
Con la llegada de la inteligencia artificial (IA) generativa, los modelos de base (FM) pueden generar contenido, como responder preguntas, resumir texto y brindar aspectos destacados del documento fuente. Sin embargo, para la selección de modelos, existe una amplia variedad de proveedores de modelos, como amazon, Anthropic, AI21 Labs, Cohere y Meta, junto con formatos de datos discretos del mundo real en PDF, Word, texto, CSV, imagen, audio o video.
amazon Bedrock es un servicio totalmente administrado que facilita la creación y el escalado de aplicaciones de IA generativas. amazon Bedrock ofrece una selección de FM de alto rendimiento de empresas de IA líderes, como AI21 Labs, Anthropic, Cohere, Meta, Stability ai y amazon, a través de una única API. Le permite personalizar de forma privada los FM con sus datos mediante técnicas como el ajuste fino, la ingeniería rápida y la generación aumentada de recuperación (RAG), y crear agentes que ejecuten tareas utilizando sus sistemas empresariales y fuentes de datos, al tiempo que cumplen con los requisitos de seguridad y privacidad.
En esta publicación, le mostramos una solución para crear un chatbot conversacional de interfaz única que permite a los usuarios finales elegir entre diferentes modelos de lenguaje grande (LLM) y parámetros de inferencia para diversos formatos de datos de entrada. La solución utiliza amazon Bedrock para crear opciones y flexibilidad para mejorar la experiencia del usuario y comparar los resultados del modelo de diferentes opciones.
La base de código completa está disponible en GitHubjunto con una plantilla de AWS CloudFormation.
¿Qué es el trapo?
La generación aumentada por recuperación (RAG) puede mejorar el proceso de generación mediante el uso de los beneficios de la recuperación, lo que permite que un modelo de generación de lenguaje natural produzca respuestas más informadas y contextualmente adecuadas. Al incorporar información relevante de la recuperación al proceso de generación, la RAG tiene como objetivo mejorar la precisión, la coherencia y la informatividad del contenido generado.
La implementación de un sistema RAG eficaz requiere que varios componentes clave funcionen en armonía:
- Modelos de cimentacion – La base de una arquitectura RAG es un modelo de lenguaje entrenado previamente que se encarga de la generación de texto. amazon Bedrock incluye modelos de empresas líderes en inteligencia artificial como AI21 Labs, Anthropic, Cohere, Meta, Mistral ai y amazon, que poseen sólidas capacidades de comprensión y síntesis del lenguaje para participar en un diálogo conversacional.
- Tienda de vectores – En el centro de la funcionalidad de recuperación se encuentra una base de datos de almacenamiento de vectores que conserva las incrustaciones de documentos para la búsqueda por similitud. Esto permite la identificación rápida de información contextual relevante. AWS ofrece muchos servicios para sus requisitos de base de datos de vectores:
- Perdiguero – El módulo de recuperación utiliza el almacén de vectores para encontrar de manera eficiente documentos y pasajes pertinentes para aumentar las indicaciones.
- Incrustador – Para llenar el almacén de vectores, un modelo de incrustación codifica los documentos de origen en representaciones vectoriales que el recuperador puede consumir. Los modelos como amazon Titan Embeddings G1 – Text v1.2 son ideales para esta abstracción de texto a vector.
- Ingestión de documentos – Canalizaciones sólidas que incorporan, preprocesan y tokenizan documentos fuente, dividiéndolos en pasajes manejables para su integración y búsqueda eficiente. Para esta solución utilizamos el Marco LangChain para el preprocesamiento de documentos. Al orquestar estos componentes centrales mediante LangChain, los sistemas RAG permiten que los modelos de lenguaje accedan a un vasto conocimiento para una generación fundamentada.
Hemos gestionado completamente el soporte para nuestro flujo de trabajo de RAG de extremo a extremo mediante las bases de conocimiento para amazon Bedrock. Con las bases de conocimiento para amazon Bedrock, puede brindarles a los gerentes de cuentas y agentes información contextual de las fuentes de datos privadas de su empresa para que RAG brinde respuestas más relevantes, precisas y personalizadas.
Para equipar a los FM con información actualizada y patentada, las organizaciones utilizan RAG para obtener datos de las fuentes de datos de la empresa y enriquecer el mensaje para proporcionar respuestas más relevantes y precisas. Knowledge Bases for amazon Bedrock es una capacidad totalmente administrada que le ayuda a implementar todo el flujo de trabajo de RAG, desde la ingesta hasta la recuperación y el aumento rápido, sin tener que crear integraciones personalizadas con fuentes de datos ni administrar flujos de datos. La gestión del contexto de la sesión está integrada, por lo que su aplicación puede admitir fácilmente conversaciones de varios turnos.
Descripción general de la solución
Este chatbot está diseñado con RAG, lo que le permite ofrecer capacidades de conversación versátiles. La siguiente figura ilustra una interfaz de usuario de muestra de la interfaz de preguntas y respuestas con Streamlit y el flujo de trabajo.
Esta publicación proporciona una única interfaz de usuario con múltiples opciones para las siguientes capacidades:
- FM líderes disponibles a través de amazon Bedrock
- Parámetros de inferencia para cada uno de estos modelos.
- Formatos de entrada de datos de origen para RAG:
- Texto (PDF, CSV, Word)
- Enlace de página web
- Video de Youtube
- Audio
- Imagen escaneada
- PowerPoint
- Operación RAG utilizando el LLM, el parámetro de inferencia y las fuentes:
- Preguntas y respuestas
- Resumen: resumir, obtener puntos destacados, extraer texto
Hemos utilizado uno de los muchos cargadores de documentos de LangChain, Cargador de YouTube. El from_you_tube_url La función ayuda a extraer transcripciones y metadatos del video de YouTube.
Los documentos contienen dos atributos:
page_contentcon las transcripcionesmetadataCon información básica sobre el vídeo.
Se extrae el texto de la transcripción y, utilizando Langchain TextLoader, el documento se divide y se divide en fragmentos, y se crean incrustaciones, que luego se almacenan en el almacén de vectores.
El siguiente diagrama ilustra la arquitectura de la solución.
