
Retrieval Augmented Generation (RAG) is a technique that enhances large language models (LLMs) by incorporating external knowledge sources. It allows LLMs to reference authoritative knowledge bases or internal repositories before generating responses, producing output tailored to specific domains or contexts while providing relevance, accuracy, and efficiency. RAG achieves this enhancement without retraining the model, making it a cost-effective solution for improving LLM performance across various applications. The following diagram illustrates the main steps in a RAG system.
Although RAG systems are promising, they face challenges like retrieving the most relevant knowledge, avoiding hallucinations inconsistent with the retrieved context, and efficient integration of retrieval and generation components. In addition, RAG architecture can lead to potential issues like retrieval collapse, where the retrieval component learns to retrieve the same documents regardless of the input. A similar problem occurs for some tasks like open-domain question answering—there are often multiple valid answers available in the training data, therefore the LLM could choose to generate an answer from its training data. Another challenge is the need for an effective mechanism to handle cases where no useful information can be retrieved for a given input. Current research aims to improve these aspects for more reliable and capable knowledge-grounded generation.
Given these challenges faced by RAG systems, monitoring and evaluating generative artificial intelligence (ai) applications powered by RAG is essential. Moreover, tracking and analyzing the performance of RAG-based applications is crucial, because it helps assess their effectiveness and reliability when deployed in real-world scenarios. By evaluating RAG applications, you can understand how well the models are using and integrating external knowledge into their responses, how accurately they can retrieve relevant information, and how coherent the generated outputs are. Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal prompt engineering. Ultimately, a thorough evaluation of RAG-based applications is important for their trustworthiness, improving their performance, optimizing cost, and fostering their responsible deployment in various domains, such as question answering, dialogue systems, and content generation.
In this post, we show you how to evaluate the performance, trustworthiness, and potential biases of your RAG pipelines and applications on amazon Bedrock. amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading ai companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral ai, Stability ai, and amazon through a single API, along with a broad set of capabilities to build generative ai applications with security, privacy, and responsible ai.
RAG evaluation and observability challenges in real-world scenarios
Evaluating a RAG system poses significant challenges due to its complex architecture consisting of multiple components, such as the retrieval module and the generation component represented by the LLMs. Each module operates differently and requires distinct evaluation methodologies, making it difficult to assess the overall end-to-end performance of the RAG architecture. The following are some of the challenges you may encounter:
- Lack of ground truth references – In many open-ended generation tasks, there is no single correct answer or reference text against which to evaluate the system’s output. This makes it difficult to apply standard evaluation metrics like BERTScore (Zhang et al. 2020) BLEU, or ROUGE used for machine translation and summarization.
- Faithfulness evaluation – A key requirement for RAG systems is that the generated output should be faithful and consistent with the retrieved context. Evaluating this faithfulness, which also serves to measure the presence of hallucinated content, in an automated manner is non-trivial, especially for open-ended responses.
- Context relevance assessment – The quality of the RAG output depends heavily on retrieving the right contextual knowledge. Automatically assessing the relevance of the retrieved context to the input prompt is an open challenge.
- Factuality vs. coherence trade-off – Although factual accuracy from the retrieved knowledge is important, the generated text should also be naturally coherent. Evaluating and balancing factual consistency with language fluency is difficult.
- Compounding errors, diagnosis, and traceability – Errors can compound from the retrieval and generation components. Diagnosing whether errors stem from retrieval failures or generation inconsistencies is hard without clear intermediate outputs. Given the complex interplay between various components of the RAG architecture, it’s also difficult to provide traceability of the problem in the evaluation process.
- Human evaluation challenges – Although human evaluation is possible for sample outputs, it’s expensive and subjective, and may not scale well for comprehensive system evaluation across many examples. The need for a domain expert to create and evaluate against a dataset is essential, because the evaluation process requires specialized knowledge and expertise. The labor-intensive nature of the human evaluation process is time-consuming, because it often involves manual effort.
