 NEWSLETTER
NEWSLETTER
Machine translation, a critical area within natural language processing (NLP), focuses on developing algorithms to automatically translate text from one language to another. This technology is essential to breaking down language barriers and facilitating global communication. Recent advances in neural machine translation (NMT) have significantly improved the accuracy and fluency of translation, leveraging deep learning techniques to push the boundaries of what is possible in this field.
The main challenge is the significant disparity in translation quality between high- and low-resource languages. Resource-rich languages benefit from abundant training data, leading to superior translation performance. In contrast, low-resource languages need more training data and better translation quality. This imbalance makes effective communication and access to information difficult for speakers of low-income languages, a problem that this research aims to solve.
Current research includes data augmentation techniques such as back-translation and self-supervised learning on monolingual data to improve translation quality in low-resource languages. Existing frameworks involve dense transformer models that use feedback network layers for the encoder and decoder. Regularization strategies such as Gating Dropout are used to mitigate overfitting. These methods, while useful, often need help in addressing the unique challenges posed by the limited, poor-quality data available for many low-resource languages.
Researchers from Meta's Fundamental ai Research (FAIR) team introduced a novel approach using sparsely closed mixture of experts (MoE) models to address this problem. This innovative method incorporates multiple experts within the model to handle different aspects of the translation process more effectively. The gating mechanism intelligently directs input tokens to the most relevant experts, optimizing translation accuracy and reducing interference between unrelated linguistic directions.
MoE transformer models differ significantly from traditional dense transformers. In MoE models, some feedforward network layers in the encoder and decoder are replaced with MoE layers. Each MoE layer consists of multiple experts, each of which is a feedback network and an activation network that decides how to route input tokens to these experts. This structure helps the model to generalize better across different languages by minimizing interference and optimizing the available data.
The researchers used a methodology that involved conditional computational models. Specifically, they used MoE layers within the transformer encoder-decoder model, complemented by control networks. The MoE model learns to route input tokens to the two corresponding top experts by optimizing a combination of label-smoothed cross-entropy and an auxiliary load balancing loss. To further improve the model, the researchers designed a regularization strategy called Expert Output Masking (EOM), which was more effective than existing strategies such as Gating Dropout.
The performance and results of this approach were substantial. The researchers observed a significant improvement in translation quality in very low-resource languages. Specifically, MoE models achieved a 12.5% increase in chrF++ scores for translation from these languages to English. Furthermore, experimental results on the FLORES-200 development set for ten translation directions (including languages such as Somali, Southern Sotho, Twi, Umbundu and Venetian) showed that after filtering an average of 30% of parallel sentences, the quality of the translation improved. by 5% and the added toxicity was reduced by the same amount.
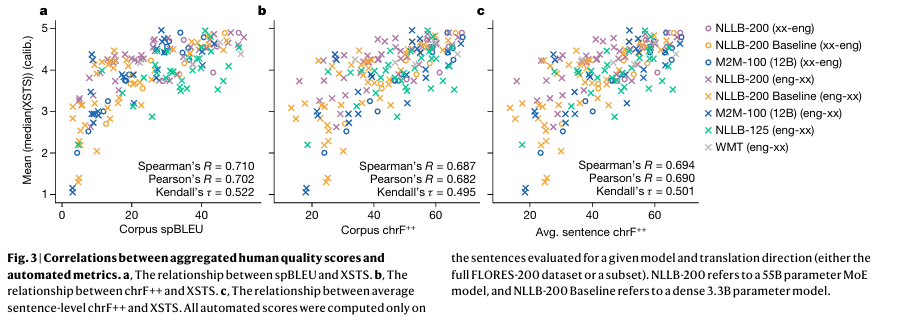
To obtain these results, the researchers also implemented a comprehensive evaluation process. They used a combination of automated metrics and human quality assessments to ensure the accuracy and reliability of their translations. The use of calibrated human evaluation scores provided a robust measure of translation quality, correlating strongly with automated scores and demonstrating the effectiveness of the MoE models.
In conclusion, the Meta research team addressed the critical issue of the disparity in translation quality between high- and low-resource languages by introducing MoE models. This innovative approach significantly improves translation performance for low-resource languages, providing a robust and scalable solution. Their work represents an important advance in machine translation, moving closer to the goal of developing a universal translation system that serves all languages equally.
Review the x” target=”_blank” rel=”noreferrer noopener”>Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter. Join our Telegram channel, Discord Channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our 44k+ ML SubReddit
![]()
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}