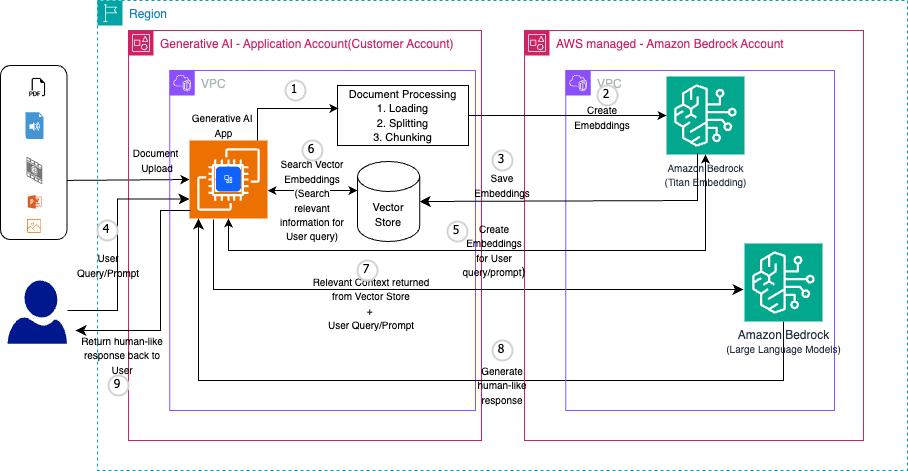
Prerrequisitos
Para implementar esta solución, debe tener los siguientes requisitos previos:
- Una cuenta de AWS con los permisos necesarios para iniciar la pila mediante AWS CloudFormation.
- amazon Elastic Compute Cloud (amazon EC2) que aloja la aplicación debe tener acceso a Internet para descargar todos los parches necesarios del sistema operativo y las bibliotecas relacionadas con la aplicación (python).
- Una comprensión básica de amazon Bedrock y FM.
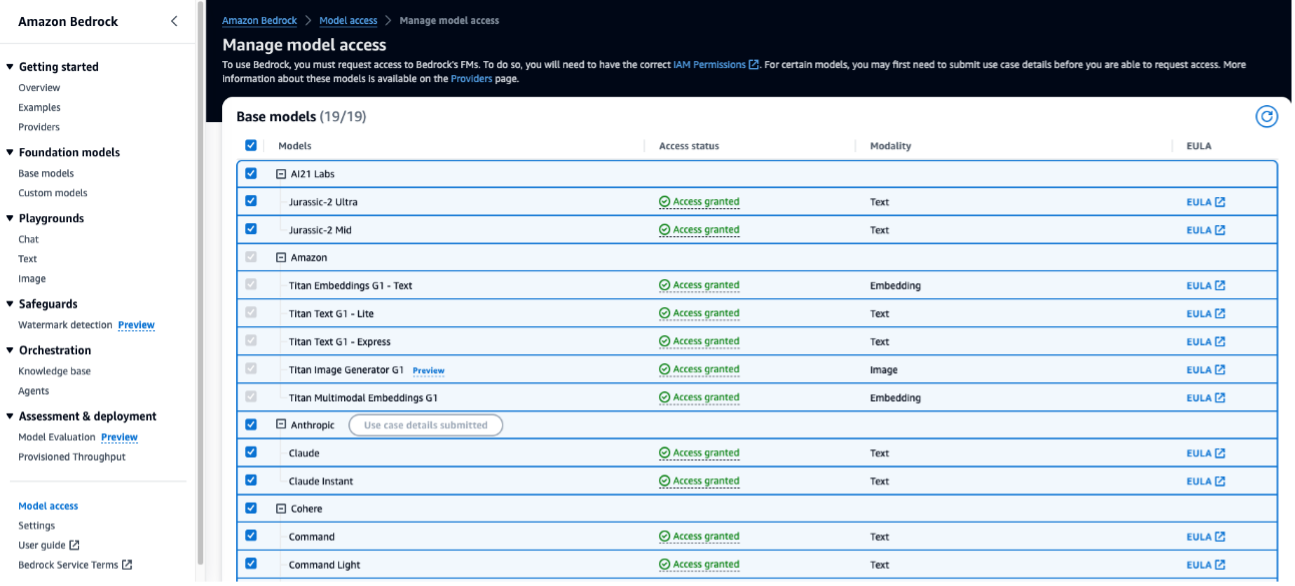
- Esta solución utiliza el modelo de incrustación de texto de amazon Titan. Asegúrese de que este modelo esté habilitado para su uso en amazon Bedrock. En la consola de amazon Bedrock, seleccione Acceso al modelo en el panel de navegación.
- Si las incorporaciones de texto de amazon Titan están habilitadas, el estado de acceso indicará Acceso concedido.
- Si el modelo no está disponible, habilite el acceso al modelo eligiendo Administrar el acceso al modeloseleccionando Incrustaciones multimodales Titan G1y eligiendo Solicitar acceso al modelo. El modelo está habilitado para su uso inmediatamente.
Implementar la solución
La plantilla de CloudFormation implementa una instancia de amazon Elastic Compute Cloud (amazon EC2) para alojar la aplicación Streamlit, junto con otros recursos asociados, como un rol de AWS Identity and Access Management (IAM) y un depósito de amazon Simple Storage Service (amazon S3). Para obtener más información sobre amazon Bedrock e IAM, consulte Cómo funciona amazon Bedrock con IAM.
En esta publicación, implementamos la aplicación Streamlit en una instancia EC2 dentro de una VPC, pero usted puede implementarla como una aplicación en contenedores utilizando una solución sin servidor con AWS Fargate. Discutimos esto con más detalle en la Parte 2.
