
Las organizaciones de medios y entretenimiento, publicidad, redes sociales, educación y otros sectores requieren soluciones eficientes para extraer información de videos y aplicar evaluaciones flexibles basadas en sus políticas. La inteligencia artificial (IA) generativa ha abierto nuevas oportunidades para estos casos de uso. En esta publicación, presentamos el Análisis de medios y evaluación de políticas solución, que utiliza AWS ai y servicios de IA generativa para proporcionar un marco para optimizar los procesos de extracción y evaluación de videos.
Casos de uso populares
Las empresas de tecnología publicitaria poseen contenido de vídeo, como creatividades publicitarias. Cuando se trata de análisis de vídeo, las prioridades incluyen la seguridad de la marca, el cumplimiento normativo y el contenido atractivo. Esta solución, impulsada por AWS ai y servicios de IA generativa, satisface estas necesidades. La moderación de contenido avanzada garantiza que los anuncios aparezcan junto con contenido seguro y compatible, generando confianza con los consumidores. Puede utilizar la solución para evaluar videos según las políticas de cumplimiento de contenido. También puede utilizarlo para crear titulares y resúmenes atractivos, aumentando la participación del usuario y el rendimiento de los anuncios.
Las empresas de tecnología educativa gestionan grandes inventarios de vídeos de formación. Una forma eficiente de analizar videos les ayudará a evaluar el contenido según las políticas de la industria, indexar videos para una búsqueda eficiente y realizar tareas dinámicas de detección y redacción, como difuminar los rostros de los estudiantes en una grabación de Zoom.
La solución está disponible en el repositorio de GitHub y se puede implementar en su cuenta de AWS mediante un kit de desarrollo en la nube de AWS (AWS CDK) paquete.
Descripción general de la solución