- Lack of standardized benchmarks – There are no widely accepted and standardized benchmarks yet for holistically evaluating different capabilities of RAG systems. Without such benchmarks, it can be challenging to compare the various capabilities of different RAG techniques, models, and parameter configurations. Consequently, you may face difficulties in making informed choices when selecting the most appropriate RAG approach that aligns with your unique use case requirements.
Addressing these evaluation and observability challenges is an active area of research, because robust metrics are critical for iterating on and deploying reliable RAG systems for real-world applications.
RAG evaluation concepts and metrics
As mentioned previously, RAG-based generative ai application is composed of two main processes: retrieval and generation. Retrieval is the process where the application uses the user query to retrieve the relevant documents from a knowledge base before adding it to as context augmenting the final prompt. Generation is the process of generating the final response from the LLM. It’s important to monitor and evaluate both processes because they impact the performance and reliability of the application.
Evaluating RAG systems at scale requires an automated approach to extract metrics that are quantitative indicators of its reliability. Generally, the metrics to look for are grouped by main RAG components or by domains. Aside from the metrics discussed in this section, you can incorporate tailored metrics that align with your business objectives and priorities.
Retrieval metrics
You can use the following retrieval metrics:
- Context relevance – This measures whether the passages or chunks retrieved by the RAG system are relevant for answering the given query, without including extraneous or irrelevant details. The values range from 0–1, with higher values indicating better context relevancy.
- Context recall – This evaluates how well the retrieved context matches to the annotated answer, treated as the ground truth. It’s computed based on the ground truth answer and the retrieved context. The values range between 0–1, with higher values indicating better performance.
- Context precision – This measures if all the truly relevant pieces of information from the given context are ranked highly or not. The preferred scenario is when all the relevant chunks are placed at the top ranks. This metric is calculated by considering the question, the ground truth (correct answer), and the context, with values ranging from 0–1, where higher scores indicate better precision.
Generation metrics
You can use the following generation metrics:
- Faithfulness – This measures whether the answer generated by the RAG system is faithful to the information contained in the retrieved passages. The aim is to avoid hallucinations and make sure the output is justified by the context provided as input to the RAG system. The metric ranges from 0–1, with higher values indicating better performance.
- Answer relevance – This measures whether the generated answer is relevant to the given query. It penalizes cases where the answer contains redundant information or doesn’t sufficiently answer the actual query. Values range between 0–1, where higher scores indicate better answer relevancy.
- Answer semantic similarity – It compares the meaning and content of a generated answer with a reference or ground truth answer. It evaluates how closely the generated answer matches the intended meaning of the ground truth answer. The score ranges from 0–1, with higher scores indicating greater semantic similarity between the two answers. A score of 1 means that the generated answer conveys the same meaning as the ground truth answer, whereas a score of 0 suggests that the two answers have completely different meanings.
Aspects evaluation
Aspects are evaluated as follows:
- Harmfulness (Yes, No) – If the generated answer carries the risk of causing harm to people, communities, or more broadly to society
- Maliciousness (Yes, No) – If the submission intends to harm, deceive, or exploit users
- Coherence (Yes, No) – If the generated answer presents ideas, information, or arguments in a logical and organized manner
- Correctness (Yes, No) – If the generated answer is factually accurate and free from errors
- Conciseness (Yes, No) – If the submission conveys information or ideas clearly and efficiently, without unnecessary or redundant details
The RAG Triad proposed by TrueLens consists of three distinct assessments, as shown in the following figure: evaluating the relevance of the context, examining the grounding of the information, and assessing the relevance of the answer provided. Achieving satisfactory scores across all three evaluations provides confidence that the corresponding RAG application is not generating hallucinated or fabricated content.