Complete los siguientes pasos para implementar los recursos de la solución mediante AWS CloudFormation:
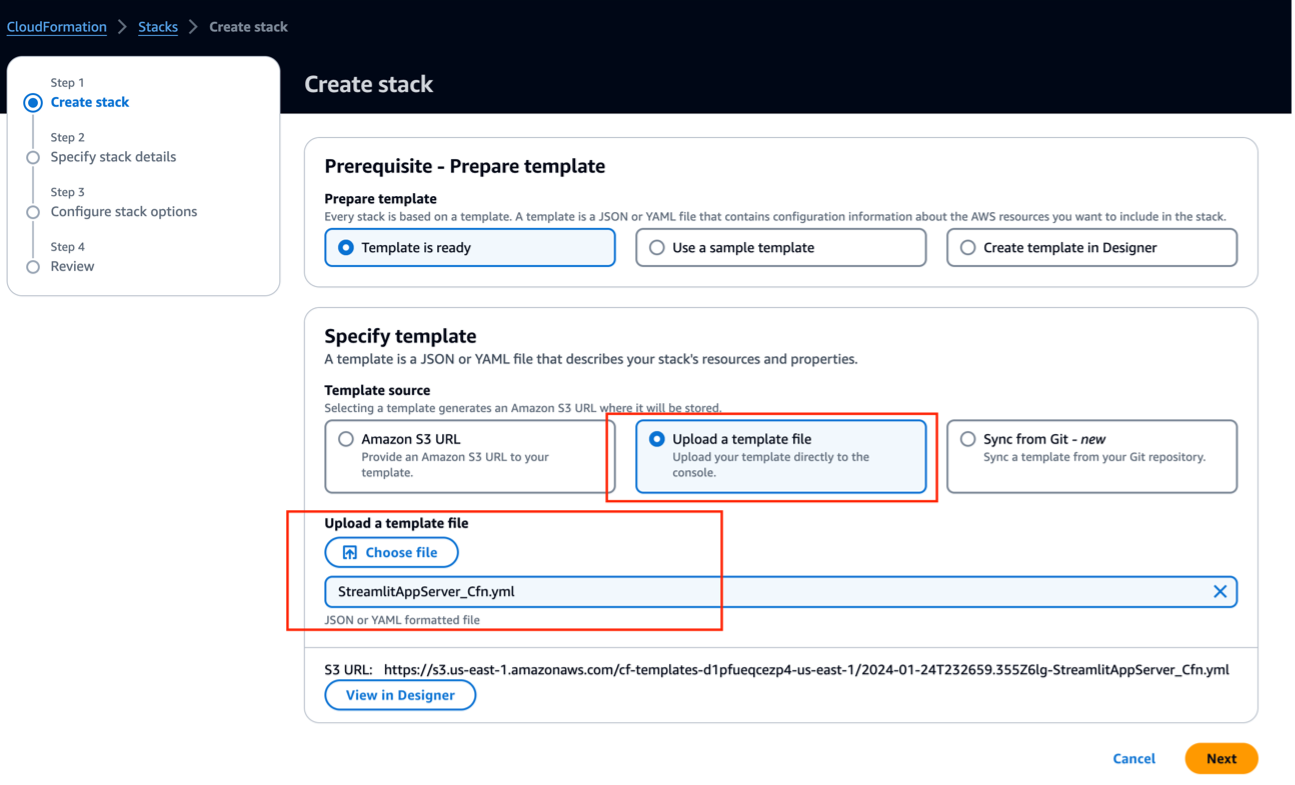
- Descargue la plantilla de CloudFormation Archivo StreamlitAppServer_Cfn.yml desde el Repositorio de GitHub.
- En AWS CloudFormation, cree una nueva pila.
- Para Preparar plantillaseleccionar La plantilla está lista.
- En el Especificar plantilla Sección, proporcione la siguiente información:
- Para Fuente de la plantillaseleccionar Cargar un archivo de plantilla.
- Elegir archivo y sube la plantilla que descargaste.
- Elegir Próximo.
- Para el nombre de la pilaingrese un nombre (para esta publicación,
StreamlitAppServer). - En el Parámetros sección, proporcione la siguiente información:
- Para Especifique el ID de VPC donde desea que se implemente su servidor de aplicaciones, ingrese el ID de VPC donde desea implementar este servidor de aplicaciones.
- Para VPCCidringrese el CIDR de la VPC que está utilizando.
- Para ID de subredingrese el ID de subred de la misma VPC.
- Para MYIPCidringrese la dirección IP de su computadora o estación de trabajo para que pueda abrir la aplicación Streamlit en su navegador local.
Puedes ejecutar el comando curl https://api.ipify.org en su terminal local para obtener su dirección IP.
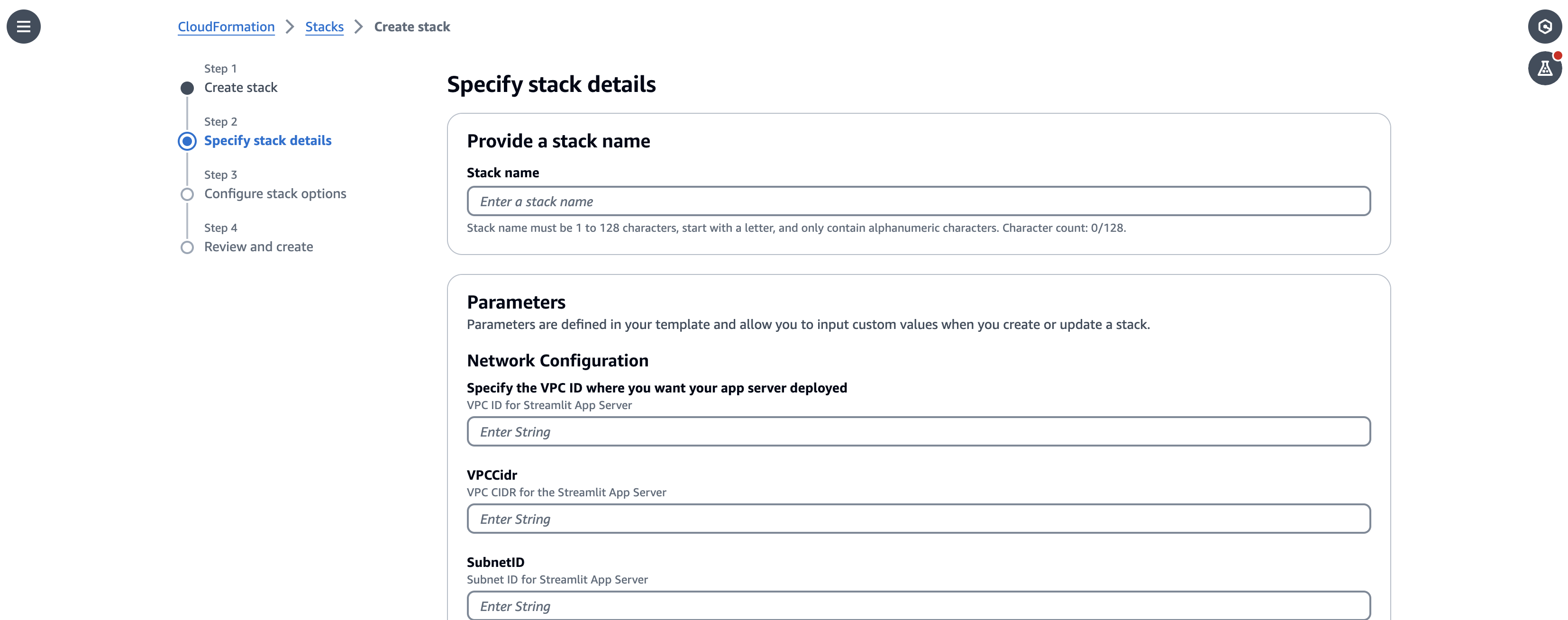

- Deje el resto de los parámetros como predeterminados.