- Extracción de medios – Después de cargar un video, la aplicación comienza el preprocesamiento extrayendo fotogramas de imagen de un video. Cada cuadro se analizará utilizando amazon Rekognition y amazon Bedrock para la extracción de metadatos. Paralelamente, el sistema extrae la transcripción de audio del contenido cargado mediante amazon Transcribe.
- Evaluación de políticas – Utilizando los metadatos extraídos del video, el sistema realiza una evaluación LLM. Esto le permite aprovechar la flexibilidad de los LLM para evaluar videos frente a políticas dinámicas.
El siguiente diagrama ilustra el flujo de trabajo y la arquitectura de la solución.
La solución adopta principios de diseño de microservicios, con componentes poco acoplados que se pueden implementar juntos para servir al flujo de trabajo de análisis de video y evaluación de políticas, o de forma independiente para integrarse en los canales existentes. El siguiente diagrama ilustra la arquitectura de microservicio.
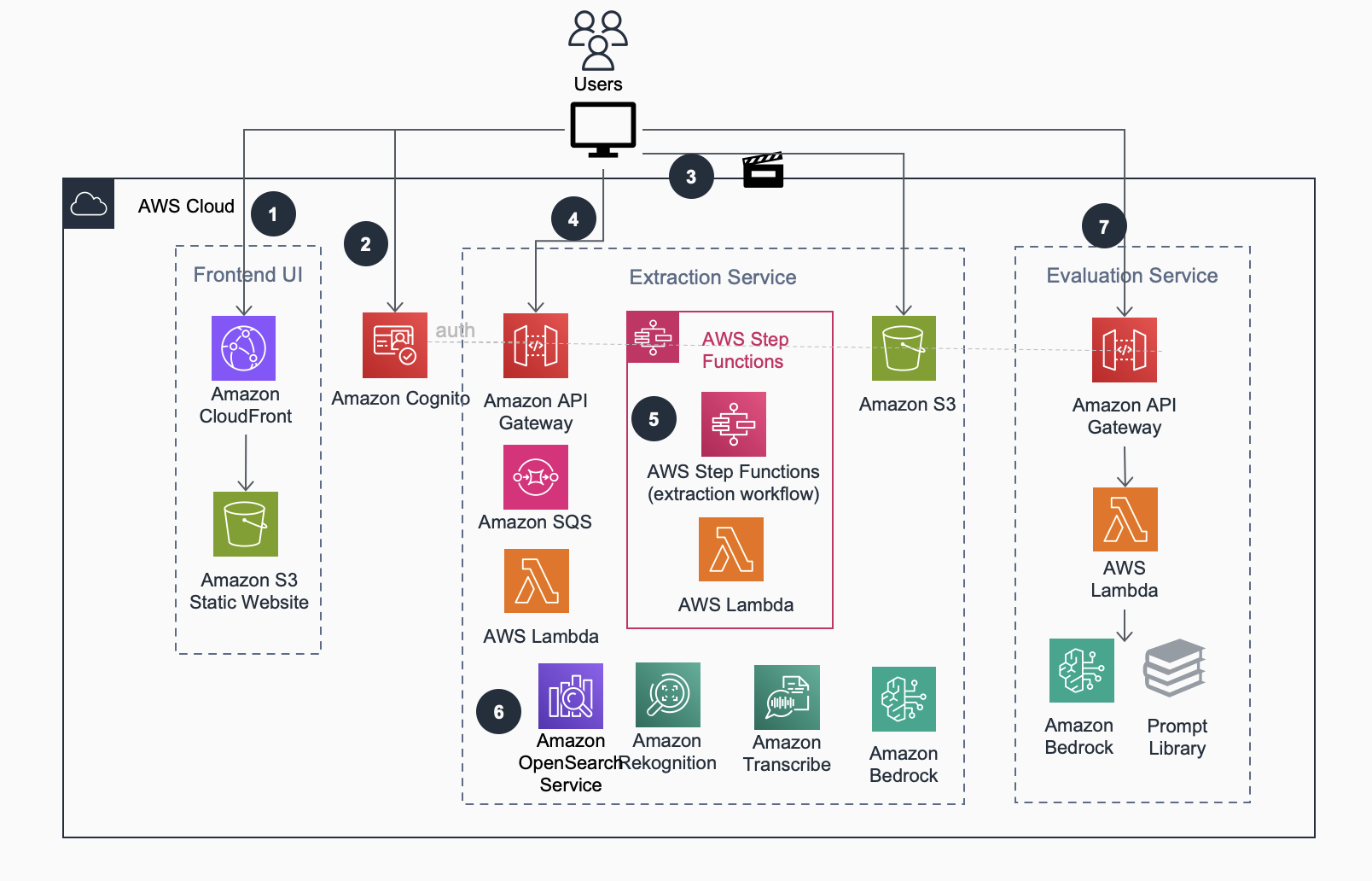
El flujo de trabajo del microservicio consta de los siguientes pasos:
- Los usuarios acceden al sitio web estático frontend a través de la distribución de amazon CloudFront. El contenido estático está alojado en amazon Simple Storage Service (amazon S3).
- Los usuarios inician sesión en la aplicación web frontend y son autenticados por un grupo de usuarios de amazon Cognito.
- Los usuarios cargan vídeos en amazon S3 directamente desde su navegador mediante URL de amazon S3 prefirmadas de varias partes.
- La interfaz de usuario del frontend interactúa con el microservicio de extracción a través de una interfaz RESTful proporcionada por amazon API Gateway. Esta interfaz ofrece funciones CRUD (crear, leer, actualizar, eliminar) para la gestión de extracción de tareas de video.
- Una máquina de estado de AWS Step Functions supervisa el proceso de análisis. Transcribe audio usando amazon Transcribe, toma muestras de fotogramas de imágenes de video usando moviepy y analiza cada imagen usando el resumen de imágenes de Anthropic Claude Sonnet. También genera incrustación de texto e incrustación multimodal a nivel de marco utilizando modelos de amazon Titan.