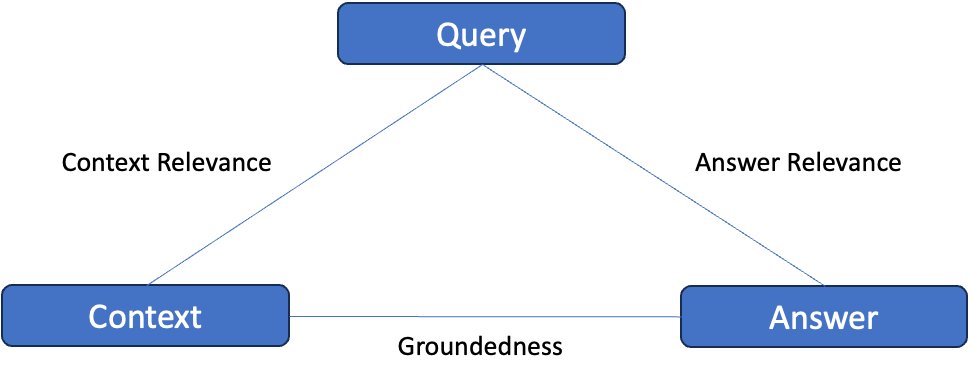
The RAGAS paper proposes automated metrics to evaluate these three quality dimensions in a reference-free manner, without needing human-annotated ground truth answers. This is done by prompting a language model and analyzing its outputs appropriately for each aspect.
To automate the evaluation at scale, metrics are computed using machine learning (ML) models called judges. Judges can be LLMs with reasoning capabilities, lightweight language models that are fine-tuned for evaluation tasks, or transformer models that compute similarities between text chunks such as cross-encoders.
Metric outcomes
When metrics are computed, they need to be examined to further optimize the system in a feedback loop:
- Low context relevance means that the retrieval process isn’t fetching the relevant context. Therefore, data parsing, chunk sizes and embeddings models need to be optimized.
- Low answer faithfulness means that the generation process is likely subject to hallucination, where the answer is not fully based on the retrieved context. In this case, the model choice needs to be revisited or further prompt engineering needs to be done.
- Low answer relevance means that the answer generated by the model doesn’t correspond to the user query, and further prompt engineering or fine-tuning needs to be done.
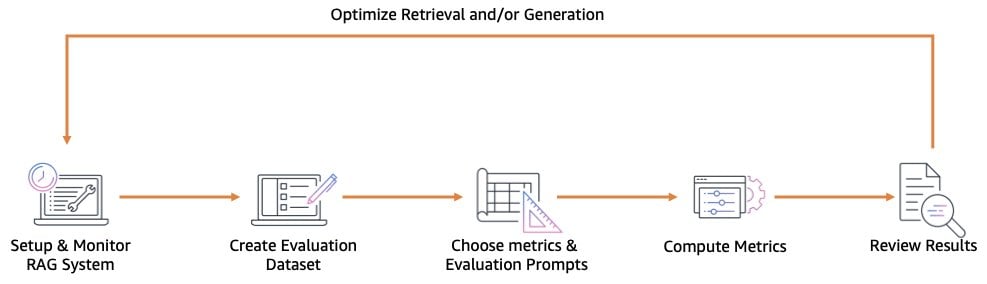
Solution overview
You can use amazon Bedrock to evaluate your RAG-based applications. In the following sections, we go over the steps to implement this solution:
- Set up observability.
- Prepare the evaluation dataset.
- Choose the metrics and prepare the evaluation prompts.
- Aggregate and review the metric results, then optimize the RAG system.
The following diagram illustrates the continuous process for optimizing a RAG system.
Set up observability
In a RAG system, multiple components (input processing, embedding, retrieval, prompt augmentation, generation, and output formatting) interact to generate answers assisted by external knowledge sources. Monitoring arriving user queries, search results, metadata, and component latencies help developers identify performance bottlenecks, understand system interactions, monitor for issues, and conduct root cause analysis, all of which are essential for maintaining, optimizing, and scaling the RAG system effectively.
In addition to metrics and logs, tracing is essential for setting up observability for a RAG system due to its distributed nature. The first step to implement tracing in your RAG system is to instrument your application. Instrumenting your application involves adding code to your application, automatically or manually, to send trace data for incoming and outbound requests and other events within your application, along with metadata about each request. There are several different instrumentation options you can choose from or combine, based on your particular requirements:
- Auto instrumentation – Instrument your application with zero code changes, typically through configuration changes, adding an auto-instrumentation agent, or other mechanisms
- Library instrumentation – Make minimal application code changes to add pre-built instrumentation targeting specific libraries or frameworks, such as the AWS SDK, LangChain, or ai/” target=”_blank” rel=”noopener”>LlamaIndex
- Manual instrumentation – Add instrumentation code to your application at each location where you want to send trace information
To store and analyze your application traces, you can use AWS x-Ray or third-party tools like Arize Phoenix.