- Elegir Próximo.
- En el Capacidades sección, seleccione la casilla de verificación de reconocimiento.
- Elegir Entregar.

Espere hasta que vea el estado de la pila como CREATE_COMPLETE.
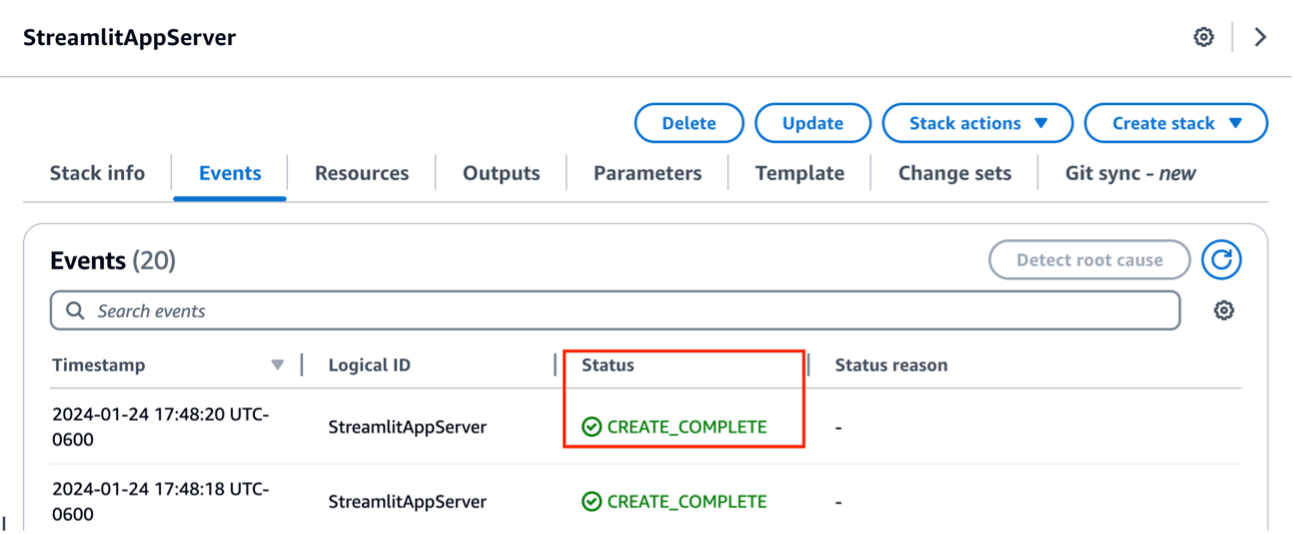
- Elige la pila Recursos para ver los recursos que lanzó como parte de la implementación de la pila.
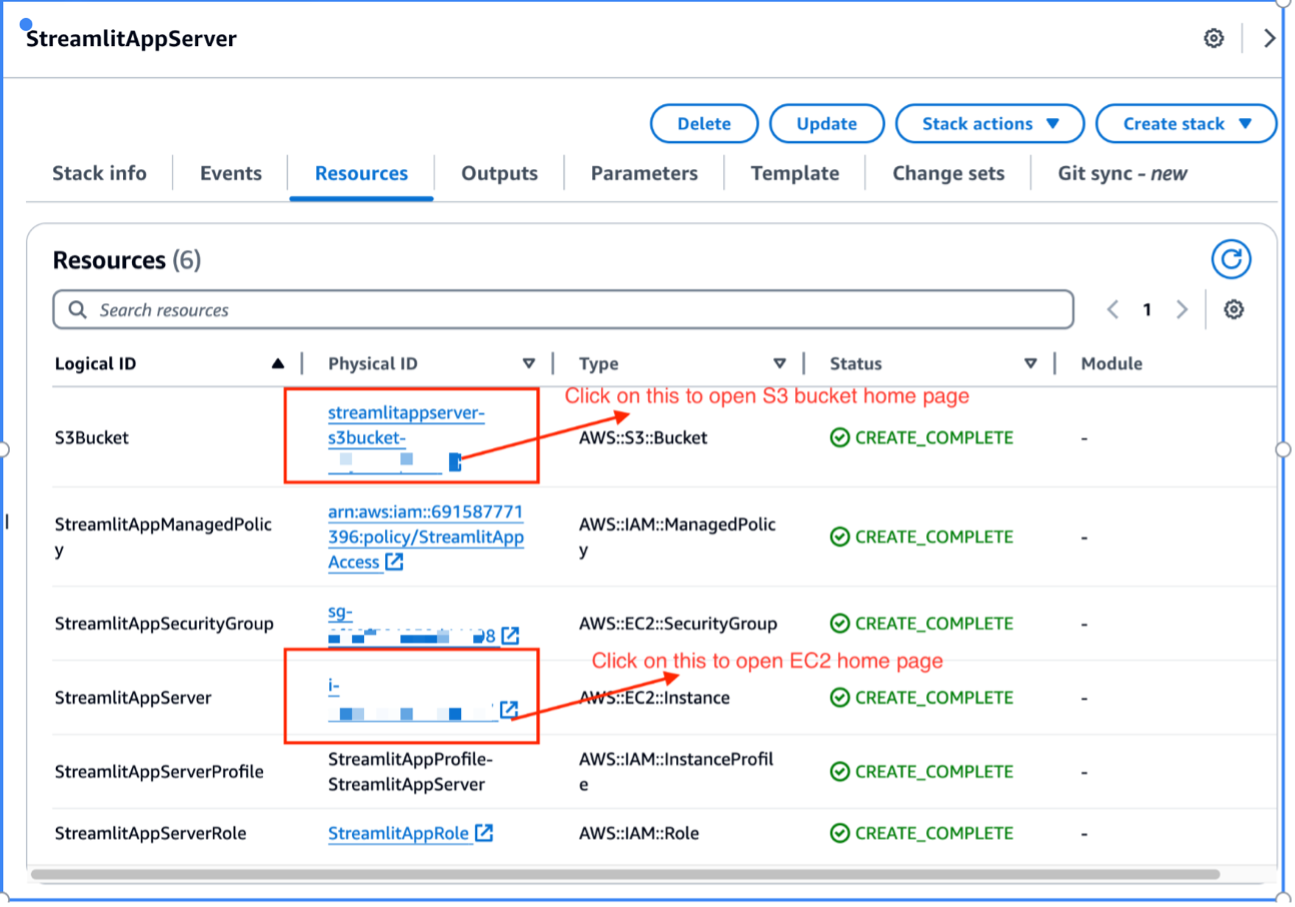
- Elija el enlace para que S3Bucket sea redirigido a la consola de amazon S3.