- Un clúster de amazon OpenSearch Service almacena los metadatos de vídeo extraídos y facilita las necesidades de búsqueda y descubrimiento de los usuarios. La interfaz de usuario crea indicaciones de evaluación y las envía a los LLM de amazon Bedrock, recuperando los resultados de la evaluación de forma sincrónica.
- Mediante la interfaz de usuario de la solución, el usuario selecciona las plantillas existentes, las personaliza e inicia la evaluación de la política utilizando amazon Bedrock. La solución ejecuta el flujo de trabajo de evaluación y muestra los resultados al usuario.
En las siguientes secciones, analizamos con más detalle los componentes clave y los microservicios de la solución.
Interfaz de usuario del sitio web
La solución incluye un sitio web que permite a los usuarios buscar vídeos y gestionar el proceso de carga a través de una interfaz fácil de usar. Ofrece detalles de la información del video extraída e incluye una interfaz de usuario de análisis liviana para análisis LLM dinámico. Las siguientes capturas de pantalla muestran algunos ejemplos.
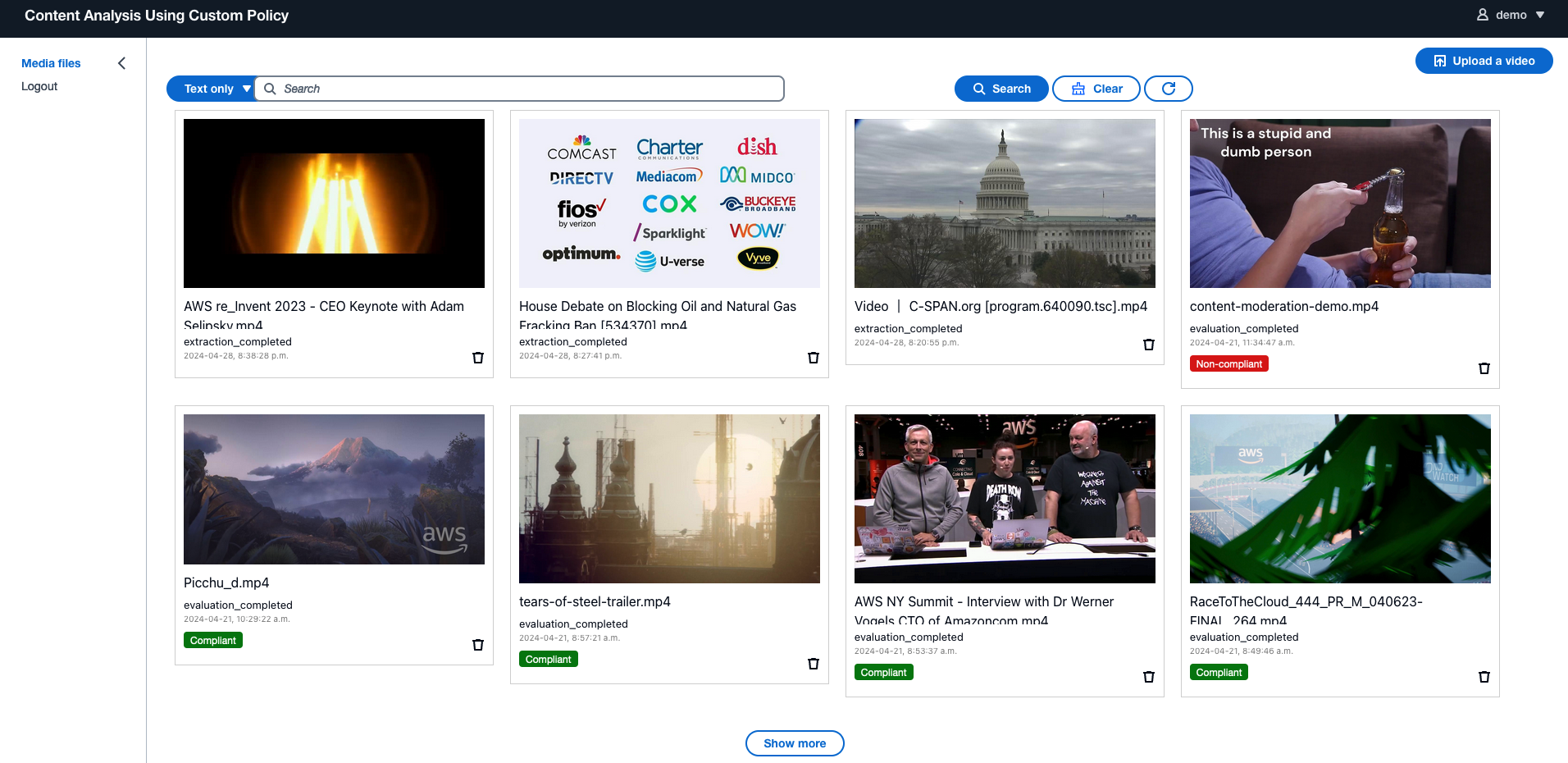
Extraer información de vídeos
La solución incluye un servicio de extracción backend para gestionar la extracción de metadatos de vídeo de forma asincrónica. Esto implica extraer información de los componentes visual y de audio, incluida la identificación de objetos, escenas, texto y rostros humanos. El componente de audio es particularmente importante para vídeos con narrativas y conversaciones activas, porque a menudo contiene información valiosa.
