
Introduction
This article covers the creation of a multilingual chatbot for multilingual areas like India, using large language models. The system improves consumer outreach and personalization by using LLM to translate questions between local languages and English. We go over the architecture, implementation details, advantages, and required actions. Further research efforts will focus on possible advancements and wider implementation of this solution.
Learning objectives
- Understand the role and capabilities of Large Language Models (LLM) to improve customer experience and personalization.
- Learn how to develop a multilingual chatbot using LLM for translation and query handling.
- Explore the architecture and implementation details of a multilingual chatbot using tools like Gradio, Databricks, Langchain, and MLflow.
- Gain knowledge of embedding techniques and creating a vector database for retrieval-augmented generation (RAG) with custom data.
- Identify potential future advancements and improvements in scaling and fine-tuning LLM-based multilingual chatbots for broader applications.
This article was published as part of the Data science blogathon.
<h2 class="wp-block-heading" id="h-rise-of-technology-and-chat-gpt”>technology boom and Chat-GPT
With the rise of technology and the launch of Chat-GPT, the world has shifted its focus towards utilizing large language models for use. Organizations are rapidly using large language models to generate business value. Organizations are constantly using them to improve customer experience, add personalization, and enhance customer outreach.
Role of large language models
An LLM is a computer program that has been given enough examples to be able to recognize and interpret human language or other types of complex data. Many organizations train LLMs with data collected from the Internet, comprising thousands or millions of gigabytes of text. But the quality of the samples affects the ability of LLMs to learn natural language, so programmers in an LLM can use a more curated data set.
Understanding Large Language Models (LLM)
LLMs use a type of machine learning called deep learning to understand how characters, words, and sentences work together. Deep learning involves the probabilistic analysis of unstructured data, eventually allowing the deep learning model to recognize distinctions between pieces of content without human intervention.
Programmers further train LLMs by fine-tuning, tweaking, or tuning them to perform specific tasks, such as interpreting questions, generating answers, or translating text from one language to another.
Motivation for a multilingual chatbot
Multiple languages are spoken in many geographic regions of the world. India, as a multilingual country, speaks several languages, and only 10% of the population can read and write in English. In this country, a single common language is adopted in the community for proper communication, but this can cause one language to predominate over the others and put speakers of other languages at a disadvantage.
This can also lead to the disappearance of a language, its distinctive culture and way of thinking. For national and international companies, having their business or marketing content in multiple languages is an expensive option, which is why most of them limit themselves to a single business language (English), which could also mean losing business. opportunities to better connect with the local public and, therefore, potential clients. While the use of English is not inherently incorrect, it excludes those who are not fluent in that language from participating in conventional commerce.
Proposed solution
The proposed solution allows people to make queries in their local language, use LLM to understand and retrieve information in English, and translate it back into the local language. This solution leverages the power of large language models for translation and query handling.
Key Features and Functionalities
- Translation from local language to English and vice versa.
- Find the most similar query in the database.
- Answer queries through the base LLM if a similar query is not found.
This solution helps businesses, especially banks, reach a wider population and enables banking services to benefit common people, improving their financial prospects.
Advantages of a Multilingual Chatbot
- Greater customer reach: By supporting multiple languages, a chatbot can reach a broader audience and provide assistance to users who may not speak the same language. Make information and services, especially essential services like banking, more accessible to people. This benefits both people and the company.
- Enhanced Personalization: Multilingual chatbots can provide personalized recommendations and tailored experiences to users based on their language and cultural preferences.
- Improved customer service: Chatbots can provide better customer service and help resolve issues more efficiently, leading to greater customer satisfaction.
Multilingual Chatbot Architecture
- The user opens the Gradio application and has options to write the data in the local language.
- Translation: Use the given message in a given locale using LLM (Llama-70b-chat) via mlflow route.
- The system converts the translated message into embeds using Instructor-xl embeddings and searches it in the created vector database (chroma) from the custom local language data.
- The system passes the message with the context (the most similar embeddings from the semantic search) to the LLM to obtain the result.
- Translation: Translation of the result into the local language.