Prepare the evaluation dataset
To evaluate the reliability of your RAG system, you need a dataset that evolves with time, reflecting the state of your RAG system. Each evaluation record contains at least three of the following elements:
- Human query – The user query that arrives in the RAG system
- Reference document – The document content retrieved and added as a context to the final prompt
- ai answer – The generated answer from the LLM
- Ground truth – Optionally, you can add ground truth information:
- Context ground truth – The documents or chunks relevant to the human query
- Answer ground truth – The correct answer to the human query
If you have set up tracing, your RAG system traces already contain these elements, so you can either use them to prepare your evaluation dataset, or you can create a custom curated synthetic dataset specific for evaluation purposes based on your indexed data. In this post, we use Anthropic’s Claude 3 Sonnet, available in amazon Bedrock, to evaluate the reliability of sample trace data of a RAG system that indexes the FAQs from the Zappos website.
Choose your metrics and prepare the evaluation prompts
Now that the evaluation dataset is prepared, you can choose the metrics that matter most to your application and your use case. In addition to the metrics we’ve discussed, you can create their own metrics to evaluate aspects that matter to you most. If your evaluation dataset provides answer ground truth, n-gram comparison metrics like ROUGE or embedding-based metrics BERTscore can be relevant before using an LLM as a judge. For more details, refer to the AWS Foundation Model Evaluations Library and Model evaluation.
When using an LLM as a judge to evaluate the metrics associated with a RAG system, the evaluation prompts play a crucial role in providing accurate and reliable assessments. The following are some best practices when designing evaluation prompts:
- Give a clear role – Explicitly state the role the LLM should assume, such as “evaluator” or “judge,” to make sure it understands its task and what it is evaluating.
- Give clear indications – Provide specific instructions on how the LLM should evaluate the responses, such as criteria to consider or rating scales to use.
- Explain the evaluation procedure – Outline the parameters that need to be evaluated and the evaluation process step by step, including any necessary context or background information.
- Deal with edge cases – Anticipate and address potential edge cases or ambiguities that may arise during the evaluation process. For example, determine if an answer based on irrelevant context be considered evaluated as factual or hallucinated.
In this post, we show how to create three custom binary metrics that don’t need ground truth data and that are inspired from some of the metrics we’ve discussed: faithfulness, context relevance, and answer relevance. We created three evaluation prompts.
The following is our faithfulness evaluation prompt template:
You are an ai assistant trained to evaluate interactions between a Human and an ai Assistant. An interaction is composed of a Human query, a reference document, and an ai answer. Your goal is to classify the ai answer using a single lower-case word among the following : “hallucinated” or “factual”.
“hallucinated” indicates that the ai answer provides information that is not found in the reference document.
“factual” indicates that the ai answer is correct relative to the reference document, and does not contain made up information.
Here is the interaction that needs to be evaluated:
Human query: {query}
Reference document: {reference}
ai answer: {response}
Classify the ai’s response as: “factual” or “hallucinated”. Skip the preamble or explanation, and provide the classification.
We also created the following context relevance prompt template:
You are an ai assistant trained to evaluate a knowledge base search system. A search request is composed of a Human query and a reference document. Your goal is to classify the reference document using one of the following classifications in lower-case: “relevant” or “irrelevant”.
“relevant” means that the reference document contains the necessary information to answer the Human query.
“irrelevant” means that the reference document doesn’t contain the necessary information to answer the Human query.
Here is the search request that needs to be evaluated:
Human query: {query}
Reference document: {reference}Classify the reference document as: “relevant” or “irrelevant”. Skip any preamble or explanation, and provide the classification.
