
Large language models (LLMs) face a critical challenge in their training process: the looming shortage of high-quality Internet data. Predictions suggest that by 2026, the available pool of such data will be exhausted, forcing researchers to turn to synthetic or model-generated data for training. This change presents both opportunities and risks. While some studies have shown that expanding synthetic data can improve performance on complex reasoning tasks, others have revealed a worrying trend. Training on synthetic data can potentially lead to a downward spiral in model performance, amplifying biases, propagating misinformation, and reinforcing unwanted stylistic properties. The primary challenge lies in designing synthetic data that effectively addresses data sparsity without compromising the quality and integrity of the resulting models. This task is particularly daunting given the current lack of understanding of how synthetic data influences LLM behavior.
Researchers have explored various approaches to address the challenges of LLM training using synthetic data. Standard methods, such as imposing teacher input on expert data, have shown limitations, particularly in mathematical reasoning. Efforts to generate positive synthetic data aim to mimic high-quality training data, using sources such as more robust teacher models and self-generated content. While this approach has shown promise, challenges remain in verifying the quality of synthetic mathematical data. Concerns remain about bias amplification, model collapse, and overfitting in spurious steps. To mitigate these issues, researchers are investigating the use of model-generated negative responses to identify and unlearn problematic patterns in training data.
Researchers from Carnegie Mellon University, Google DeepMind and MultiOn present the study to investigate the impact of synthetic data on LLM mathematical reasoning abilities. It examines both positive and negative synthetic data and finds that positive data improves performance, but with slower scaling rates than pre-training. In particular, self-generated positive responses often equal the effectiveness of twice the data from larger models. They introduce a robust approach that uses negative synthetic data, comparing it with positive data at critical steps. This technique, equivalent to per-step advantage-weighted reinforcement learning, demonstrates the potential to scale efficiency up to eight times compared to using only positive data. The study develops scaling laws for both types of data on common reasoning benchmarks, offering valuable insights into optimizing the use of synthetic data to improve LLM performance on mathematical reasoning tasks.
The detailed architecture of the proposed method involves several key components:
- Synthetic Data Pipeline:
- It causes capable models like GPT-4 and Gemini 1.5 Pro to generate new problems similar to the real ones.
- Obtain traces of solutions with step-by-step reasoning for these problems.
- It implements a binary reward function to verify the correctness of the solution traces.
- Building the dataset:
- Create a positive synthetic data set from correct problem-solution pairs.
- Generate positive and negative data sets using model-generated solutions.
- Learning algorithms:
- Supervised Fine Tuning (SFT):
- Trains in 𝒟syn using next token prediction.
- Supervised Fine Tuning (SFT):
- Rejection Fine Tuning (RFT):
- Uses SFT policy to generate positive responses to 𝒟syn problems.
- Apply next token prediction loss on these auto-generated positive responses.
- Preference Optimization:
- Uses Direct Preference Optimization (DPO) to learn from positive and negative data.
- It implements two variants: standard DPO and per-step DPO.
- Step-wise DPO identifies the “first well” in solution follow-ups to focus on critical steps.
This architecture allows for comprehensive analysis of different types of synthetic data and learning approaches, enabling the study of their impact on LLM mathematical reasoning capabilities.
The study reveals important insights into synthetic data scaling for LLM mathematical reasoning. Scaling positive data shows improvement, but at a slower rate than previous training. Surprisingly, the self-generated positive data (RFT) outperforms the data from more capable models, doubling the efficiency. The most surprising result comes from the strategic use of negative data with direct per-step preference optimization, which increases data efficiency by 8 times compared to positive data alone. This approach consistently outperforms other methods, highlighting the critical importance of carefully constructing and using both positive and negative synthetic data in training LLM for mathematical reasoning tasks.