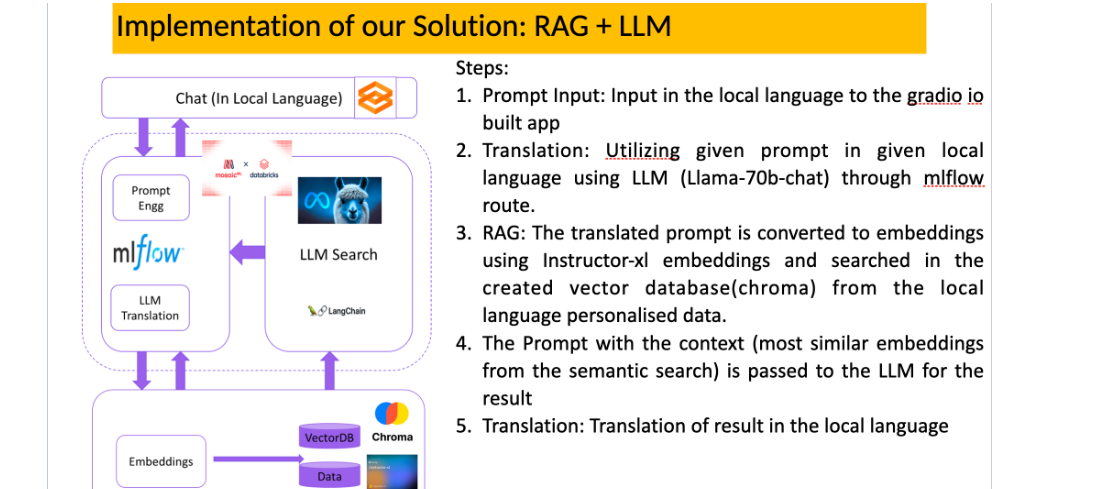
Implementation details
- Gradio is used to build the interface of the application.
- Databricks was used for coding. The entire framework is designed in Databricks.
- The LLAMA-2 70b chat was used as the chosen large language model. Used MosaicML inference to get the chat completion result from the message.
- The application performed embeddings using the Instructor-xl model.
- The application stored the embeddings in the ChromaDb vector database.
- The application framework and pipeline used Langchain and MLflow.
Code Deployment
Let's now implement a multilingual chatbot using a large language model.
Step 1: Install the necessary packages
Packages are easily available at Hugging Face.
%pip install mlflow
%pip install --upgrade langchain
%pip install faiss-cpu
%pip install pydantic==1.10.9
%pip install chromadb
%pip install InstructorEmbedding
%pip install gradioUploading the CSV for the RAG implementation and converting it to text fragments
RAG is an artificial intelligence framework for retrieving data from an external knowledge base to ground large language models (LLMs) in the most accurate and up-to-date information and provide users with insights into the generative process of LLMs.
Researchers and developers use Recall Augmented Generation (RAG) to improve the quality of answers generated by the LLM by basing the model on external sources of knowledge, complementing the LLM's internal representation of information.
The data were questions and answers in Hindi language. The set of questions and answers can be generated for any language and used as input for the RAG implementation.
Step 2: Load and prepare data for RAG
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/Workspace/DataforRAG_final1.csv",
encoding="utf-8", csv_args={'delimiter': ','})
data = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
#from langchain.text_splitter import CharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
text_chunks = text_splitter.split_documents(data)
Loading Instructor-Xl Embeddings
We downloaded the Instructor-XL embeds from the Hugging Face site.
Step 3: Creating and Saving Embeds
from langchain.embeddings import HuggingFaceInstructEmbeddings
instructor_embeddings = HuggingFaceInstructEmbeddings(model_name="hkunlp/instructor-xl",
model_kwargs={"device": "cuda"})We used the Chroma vector database to store the embeddings created for the RAG data. We created the instructor-xl embeddings for the custom dataset.
# Embed and store the texts
# Supplying a persist_directory will store the embeddings on disk
from langchain.vectorstores import Chroma
persist_directory = 'db'
## Here is the nmew embeddings being used
embedding = instructor_embeddings
vectordb = Chroma.from_documents(documents=text_chunks,
embedding=embedding,
persist_directory=persist_directory)
# persiste the db to disk
vectordb.persist()
