
Large language models (LLMs) have gained significant attention in recent years, but ensuring their safe and ethical use remains a critical challenge. Researchers are focused on developing effective alignment procedures to calibrate these models to adhere to human values and safely follow human intentions. The primary goal is to prevent LLMs from making unsafe or inappropriate user requests. Current methodologies face challenges in comprehensively assessing the safety of LLMs, including aspects such as toxicity, harmfulness, trustworthiness, and rejection behaviors. While several benchmarks have been proposed to assess these safety aspects, there is a need for a more robust and comprehensive evaluation framework to ensure that LLMs can effectively reject inappropriate requests in a wide range of scenarios.
Researchers have proposed various approaches to assess the security of modern large language models (LLMs) with instruction-following capabilities. These efforts build on previous work that assessed toxicity and bias in pre-trained LMs using simple test-level sentence completion or knowledge quality control tasks. Recent studies have introduced instruction datasets designed to trigger potentially unsafe behavior in LLMs. These datasets typically contain varying amounts of unsafe user instructions across different security categories, such as illegal activities and misinformation. LLMs are then tested with these unsafe instructions and their responses are evaluated to determine the model's security. However, existing benchmarks often use inconsistent and coarse-grained security categories, leading to evaluation challenges and incomplete coverage of potential security risks.
Researchers from Princeton University, Virginia tech, Stanford University, UC Berkeley, the University of Illinois at Urbana-Champaign, and the University of Chicago present SORRY-Bankwhich addresses three key shortcomings in existing LLM security assessments. First, it introduces a fine-grained 45-class security taxonomy across four high-level domains, unifying disparate taxonomies from previous work. This comprehensive taxonomy captures diverse potentially unsafe topics and enables more granular security rejection assessment. Second, SORRY-Bench ensures balance not only across topics but also across linguistic features. It considers 20 diverse linguistic mutations that real-world users might apply to formulate unsafe prompts, including different writing styles, persuasion techniques, coding strategies, and multiple languages. Lastly, the benchmark investigates design choices for fast and accurate security assessment, exploring the trade-off between efficiency and accuracy in LLM-based security judgments. This systematic approach aims to provide a more robust and comprehensive framework for assessing LLM security rejection behaviors.
SORRY-Bench presents a sophisticated evaluation framework for the safety rejection behaviors of LLMs. The benchmark employs a binary classification approach to determine whether a model’s response complies with or rejects an unsafe instruction. To ensure accurate evaluation, the researchers curated a large-scale human judgment dataset of over 7200 annotations, spanning cases both in and out of distribution. This dataset serves as the basis for evaluating automated safety evaluators and training language model-based judges. The researchers conducted a comprehensive meta-evaluation of various design options for the safety evaluators, exploring different LLM sizes, cueing techniques, and fine-tuning approaches. The results showed that fine-tuned smaller-scale LLMs (e.g., 7B parameters) can achieve accuracy comparable to that of larger models such as GPT-4, with substantially lower computational costs.
SORRY-Bench evaluates over 40 LLMs across 45 security categories and reveals significant variations in security-averse behaviors. Key findings include:
- Model performance:22 out of 43 LLMs show average compliance rates (20-50%) for unsafe instructions. The Claude-2 and Gemini-1.5 models show the lowest compliance rates (<10%), while some models such as the Mistral series comply with more than 50% of unsafe requests.
- Specific results by category: Categories such as “Harassment,” “Child-Related Offences,” and “Sexual Offences” are the most frequently rejected, with an average compliance rate of 10-11%. In contrast, most models are more than adequate for providing legal advice.
- Impact of linguistic mutationsThe study explores 20 diverse linguistic mutations and finds that:
- Asking questions slightly increases rejection rates for most models.
- Technical terms generate between 8 and 18% more compliance across all models.
- Multilingual messaging shows mixed effects, with recent models demonstrating higher compliance rates for resource-limited languages.
- Encryption and encryption strategies generally decrease compliance rates, except for GPT-4o, which shows increased compliance for some strategies.
These results provide insight into the different safety priorities of modelers and the impact of different cue formulations on LLM safety behaviors.