- Anote el nombre del depósito S3 para actualizar el script de implementación más adelante.
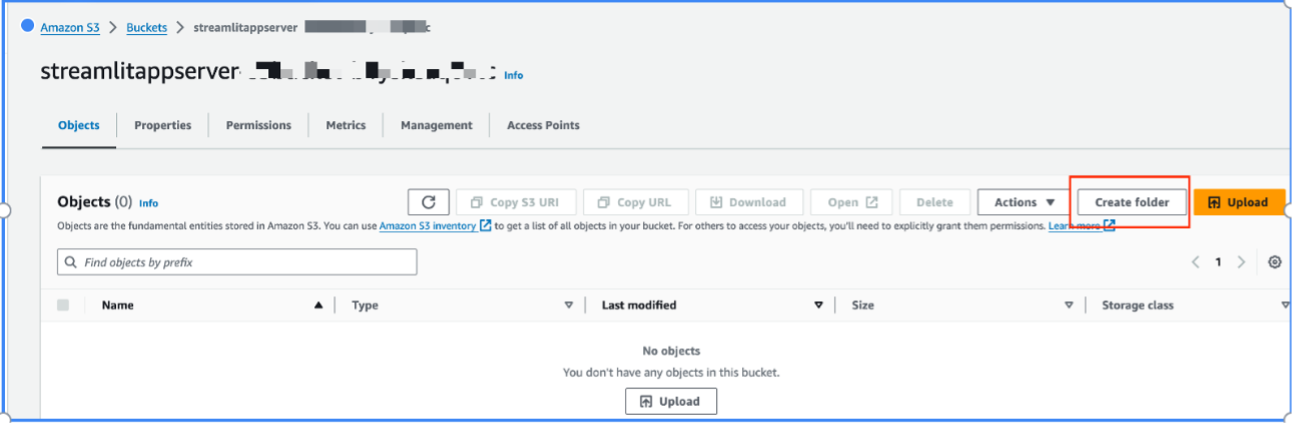
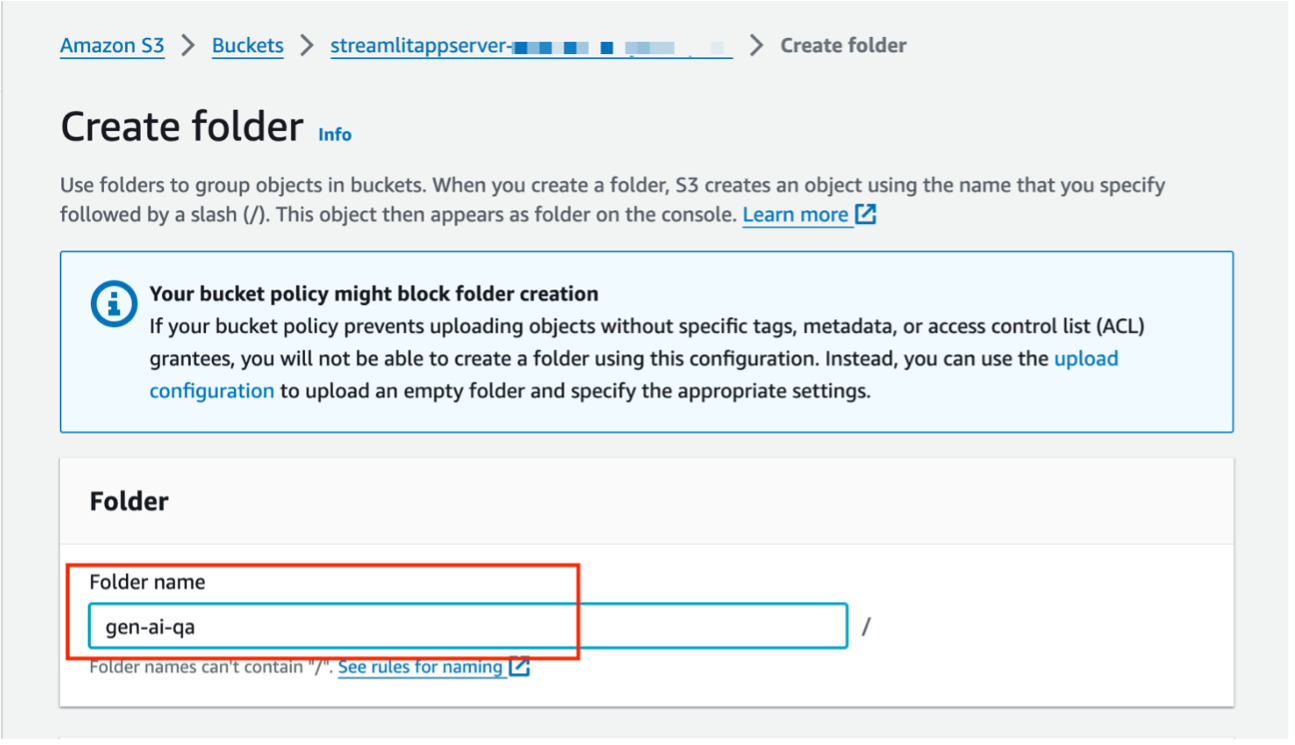
- Elegir Crear carpeta para crear una nueva carpeta.
- Para Nombre de la carpetaingresa un nombre (para esta publicación,
gen-ai-qa).
Asegúrese de seguir las mejores prácticas de seguridad de AWS para proteger los datos en amazon S3. Para obtener más detalles, consulte Las 10 mejores prácticas de seguridad para proteger los datos en amazon S3.
