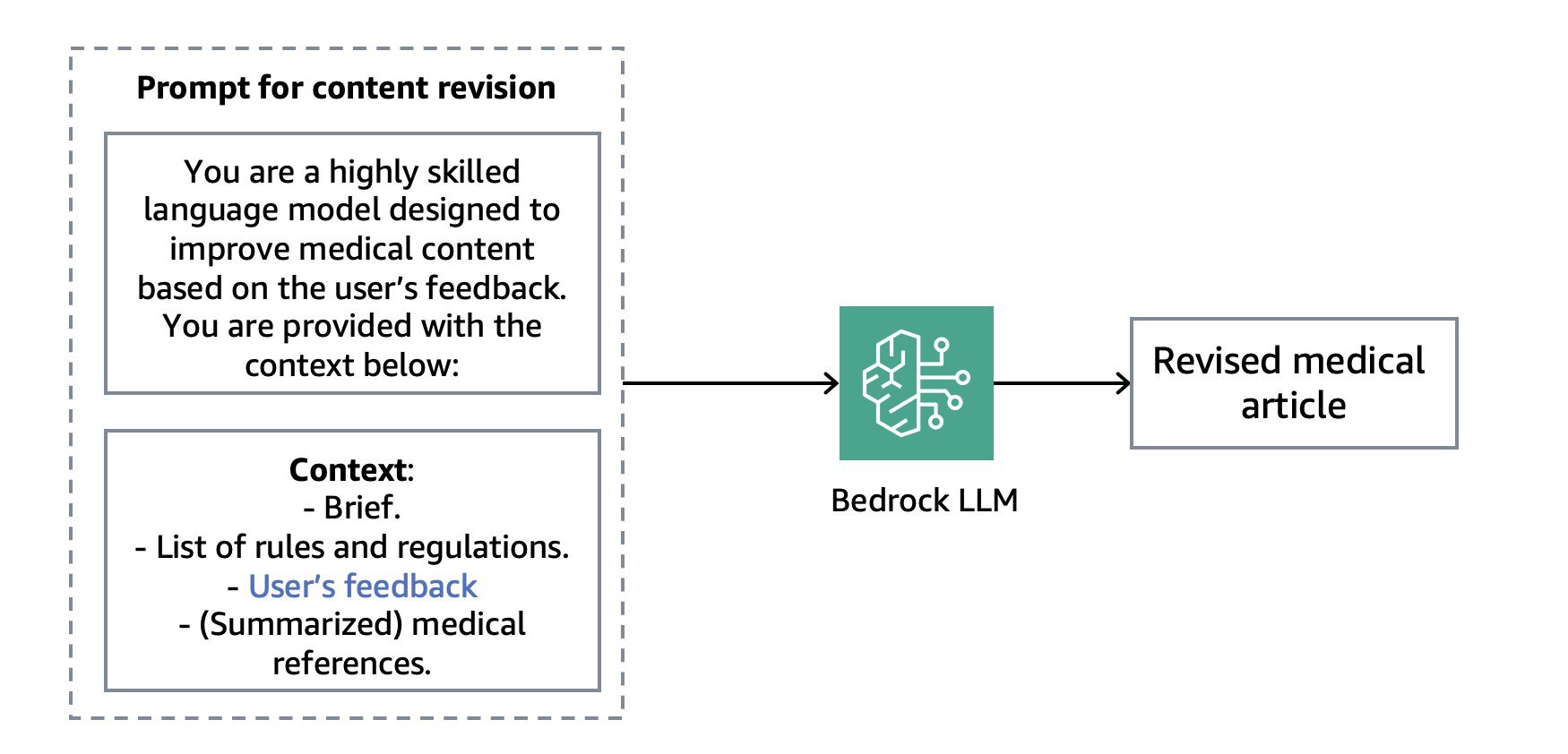
Image 7: A simplified version of the content revision prompt
Upon submission of the instructions to the LLM, a Lambda function triggers a new content generation process with the updated prompt. To preserve the overall syntactic coherence, it is preferable to re-generate the whole article, keeping the other paragraphs untouched. However, one can improve the process by re-generating only those sections for which feedback has been provided. In this case, proper attention should be paid to the consistency of the text. This revision process can be applied recursively, by improving upon the previous versions, until the content is deemed satisfactory by the user.