vectordb = None
# Now we can load the persisted database from disk, and use it as normal.
vectordb = Chroma(persist_directory=persist_directory,
embedding_function=embedding)
Step 4: Define the notice template
from langchain.llms import MlflowAIGateway
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
import gradio as gr
from mlflow.gateway import set_gateway_uri, create_route, query,delete_route
set_gateway_uri("databricks")
mosaic_completion_route = MlflowAIGateway(
gateway_uri="databricks",
route="completion"
)
# Wrap the prompt and Gateway Route into a chain
template = """(INST) <>
You are Banking Question Answering Machine. Answer Accordingly
<>
{context}
{question} (/INST)
"""
prompt = PromptTemplate(input_variables=('context', 'question'),
template=template)
retrieval_qa_chain = RetrievalQA.from_chain_type(llm=mosaic_completion_route, chain_type="stuff",
retriever=vectordb.as_retriever(), chain_type_kwargs={"prompt": prompt})
def generating_text(prompt,route_param,token):
# Create a Route for text completions with MosaicML Inference API
create_route(
name=route_param,
route_type="llm/v1/completions",
model={
"name": "llama2-70b-chat",
"provider": "mosaicml",
"mosaicml_config": {
"mosaicml_api_key": "3abc"
}
}
)
response1 = query(
route=route_param,
data={"prompt": prompt,"temperature": 0.1,
"max_tokens": token}
)
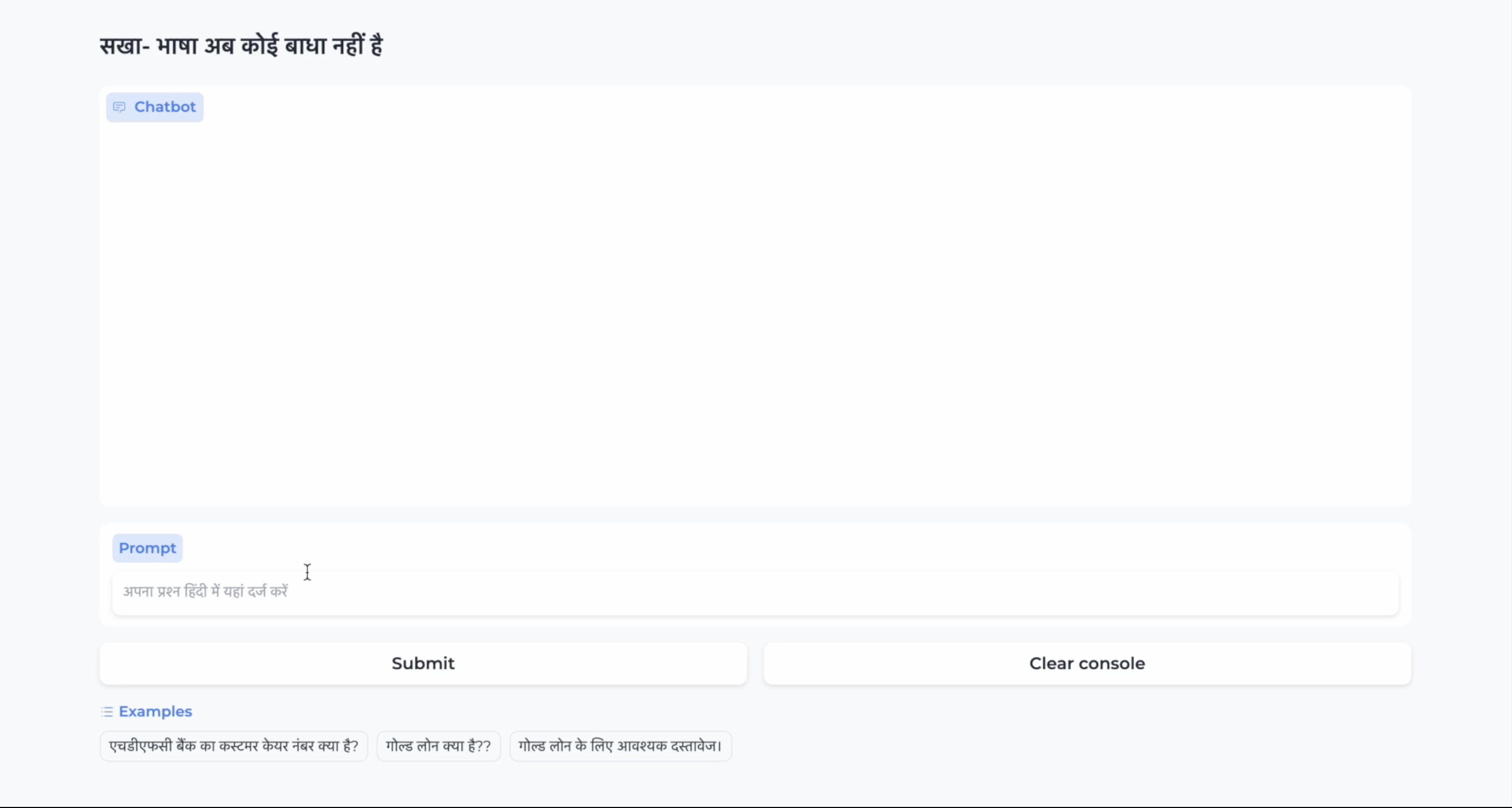
return(response1)Step 5: Gradio App Development
We developed the front-end using the Gradio package. It has a fixed template that can be customized according to each person's needs.
import string
import random
# initializing size of string
N = 7
def greet(Input,chat_history):
RouteName1="text1"
RouteName2="text2"
system="""you are a translator which converts english to hindi.