Crear una solución sólida para extraer información de videos plantea desafíos tanto desde la perspectiva del aprendizaje automático (ML) como de la ingeniería. Desde el punto de vista del ML, nuestro objetivo es lograr una extracción genérica de información que sirva como datos fácticos para el análisis posterior. Desde el punto de vista de la ingeniería, administrar el muestreo de video con concurrencia, proporcionar alta disponibilidad y opciones de configuración flexibles, además de tener una arquitectura extensible para admitir complementos adicionales del modelo ML, requiere un esfuerzo intensivo.
El servicio de extracción utiliza amazon Transcribe para convertir la parte de audio del vídeo en texto en formatos de subtítulos. Para la extracción visual, existen algunas técnicas importantes involucradas:
- Muestreo de cuadros – El método clásico para analizar el aspecto visual de un vídeo utiliza una técnica de muestreo. Esto implica capturar capturas de pantalla a intervalos específicos y luego aplicar modelos de ML para extraer información de cada cuadro de imagen. Nuestra solución utiliza muestreo con las siguientes consideraciones:
- La solución admite un intervalo configurable para la frecuencia de muestreo fija.
- También ofrece una opción de muestreo inteligente avanzada, que utiliza el modelo amazon Titan Multimodal Embeddings para realizar búsquedas de similitudes en fotogramas muestreados del mismo vídeo. Este proceso identifica imágenes similares y descarta las redundantes para optimizar el rendimiento y el costo.
- Extraer información de marcos de imágenes. – La solución iterará a través de imágenes tomadas de un video y las procesará simultáneamente. Para cada imagen, aplicará las siguientes funciones de ML para extraer información:
El siguiente diagrama ilustra cómo se implementa el servicio de extracción.