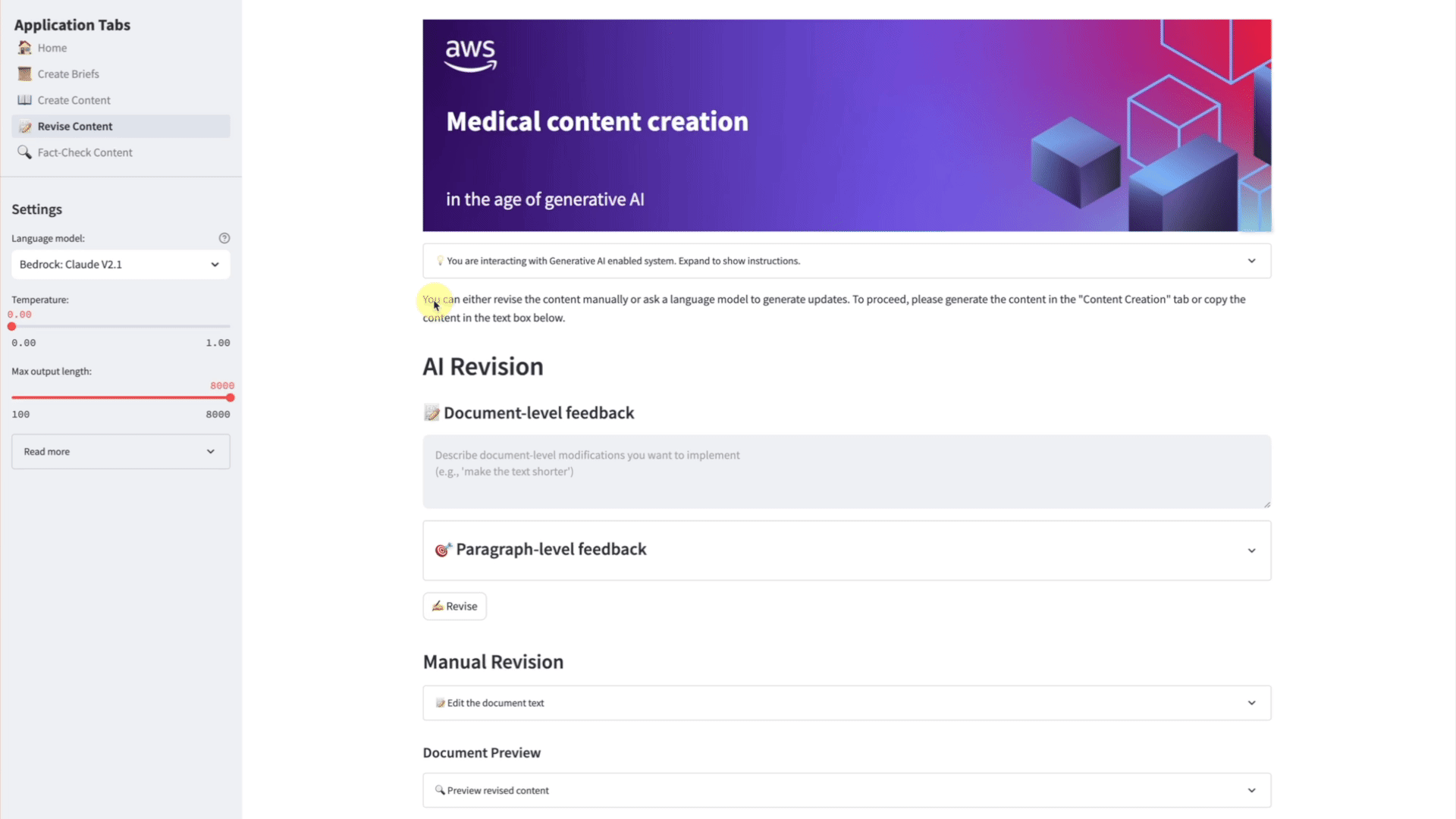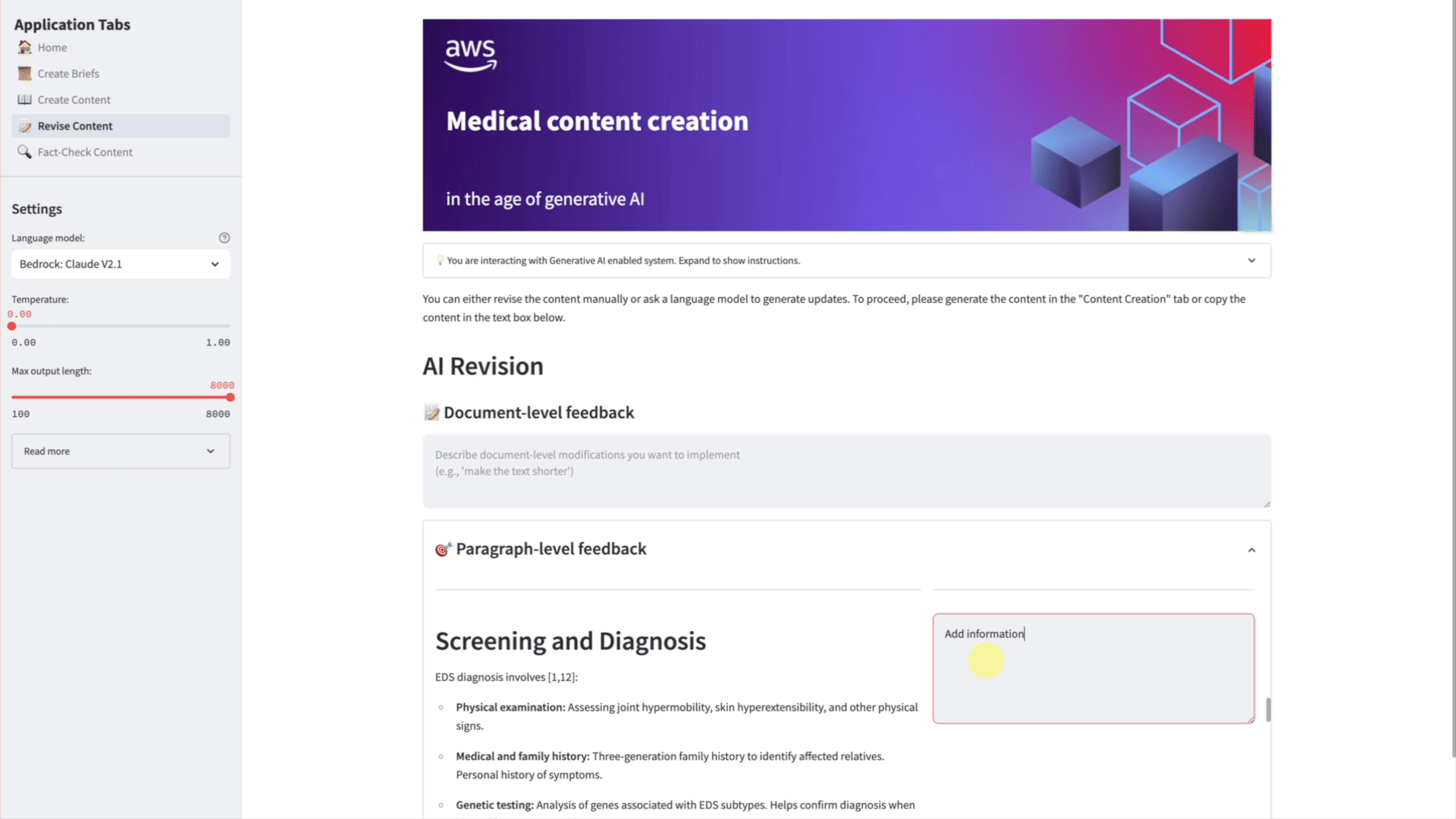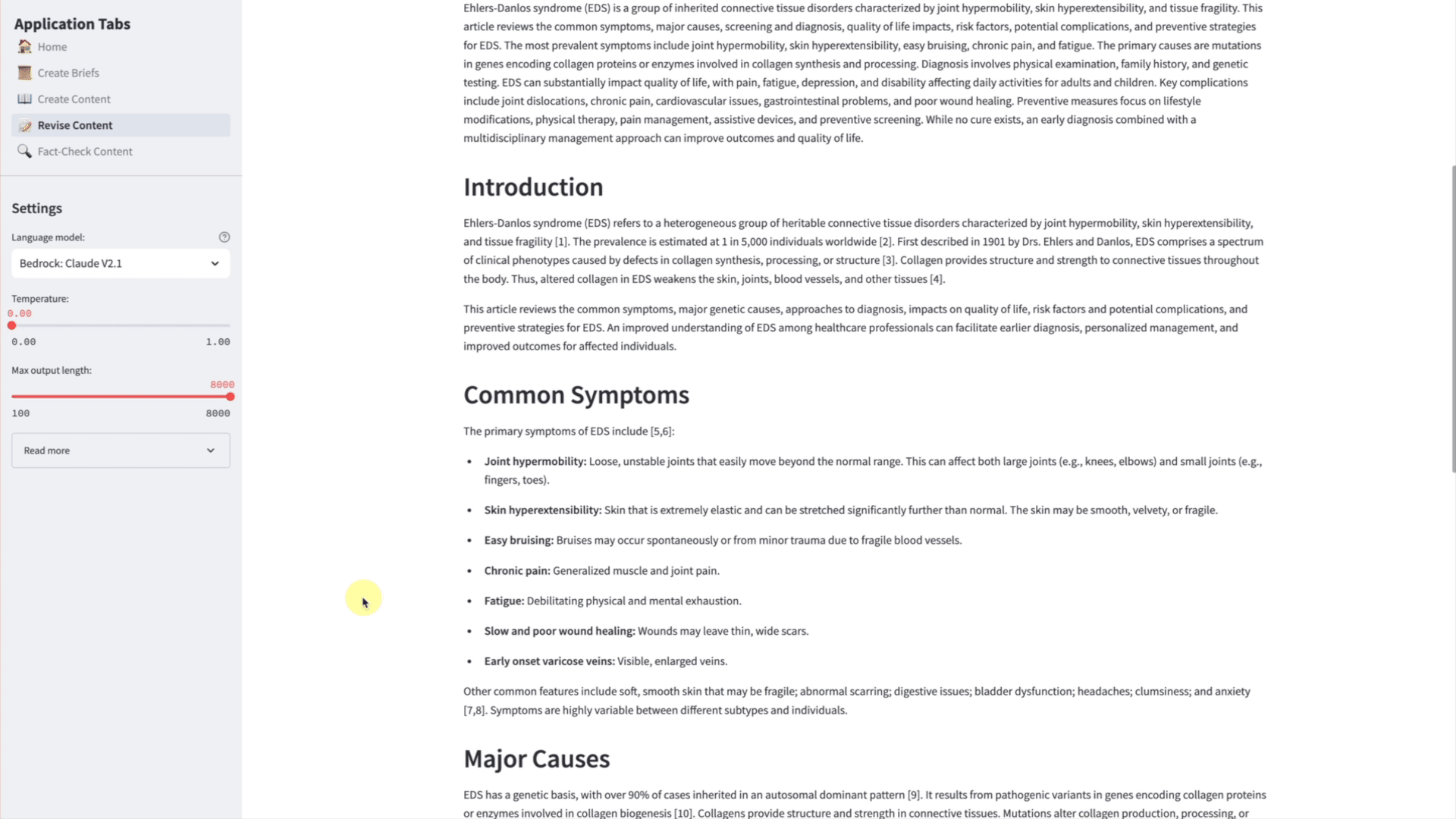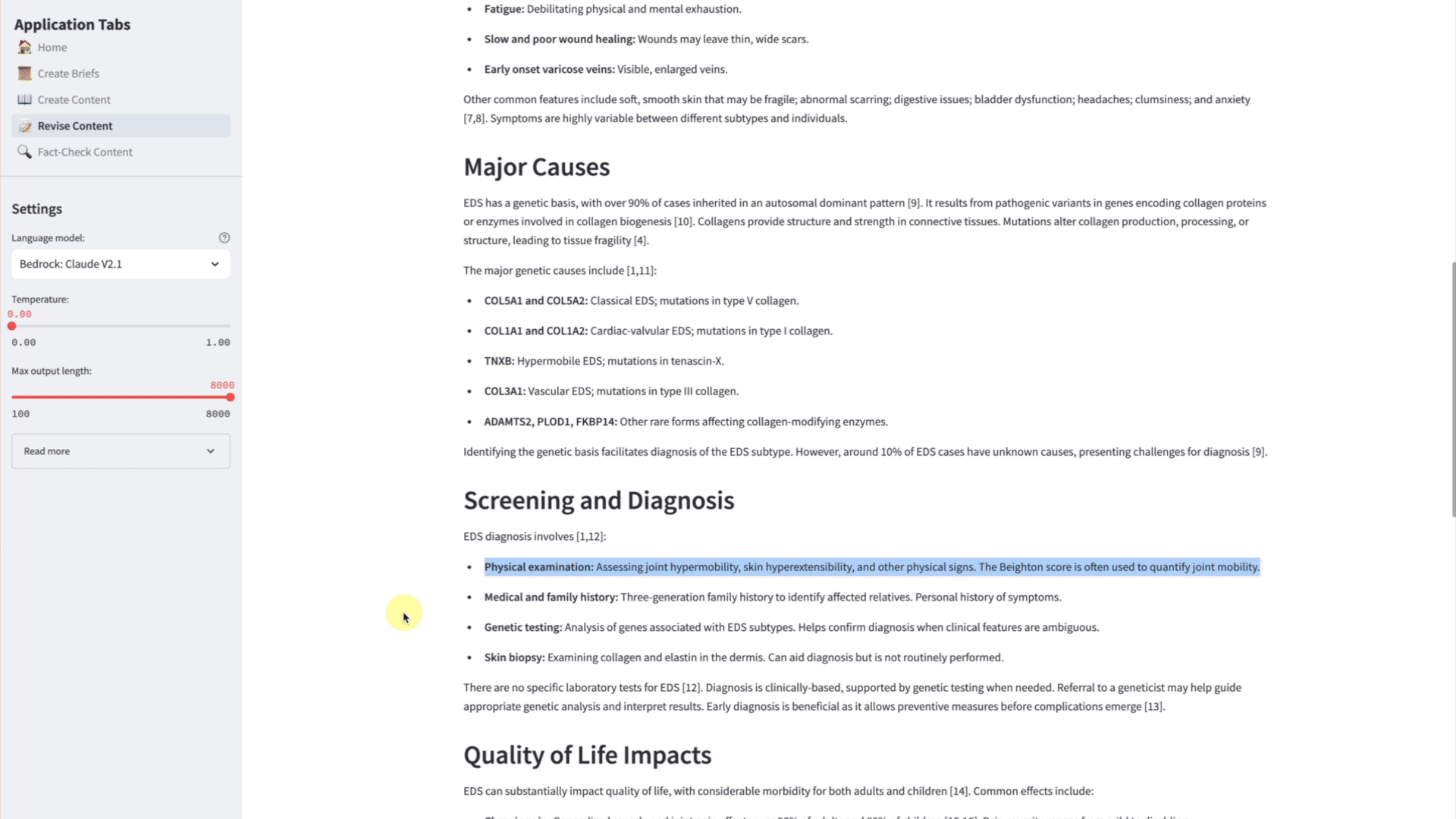
Image 8: Animation showing the revision of the Ehlers-Danlos article. The user can ask, for example, for additional information
Conclusion
With the recent improvements in the quality of LLM-generated text, generative ai has become a transformative technology with the potential to streamline and optimize a wide range of processes and businesses.
Medical content generation for disease awareness is a key illustration of how LLMs can be leveraged to generate curated and high-quality