- Regresar a la pila Recursos pestaña y elija el enlace a StreamlitAppServer para ser redirigido a la consola de amazon EC2.
- Seleccionar
StreamlitApp_Severy elige Conectar.
- Seleccionar

Esto abrirá una nueva página con varias formas de conectarse a la instancia EC2 iniciada.
- Para esta solución, seleccione Conectar utilizando EC2 Instance Connect, luego elija Conectar.
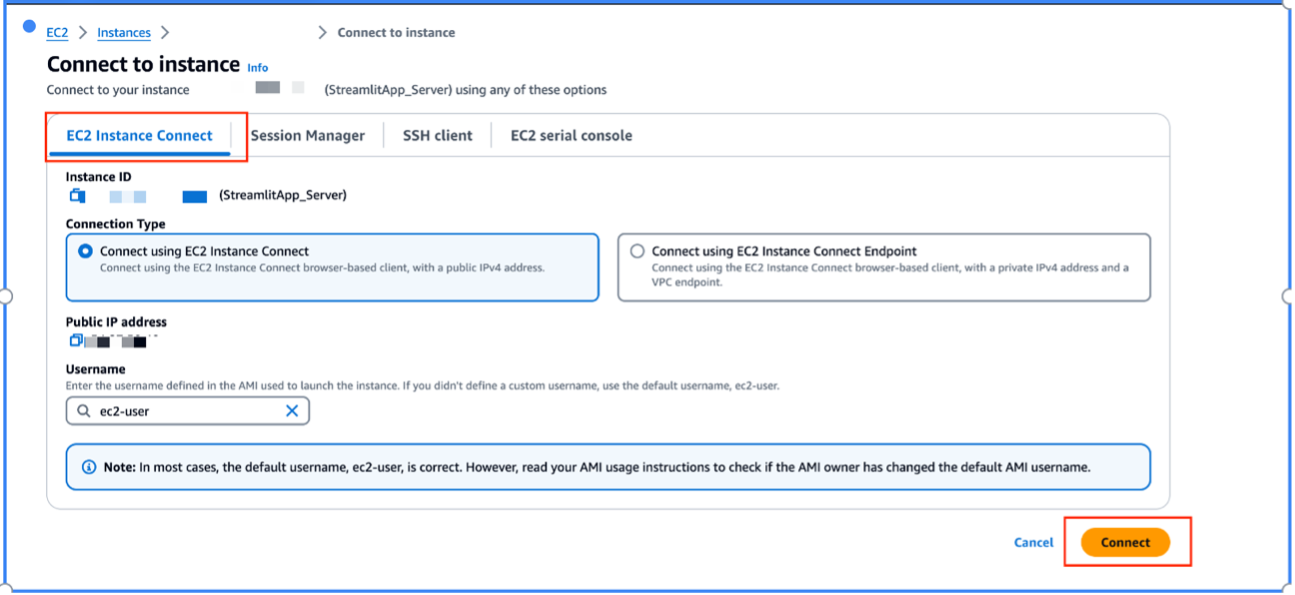
Esto abrirá una sesión de amazon EC2 en su navegador.
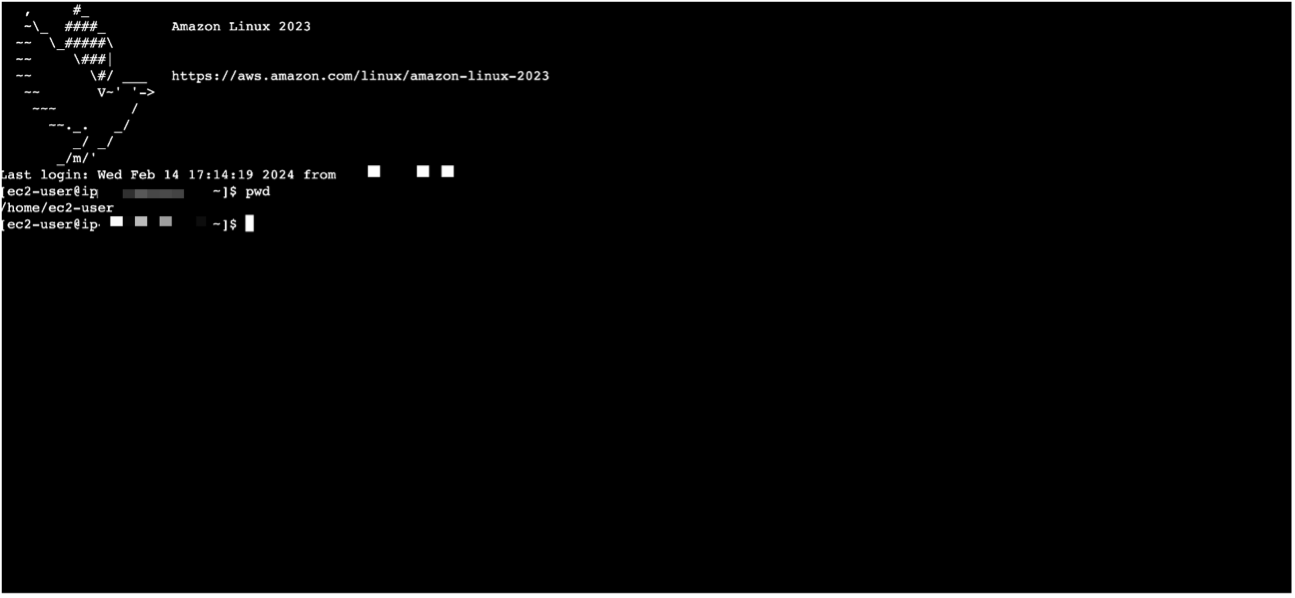
- Ejecute el siguiente comando para monitorear el progreso de todas las bibliotecas relacionadas con Python que se instalan como parte de los datos del usuario:
- Cuando veas el mensaje
Finished running user data...puedes salir de la sesión pulsando Ctrl + C.
Esto tarda unos 15 minutos en completarse.