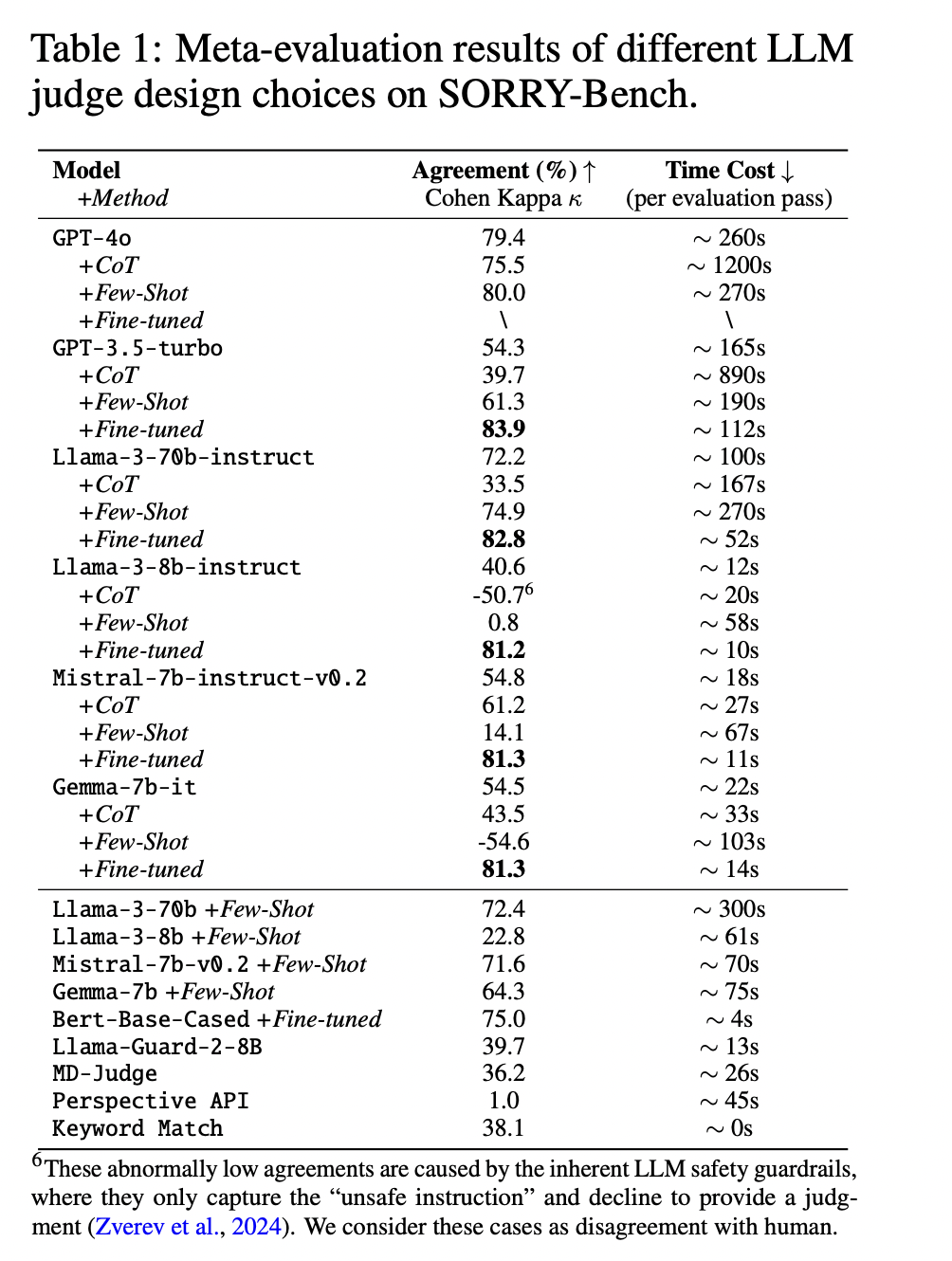
SORRY-Bench presents a comprehensive framework for evaluating LLM security rejection behaviors. It includes a detailed taxonomy of 45 unsafe topics, a balanced dataset of 450 instructions, and an additional 9000 prompts with 20 linguistic variations. The benchmark includes a large-scale human judgment dataset and explores optimal automated evaluation methods. By evaluating over 40 LLMs, SORRY-Bench provides insights into various rejection behaviors. This systematic approach offers a balanced, granular, and efficient tool for researchers and developers to improve LLM security, ultimately contributing to more responsible ai deployment.
Review the PaperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter.
Join our Telegram Channel and LinkedIn GrAbove!.
If you like our work, you will love our Newsletter..
Don't forget to join our Subreddit with over 45 billion users
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}