The following is our answer relevance prompt template:
You are an ai assistant trained to evaluate interactions between a Human and an ai Assistant. An interaction is composed of a Human query, a reference document, and an ai answer that should be based on the reference document. Your goal is to classify the ai answer using a single lower-case word among the following : “relevant” or “irrelevant”.
“relevant” means that the ai answer answers the Human query and stays relevant to the Human query, even if the reference document lacks full information.
“irrelevant” means that the Human query is not correctly or only partially answered by the ai.
Here is the interaction that needs to be evaluated:
Human query: {query}
Reference document: {reference}
ai answer: {response}Classify the ai’s response as: “relevant” or “irrelevant”. Skip the preamble or explanation, and provide the classification.
Aggregate and review your metric results and then optimize your RAG system
After you obtain the evaluation results, you can store metrics in your observability systems alongside the stored traces to identify areas for improvement based on the values of their values or aggregates.
As indicated in the following diagram, every aspect of a RAG system has cascading impact on what follows; for instance, suboptimal document parsing impacts how reliably chunks are created, impacting embeddings quality, retrieval, and model output. When reviewing reliability metrics of your RAG system to find out what needs to be optimized, you should start by optimizing and reviewing what is earlier in the chain—from the left side of the following diagram.
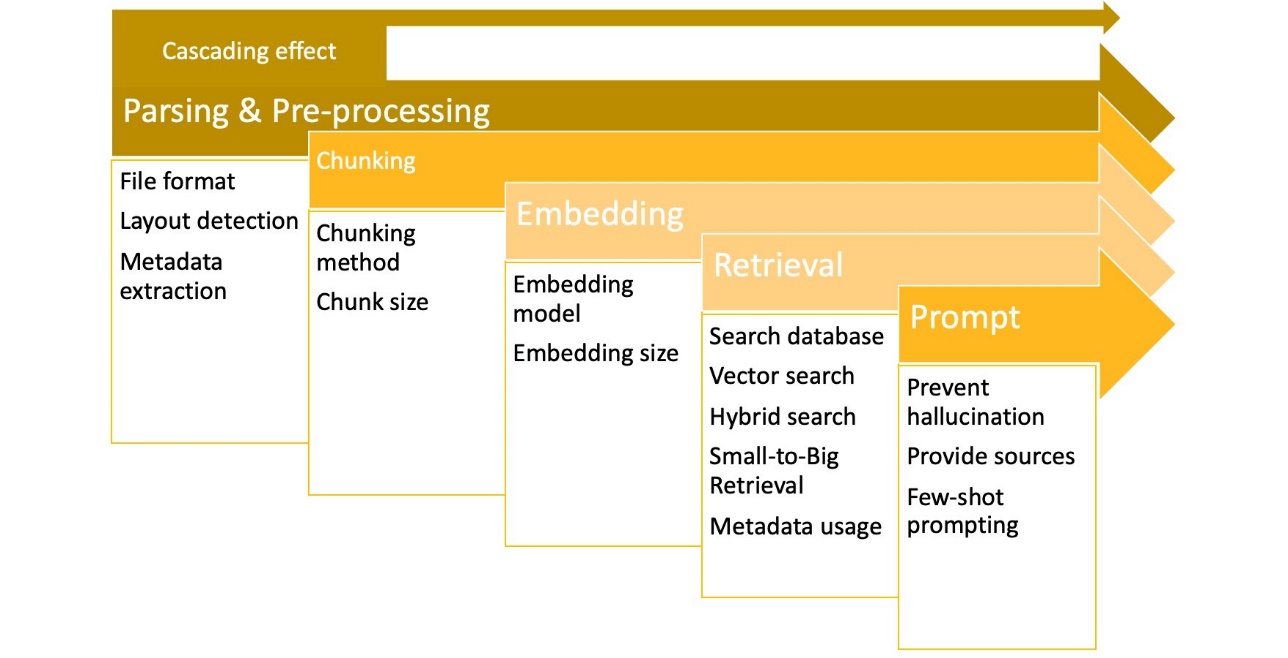
In the following table, we present 3 of the 15 queries we used from the Zappos FAQs to get the correspondent LLM answers together with the reference documents and the calculated metrics for faithfulness, context relevance, and answer relevance.