marketing content in hours instead of weeks, hence yielding a substantial operational improvement and enabling more synergies between regional teams. Through its revision feature, our solution can be seamlessly integrated with existing traditional processes, making it a genuine assistant tool empowering medical experts and brand managers.
Marketing content for disease awareness is also a landmark example of a highly regulated use case, where precision and accuracy of the generated content are critically important. To enable SMEs to detect and correct any possible hallucination and erroneous statements, we designed a factuality checking module with the purpose of detecting potential misalignment in the generated text with respect to source references.
Furthermore, our rule evaluation feature can help SMEs with the MLR process by automatically highlighting any inadequate implementation of rules or regulations. With these complementary guardrails, we ensure both scalability and robustness of our generative pipeline, and consequently, the safe and responsible deployment of ai in industrial and real-world settings.
Bibliography
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, & Illia Polosukhin. (2023). Attention Is All You Need.
- Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, & Dario Amodei. (2020). Language Models are Few-Shot Learners.
- Mesko, B., & Topol, E. (2023). The imperative for regulatory oversight of large language models (or generative ai) in healthcare. NPJ digital medicine, 6, 120.
- Clusmann, J., Kolbinger, F.R., Muti, H.S. et al. The future landscape of large language models in medicine. Commun Med 3, 141 (2023). https://doi.org/10.1038/s43856-023-00370-1
- Kai He, Rui Mao, Qika Lin, Yucheng Ruan, Xiang Lan, Mengling Feng, & Erik Cambria. (2023). A Survey of Large Language Models for Healthcare: from Data, technology, and Applications to Accountability and Ethics.