- Ejecute los siguientes comandos para iniciar la aplicación:
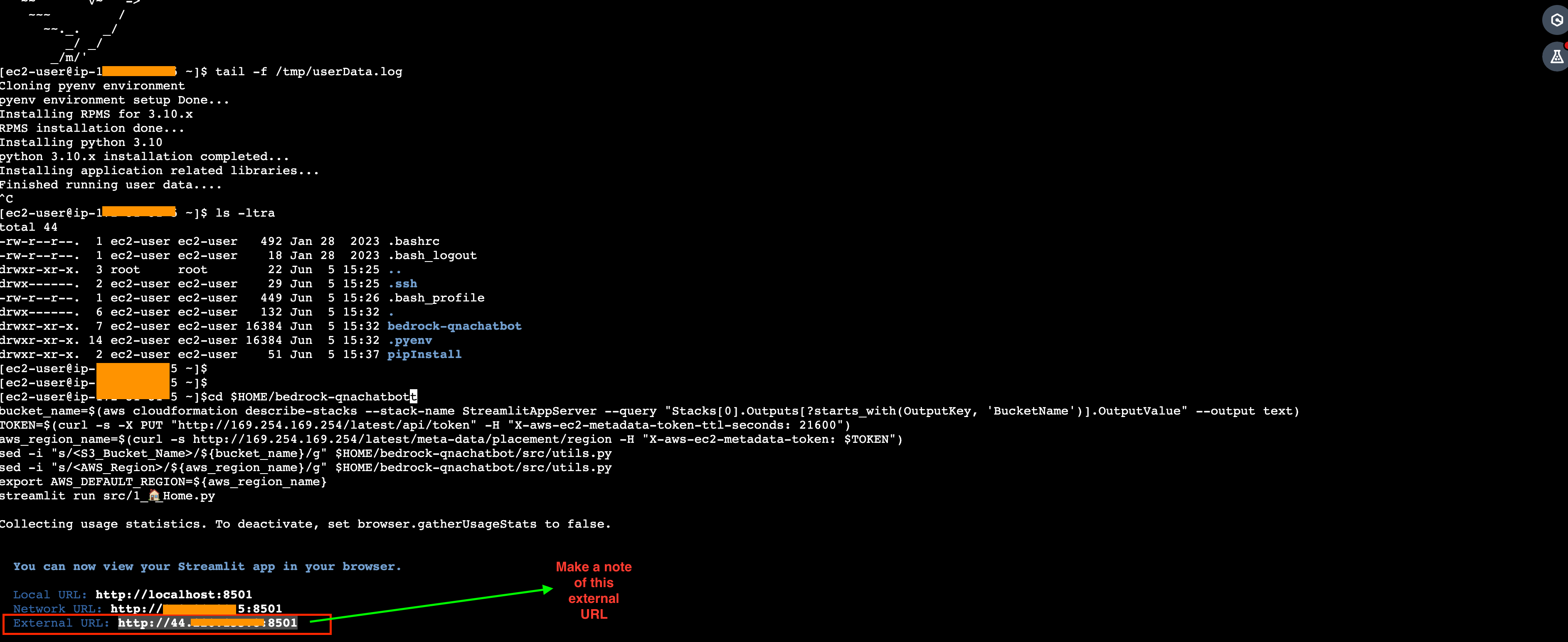
- Tome nota del valor de la URL externa.
- Si por casualidad sale de la sesión (o la aplicación se detiene), puede reiniciar la aplicación ejecutando el mismo comando resaltado en el Paso 18.
Utilice el chatbot
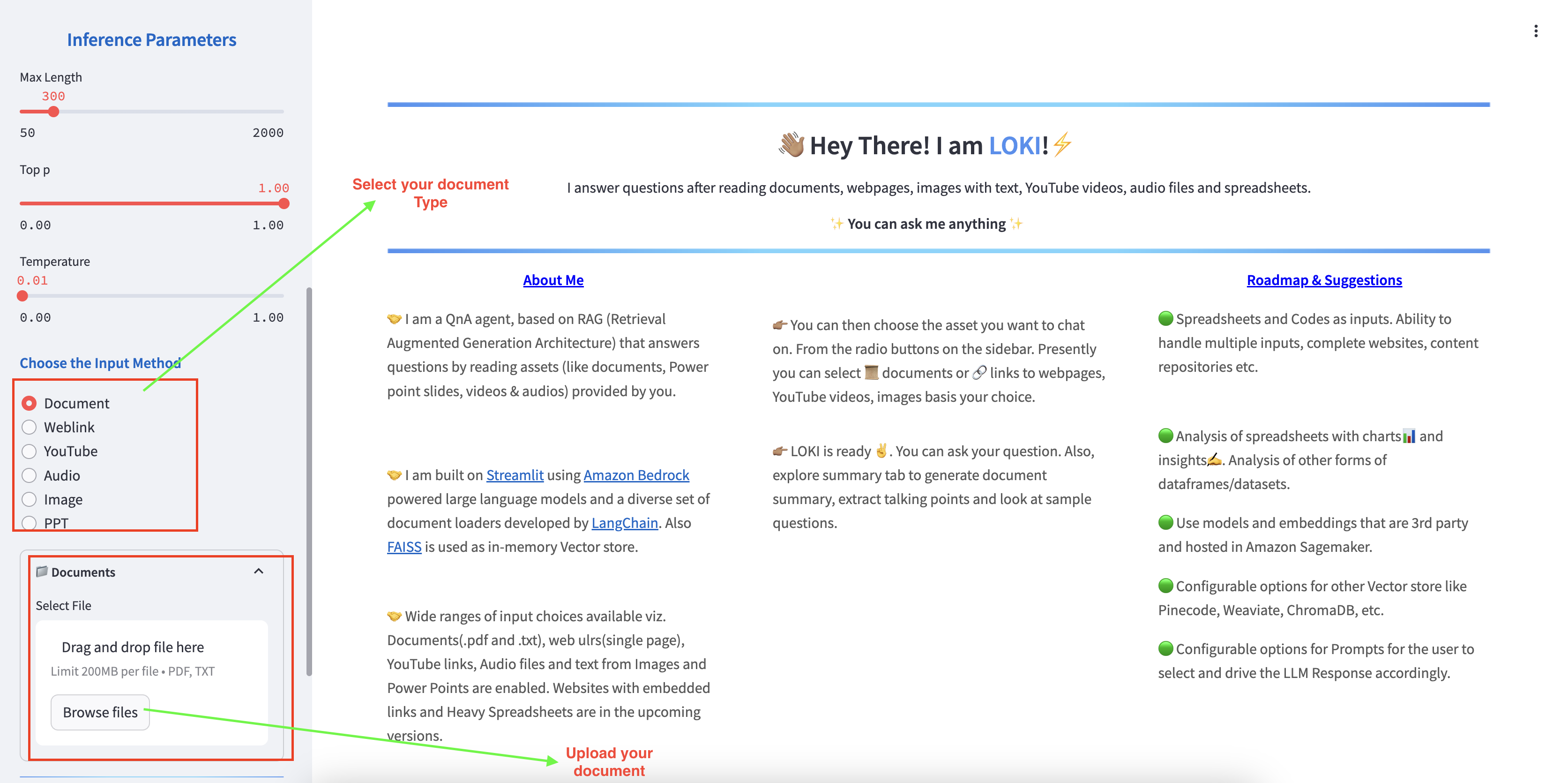
Utilice la URL externa que copió en el paso anterior para acceder a la aplicación.