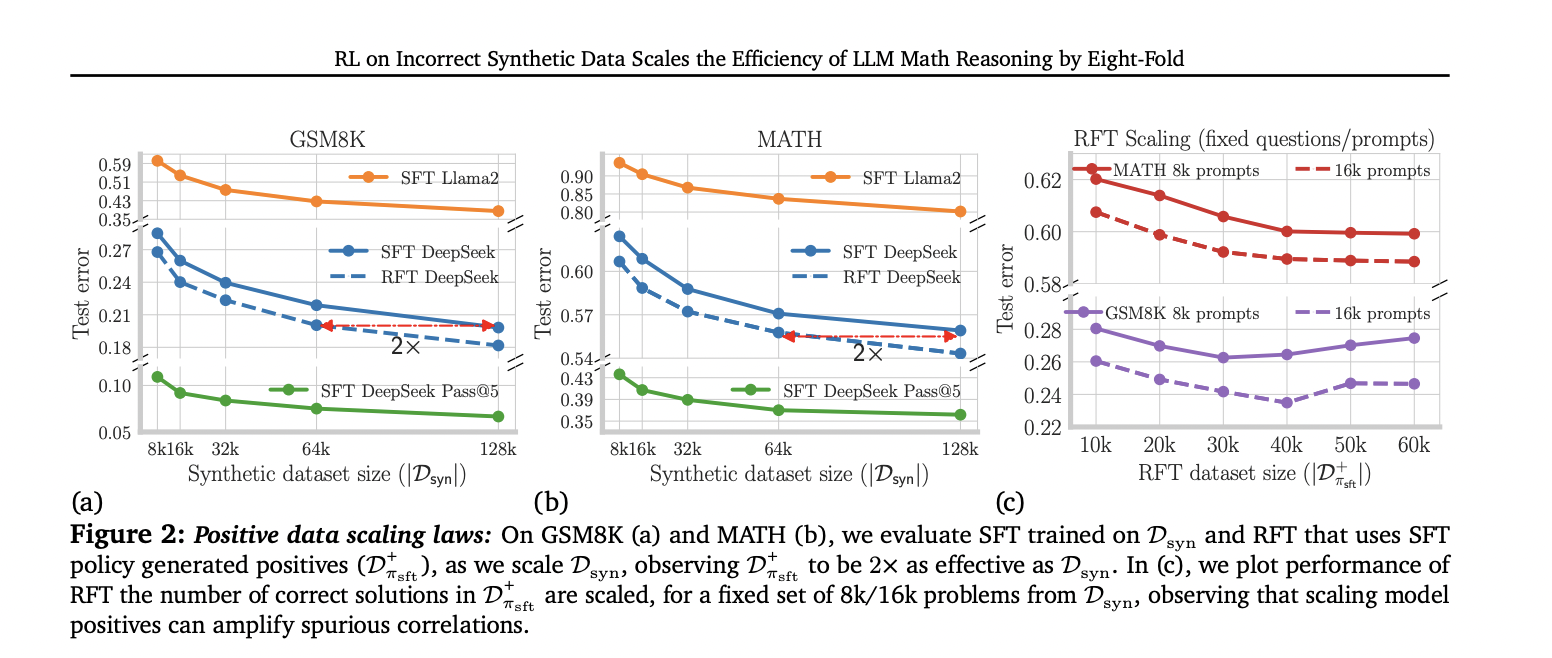
This study explores the impact of synthetic data on improving the mathematical reasoning capabilities of LLMs. It reveals that traditional methods using positive solutions from advanced models show limited efficiency. Self-generated positive data from fine-tuned 7B models improves efficiency by 2x, but may amplify reliance on spurious steps. Surprisingly, incorporating negative (incorrect) traces addresses these limitations. By using negative data to estimate incremental advantages and applying reinforcement learning techniques, the research demonstrates an 8x improvement in efficiency over synthetic data. This approach, using preference optimization objectives, significantly improves the mathematical reasoning capabilities of LLMs by effectively balancing positive and negative synthetic data.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter.
Join our Telegram Channel and LinkedIn GrAbove!.
If you like our work, you will love our Newsletter..
Don't forget to join our SubReddit of over 45,000 ml
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}