- Mu W, Muriello M, Clemens JL, Wang Y, Smith CH, Tran PT, Rowe PC, Francomano CA, Kline AD, Bodurtha J. Factors affecting quality of life in children and adolescents with hypermobile Ehlers-Danlos syndrome/hypermobility spectrum disorders. Am J Med Genet A. 2019 Apr;179(4):561-569. doi: 10.1002/ajmg.a.61055. Epub 2019 Jan 31. PMID: 30703284; PMCID: PMC7029373.
- Berglund B, Nordström G, Lützén K. Living a restricted life with Ehlers-Danlos syndrome (EDS). Int J Nurs Stud. 2000 Apr;37(2):111-8. doi: 10.1016/s0020-7489(99)00067-x. PMID: 10684952.
About the authors
 Sarah Boufelja Y. is a Sr. Data Scientist with 8+ years of experience in Data Science and Machine Learning. In her role at the GenAII Center, she worked with key stakeholders to address their Business problems using the tools of machine learning and generative ai. Her expertise lies at the intersection of Machine Learning, Probability Theory and Optimal Transport.
Sarah Boufelja Y. is a Sr. Data Scientist with 8+ years of experience in Data Science and Machine Learning. In her role at the GenAII Center, she worked with key stakeholders to address their Business problems using the tools of machine learning and generative ai. Her expertise lies at the intersection of Machine Learning, Probability Theory and Optimal Transport.
 Liza (Elizaveta) Zinovyeva is an Applied Scientist at AWS Generative ai Innovation Center and is based in Berlin. She helps customers across different industries to integrate Generative ai into their existing applications and workflows. She is passionate about ai/ML, finance and software security topics. In her spare time, she enjoys spending time with her family, sports, learning new technologies, and table quizzes.
Liza (Elizaveta) Zinovyeva is an Applied Scientist at AWS Generative ai Innovation Center and is based in Berlin. She helps customers across different industries to integrate Generative ai into their existing applications and workflows. She is passionate about ai/ML, finance and software security topics. In her spare time, she enjoys spending time with her family, sports, learning new technologies, and table quizzes.
 Nikita Kozodoi is an Applied Scientist at the AWS Generative ai Innovation Center, where he builds and advances generative ai and ML solutions to solve real-world business problems for customers across industries. In his spare time, he loves playing beach volleyball.
Nikita Kozodoi is an Applied Scientist at the AWS Generative ai Innovation Center, where he builds and advances generative ai and ML solutions to solve real-world business problems for customers across industries. In his spare time, he loves playing beach volleyball.
 Marion Eigner is a Generative ai Strategist who has led the launch of multiple Generative ai solutions. With expertise across enterprise transformation and product innovation, she specializes in empowering businesses to rapidly prototype, launch, and scale new products and services leveraging Generative ai.
Marion Eigner is a Generative ai Strategist who has led the launch of multiple Generative ai solutions. With expertise across enterprise transformation and product innovation, she specializes in empowering businesses to rapidly prototype, launch, and scale new products and services leveraging Generative ai.
 Nuno Castro is a Sr. Applied Science Manager at AWS Generative ai Innovation Center. He leads Generative ai customer engagements, helping AWS customers find the most impactful use case from ideation, prototype through to production. He’s has 17 years experience in the field in industries such as finance, manufacturing, and travel, leading ML teams for 10 years.
Nuno Castro is a Sr. Applied Science Manager at AWS Generative ai Innovation Center. He leads Generative ai customer engagements, helping AWS customers find the most impactful use case from ideation, prototype through to production. He’s has 17 years experience in the field in industries such as finance, manufacturing, and travel, leading ML teams for 10 years.
 Aiham Taleb, PhD, is an Applied Scientist at the Generative ai Innovation Center, working directly with AWS enterprise customers to leverage Gen ai across several high-impact use cases. Aiham has a PhD in unsupervised representation learning, and has industry experience that spans across various machine learning applications, including computer vision, natural language processing, and medical imaging.
Aiham Taleb, PhD, is an Applied Scientist at the Generative ai Innovation Center, working directly with AWS enterprise customers to leverage Gen ai across several high-impact use cases. Aiham has a PhD in unsupervised representation learning, and has industry experience that spans across various machine learning applications, including computer vision, natural language processing, and medical imaging.






{kind=link}