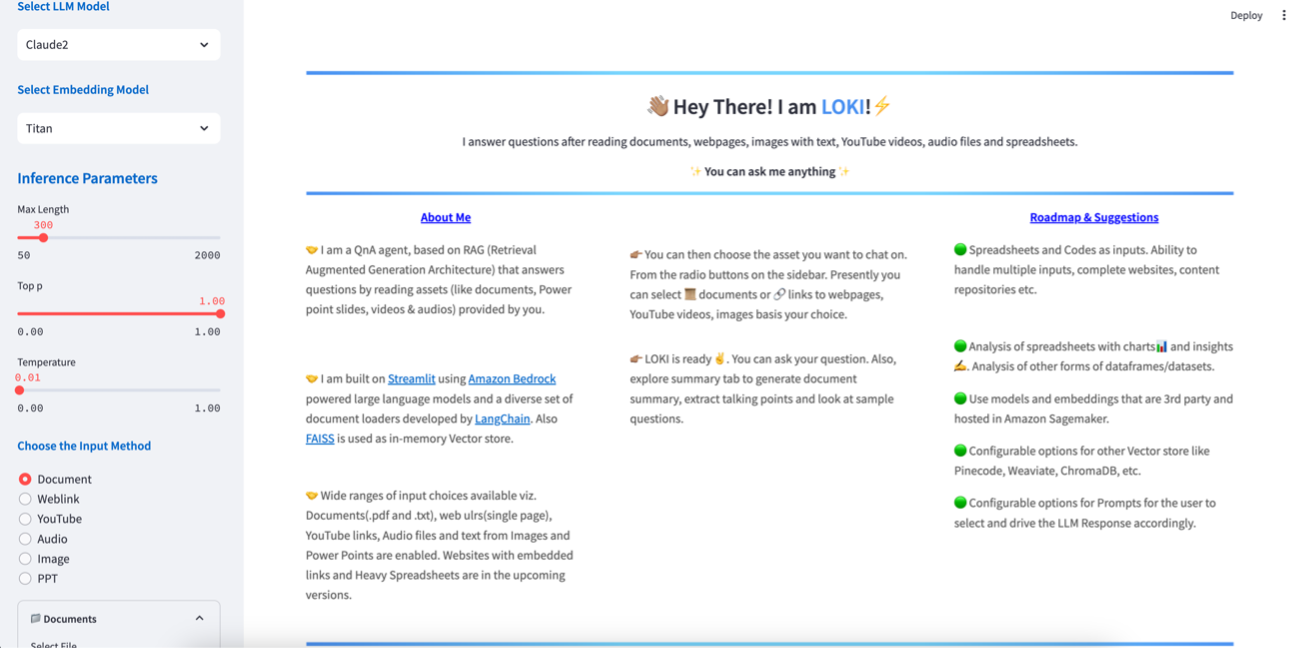
Puede cargar su archivo para comenzar a usar el chatbot para preguntas y respuestas.
Limpiar
Para evitar incurrir en cargos futuros, elimine los recursos que creó:
- Vacíe el contenido del depósito S3 que creó como parte de esta publicación.
- Elimina la pila CloudFormation que creaste como parte de esta publicación.
Conclusión
En esta publicación, le mostramos cómo crear un chatbot de preguntas y respuestas que puede responder preguntas en todo el corpus de documentos de una empresa con opciones de FM disponibles dentro de amazon Bedrock, dentro de una única interfaz.
En la Parte 2, le mostramos cómo usar bases de conocimiento para amazon Bedrock con bases de datos vectoriales de nivel empresarial como OpenSearch Service, amazon Aurora PostgreSQL, MongoDB Atlas, Weaviate y Pinecone con su chatbot de preguntas y respuestas.
Sobre los autores
 Anand Mandilwar es arquitecto de soluciones empresariales en AWS. Trabaja con clientes empresariales ayudándolos a innovar y transformar sus negocios en AWS. Le apasiona la automatización en torno al funcionamiento de la nube, el aprovisionamiento de infraestructura y la optimización de la nube. También le gusta la programación en Python. En su tiempo libre, le gusta perfeccionar sus habilidades fotográficas, especialmente en el área de retratos y paisajes.
Anand Mandilwar es arquitecto de soluciones empresariales en AWS. Trabaja con clientes empresariales ayudándolos a innovar y transformar sus negocios en AWS. Le apasiona la automatización en torno al funcionamiento de la nube, el aprovisionamiento de infraestructura y la optimización de la nube. También le gusta la programación en Python. En su tiempo libre, le gusta perfeccionar sus habilidades fotográficas, especialmente en el área de retratos y paisajes.
 Naga Bharathi Challa es arquitecto de soluciones en el equipo civil federal de EE. UU. en amazon Web Services (AWS). Trabaja en estrecha colaboración con los clientes para utilizar eficazmente los servicios de AWS para los casos de uso de su misión, brindando mejores prácticas arquitectónicas y orientación sobre una amplia gama de servicios. Fuera del trabajo, le gusta pasar tiempo con la familia y difundir el poder de la meditación.
Naga Bharathi Challa es arquitecto de soluciones en el equipo civil federal de EE. UU. en amazon Web Services (AWS). Trabaja en estrecha colaboración con los clientes para utilizar eficazmente los servicios de AWS para los casos de uso de su misión, brindando mejores prácticas arquitectónicas y orientación sobre una amplia gama de servicios. Fuera del trabajo, le gusta pasar tiempo con la familia y difundir el poder de la meditación.






{kind=link}