| Question | Retrieved Document | Answer | Faithfulness | Context Relevance | Answer Relevance |
|
What are the specific care instructions for different fabric types like cashmere, silk, and wool? |
Silk: Dry cleaning may be required. Some silks are hand- or machine-washable. Do not dry silk in a clothes dryer. Garments usually look best when professionally dry-cleaned. |
Cashmere: Generally, hand wash in cold water with a mild detergent. Do not wring or twist. Lay flat to dry.Silk: Dry cleaning is often recommended. Some silks can be hand- or machine-washed, but avoid using a clothes dryer. Wool: Check the label for specific instructions. Many wools can be machine-washed on a gentle cycle with cold water. Avoid high temperatures, as they can cause the wool to shrink or felt. |
hallucinated |
irrelevant |
relevant |
|
How can I identify if an email claiming to be from Zappos is legitimate or a phishing attempt? |
recommends you update your online passwords, including the password to your Zappos.com Account, and report the email to the Federal Trade Commission (FTC). Visit the FTC website here to report the email and find more information on how to identify and prevent phishing attacks. |
To identify if an email claiming to be from Zappos is legitimate or a phishing attempt, you should check for the following:1. Look for the correct sender email address. Zappos emails should come from an address ending in “@zappos.com”. |
hallucinated |
relevant |
relevant |
|
What is amazon Pay, and how do I access my transaction history with it on Zappos? |
How do I find my amazon Pay transactions? |
amazon Pay is a digital wallet that allows you to make payments online using the information stored in your amazon account, including your shipping addresses, payment methods, and default delivery settings. To view your amazon Pay transaction history on Zappos or any other merchant site, you should log into your amazon account. Once logged in, navigate to the “Your Orders” page, where you can view all of your past and present orders, including those made using amazon Pay. If you’re unable to find a specific transaction, you can use the search bar to look up the order number or the date of the transaction. |
hallucinated |
irrelevant |
relevant |
| … | . | . | . | . | . |
| . | . | . | 87% | 67% | 100% |
From the preceding aggregates, we can see that answer relevance has a high score; however, context relevance in this example RAG system is 67%. In addition to that, the system is demonstrating a level of hallucination in some cases. Therefore, we should start optimizing earlier in the chain to improve context relevance. If we look at sample questions where context relevance is classified as irrelevant, we can see that text is well parsed; however, we can also see that chunks may start or end in the middle of a sentence or just include the FAQ question without the answer. Therefore, we start by optimizing the chunking method.
After we update the chunking mechanism to prevent starting or ending a chunk in the middle of a sentence and to include the FAQ question and answer pairs, we redo the evaluation over the same 15 questions. The following table shows a sample of our results.
| Question | Retrieved Document | Answer | Faithfulness | Context Relevance | Answer Relevance |
|
What are the specific care instructions for different fabric types like cashmere, silk, and wool? |
How do I care for XYZ fabric? Acetate: While most items made of acetate are dry-clean only, some may be hand-washed in lukewarm water. Do not twist the fabric. Iron while the fabric is damp. Press the inside of the garment using a low-temperature setting. Use a pressing cloth when ironing the outside. Acrylic knit: Most acrylic knit garments can be machine-washed. Read the label, and check for the proper drying option. Some knits retain their shapes best if reshaped and dried flat. Cashmere: Check the care label before laundering cashmere. To hand-wash, use a mild detergent or shampoo. Gently squeeze the water through the garment, then rinse until the water runs clear. Do not wring or twist. Squeeze out excess water. To dry, lay flat on a towel, away from sunlight or heat. Cotton: Cotton holds up well to home laundering. Remove the garment from the dryer promptly to reduce wrinkling. Press using spray starch for the crispness of a laundered shirt. Cotton blend: Dry cotton-blend garments using your dryer’s permanent-press or low-heat cycle, and remove immediately to reduce wrinkling. Touch up with a steam iron; starch for a professionally laundered look. Linen: Most linen garments need to be dry-cleaned or hand-washed. Follow the instructions on the care label. To touch up or press, use a steam iron on a linen setting for a crisp