Please translate the given text to hindi language and
only return the content translated. no explanation"""
system1="""you are a translator which converts hindi to english.
Please translate the given text to english language from hindi language and
only return the content translated.
no explanation"""
prompt=f"(INST) <> {system1} <> {Input}(/INST)"
delete_route("text1")
result=generating_text(prompt,RouteName1,400)
res=result('candidates')(0)('text')
t=retrieval_qa_chain.run(res)
prompt2=f"(INST) <> {system} <> {t} (/INST)"
delete_route("text2")
token=800
result1=generating_text(prompt2,RouteName2,token)
chat_history.append((Input, result1('candidates')(0)('text')))
return "", chat_history
with gr.Blocks(theme=gr.themes.Soft(primary_hue=gr.themes.colors.blue,
secondary_hue=gr.themes.colors.red)) as demo:
gr.Markdown("## सखा- भाषा अब कोई बाधा नहीं है")
chatbot = gr.Chatbot(height=400) #just to fit the notebook
msg = gr.Textbox(label="Prompt",placeholder="अपना प्रश्न हिंदी में यहां दर्ज करें",max_lines=2)
with gr.Row():
btn = gr.Button("Submit")
clear = gr.ClearButton(components=(msg, chatbot), value="Clear console")
# btn = gr.Button("Submit")
# clear = gr.ClearButton(components=(msg, chatbot), value="Clear console")
btn.click(greet, inputs=(msg, chatbot), outputs=(msg, chatbot))
msg.submit(greet, inputs=(msg, chatbot), outputs=(msg, chatbot))
gr.Examples((("एचडीएफसी बैंक का कस्टमर केयर नंबर क्या है?"),
("गोल्ड लोन क्या है??"),('गोल्ड लोन के लिए आवश्यक दस्तावेज।')),
inputs=(msg,chatbot))
gr.close_all()
demo.launch(share=True,debug=True)
#import csvMore progress
Let us now explore more advancements of the Multilingual Chatbot.
Adaptation to different regional languages
Currently, for demonstration purposes, we have built the solution for Hindi language. The same can be scaled for different regional languages.
Fine tuning of the LLAMA-2 70b chat model
- Model fitting with custom data in Hindi.
- Expand adjustment to other local native languages.
Potential improvements and future work
- Incorporating additional features and functionalities.
- Improve the accuracy and efficiency of translations and responses.
- Exploring the integration of more advanced LLM and embedding techniques.
Conclusion
Large Language Models (LLM) could be used to create a multilingual chatbot that will transform accessibility and communication in linguistically diverse areas such as India. This technology improves customer engagement by addressing linguistic barriers. Future developments in LLM capabilities and expansion to additional languages will further enhance the user experience and increase the global reach of multilingual chatbots.
Key points
- Multilingual chatbots leveraging LLMs bridge language gaps and improve user accessibility and engagement.
- Integration of Gradio, Databricks, Langchain and MLflow streamlines the development of multilingual chatbots.
- The use of recovery augmented generation (RAG) improves response quality by leveraging external knowledge sources.
- Personalized experiences and expanded customer reach are facilitated by language-specific embeddings and vector databases.
- Future advances aim to scale and refine LLMs to achieve broader linguistic diversity and greater efficiency.
Frequent questions
A multilingual chatbot is an ai-powered tool capable of understanding and responding in multiple languages, facilitating communication across diverse language backgrounds.
A. LLMs allow multilingual chatbots to translate queries, understand context and generate responses in different languages with great precision and naturalness.
A. LLMs improve customer outreach by catering to diverse language preferences, enhance personalization through tailored interactions, and increase efficiency in handling multilingual inquiries.
A. Companies can expand their customer base by offering services in their preferred languages, improve customer satisfaction with personalized interactions, and streamline operations in global markets.
The media displayed in this article is not the property of Analytics Vidhya and is used at the discretion of the author.






{kind=link}