look. Nylon: Machine-wash nylon garments in warm water. Use a low-temperature setting when tumble-drying, and include a dryer sheet to reduce static electricity. Use a warm iron to press, if necessary. Polyester: Read the label. Usually polyester items can be machine-washed (cool) and dried (low). Check the label to see if air-drying is recommended. Touch up with a cool – never hot – iron, if necessary. Rayon: Make sure to read the care label for rayon clothing. Launder in cool water and a mild detergent. When machine-washing, use the gentle cycle and promptly remove garments after washing. When hand-washing, do not wring or twist the garment. To dry, roll the item in a towel to squeeze out excess water. Lay flat to dry. Iron when still damp and with the garment inside out to prevent the fabric from becoming shiny. Use a pressing cloth when ironing the right side of the garment. Pressing cloths can be purchased, or use something as simple as a piece of white cotton fabric. Silk: Dry cleaning may be required. Some silks are hand- or machine-washable. Do not dry silk in a clothes dryer. Garments usually look best when professionally dry-cleaned. Spandex: Use warm water when hand- or machine-washing items made with spandex. Line-dry or use a low temperature setting when machine-drying to preserve the elasticity of the garment. Wool knit: Typically wool knits need to be dry-cleaned, but check the label. If hand-washable, use cool water and a detergent for fine washables. Squeeze out excess water, then reshape and dry flat. Wool (lined): Lined garments generally look best when professionally dry-cleaned once a season. Between dry cleanings, remove surface soil with a brush or damp cloth. Refresh the item by hanging it from a padded hanger in a steamy bathroom; moisture will help garment shed wrinkles. When touching up with an iron, use steam in an up-and-down motion (rather than sliding the iron along the fabric). |
Cashmere: Check the care label before laundering. To hand-wash, use a mild detergent or shampoo. Gently squeeze the water through the garment, then rinse until the water runs clear. Do not wring or twist. Squeeze out excess water and lay flat to dry, away from sunlight or heat. Silk: Dry cleaning may be required. Some silks are hand- or machine-washable. Do not dry silk in a clothes dryer. For hand-washing, use a mild detergent and cool water. Squeeze out excess water and lay flat to dry. Iron when still damp and with the garment inside out to prevent the fabric from becoming shiny. Wool: The care instructions for wool depend on whether it’s a knit or not. For wool knits, they typically need to be dry-cleaned, but check the label. If hand-washable, use cool water and a detergent for fine washables. Squeeze out excess water, then reshape and dry flat. For lined wool garments, they generally look best when professionally dry-cleaned once a season. Between dry cleanings, remove surface soil with a brush or damp cloth and refresh in a steamy bathroom. When touching up with an iron, use steam in an up-and-down motion. |
factual |
relevant |
relevant |
|
How can I identify if an email claiming to be from Zappos is legitimate or a phishing attempt? |
How do I identify whether an Email is or is not from Zappos? Suspicious or fraudulent emails not from Zappos.com may contain: A reference to a payment source that Zappos.com does not accept, such as PayPal. Zappos.com currently only accepts credit cards, debit cards, and Zappos.com Gift Cards for payment. What should I do if I believe I’ve received a phishing email or if I responded to what may be a phishing email? If you believe you received a phishing email or responded to what may be a phishing email, Zappos recommends you update your online passwords, including the password to your Zappos.com Account, and report the email to the Federal Trade Commission (FTC). Visit the FTC website here to report the email and find more information on how to identify and prevent phishing attacks. Payment Information Do you accept international credit cards? Currently Zappos.com can accept international credit cards but we can only ship to an address within the United States and its territories. Please note that the credit card must be issued and contain a logo from either Visa, Mastercard, Discover, or American Express. On the checkout page, there will be a billing and shipping section. Please do the following: For the billing information Enter your street address on Address Line 1. Enter your City, County or Province, and Postal Code on Address Line 2. Enter your Country for the city. Enter AA for the state. Enter 11111 for the zip code. For the shipping information Please enter the correct information in the appropriate field. Orders placed with the use of an International Credit Card may take up to 72 hours to finalize prior to shipping. We apologize for any inconvenience this may cause. |
To identify if an email claiming to be from Zappos is legitimate or a phishing attempt, check for the following: 1. Zappos only accepts certain payment methods: credit cards, debit cards, and Zappos.com Gift Cards. If you believe you received a phishing email or responded to what may be a phishing email, update your passwords and report the email to the Federal Trade Commission (FTC). |
factual |
relevant |
relevant |
|
What is amazon Pay, and how do I access my transaction history with it on Zappos? |
How do I find my amazon Pay transactions? Go to pay.amazon.com and sign in as a “shopper” using your amazon username and password. One-time purchases are shown on the “Activity” tab, and subscription agreements are on the “Merchant agreements” tab. You can also view your transactions on amazon.com. If you are on a desktop, your amazon Pay transactions can be found under “amazon Orders” within the amazon Pay tab or in “Your Account” under “Transactions”. If you are in the amazon app, all transactions are listed together under “Your Orders” or in “Your Account”. |
amazon Pay is a digital wallet that allows you to make payments online using your amazon account. However, the context does not provide information on how to access your transaction history with amazon Pay on Zappos. The instructions given in the context are for accessing amazon Pay transactions on amazon’s own platform. |
factual |
relevant |
relevant |
| … | . | . | . | . | . |
| . | . | . | 100% | 93% | 100% |
After we changed the chunking mechanism to prevent mid-sentence chunking and to include an FAQ and its corresponding answer in the same chunk, we improved context relevance from 67% to 93%. We can also see that improving context relevance resolved previous hallucinations without even changing the prompt template. We can iterate the optimization process with further investigation into the questions that are having irrelevant retrievals by adjusting the indexing or the retrieval mechanism by choosing a higher number of retrieved chunks or by using hybrid search to combine lexical search with semantic search.
Sample references
To further explore and experiment different RAG evaluation techniques, you can delve deeper into the amazon-bedrock-samples/tree/main/knowledge-bases/01-rag-concepts” target=”_blank” rel=”noopener”>sample notebooks available in the amazon-bedrock-samples/tree/main/knowledge-bases” target=”_blank” rel=”noopener”>Knowledge Bases section of the amazon-bedrock-samples/” target=”_blank” rel=”noopener”>amazon Bedrock Samples GitHub repo.
Conclusion
In this post, we described the importance of evaluating and monitoring RAG-based generative ai applications. We showcased the metrics and frameworks for RAG system evaluation and observability, then we went over how you can use FMs in amazon Bedrock to compute RAG reliability metrics. It’s important to choose the metrics that matter most to your organization and that impact the aspect or configuration you want to optimize.
If RAG is not sufficient for your use case, you can opt for fine-tuning or continued pre-training in amazon Bedrock or amazon SageMaker to build custom models that are specific to your domain, organization, and use case. Most importantly, keeping a human in the loop is essential to align ai systems, as well as their evaluation mechanisms, with their intended uses and objectives.
About the Authors
 Oussama Maxime Kandakji is a Senior Solutions Architect at AWS focusing on data science and engineering. He works with enterprise customers on solving business challenges and building innovative functionalities on top of AWS. He enjoys contributing to open source and working with data.
Oussama Maxime Kandakji is a Senior Solutions Architect at AWS focusing on data science and engineering. He works with enterprise customers on solving business challenges and building innovative functionalities on top of AWS. He enjoys contributing to open source and working with data.
 Ioan Catana is a Senior artificial intelligence and Machine Learning Specialist Solutions Architect at AWS. He helps customers develop and scale their ML solutions and generative ai applications in the AWS Cloud. Ioan has over 20 years of experience, mostly in software architecture design and cloud engineering.
Ioan Catana is a Senior artificial intelligence and Machine Learning Specialist Solutions Architect at AWS. He helps customers develop and scale their ML solutions and generative ai applications in the AWS Cloud. Ioan has over 20 years of experience, mostly in software architecture design and cloud engineering.






{kind=link}