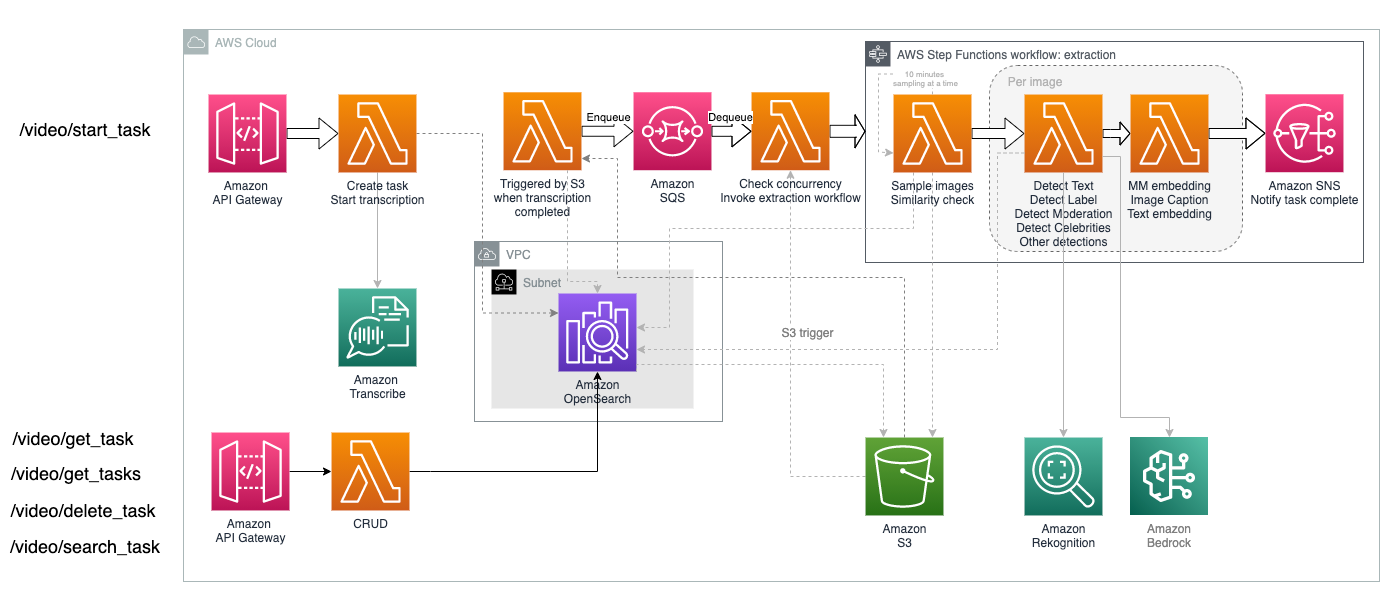
El servicio de extracción utiliza amazon Simple Queue Service (amazon SQS) y Step Functions para administrar el procesamiento de video simultáneo, lo que permite configuraciones configurables. Puede especificar cuántos vídeos se pueden procesar en paralelo y cuántos fotogramas de cada vídeo se pueden procesar simultáneamente, según los límites de cuota de servicio y los requisitos de rendimiento de su cuenta.
buscar los vídeos
Identificar videos de manera eficiente dentro de su inventario es una prioridad, y una capacidad de búsqueda efectiva es fundamental para las tareas de análisis de video. Los métodos tradicionales de búsqueda de vídeos se basan en búsquedas de palabras clave de texto completo. Con la introducción de la incrustación de texto y la incrustación multimodal, han surgido nuevos métodos de búsqueda basados en semántica e imágenes.
La solución ofrece funcionalidad de búsqueda a través del servicio de extracción, disponible como función de interfaz de usuario. Genera incrustaciones de vectores a nivel de fotograma de imagen como parte del proceso de extracción para servir a la búsqueda de vídeos. Puede buscar videos y sus marcos subyacentes a través de la interfaz de usuario web incorporada o directamente a través de la interfaz API RESTful. Hay tres opciones de búsqueda entre las que puede elegir:
- Búsqueda de texto completo – Desarrollado por OpenSearch Service, utiliza un índice de búsqueda generado por analizadores de texto eso es ideal para la búsqueda de palabras clave.
- búsqueda semántica – Desarrollado por el modelo amazon Titan Text Embeddings, generado en base a transcripción y metadatos de imágenes extraídos a nivel de marco.
- Búsqueda de imágenes – Desarrollado por el modelo amazon Titan Multimodal Embeddings, generado utilizando el mismo mensaje de texto utilizado para la incrustación de texto junto con el marco de la imagen. Esta función es adecuada para la búsqueda de imágenes, lo que le permite proporcionar una imagen y encontrar fotogramas similares en videos.
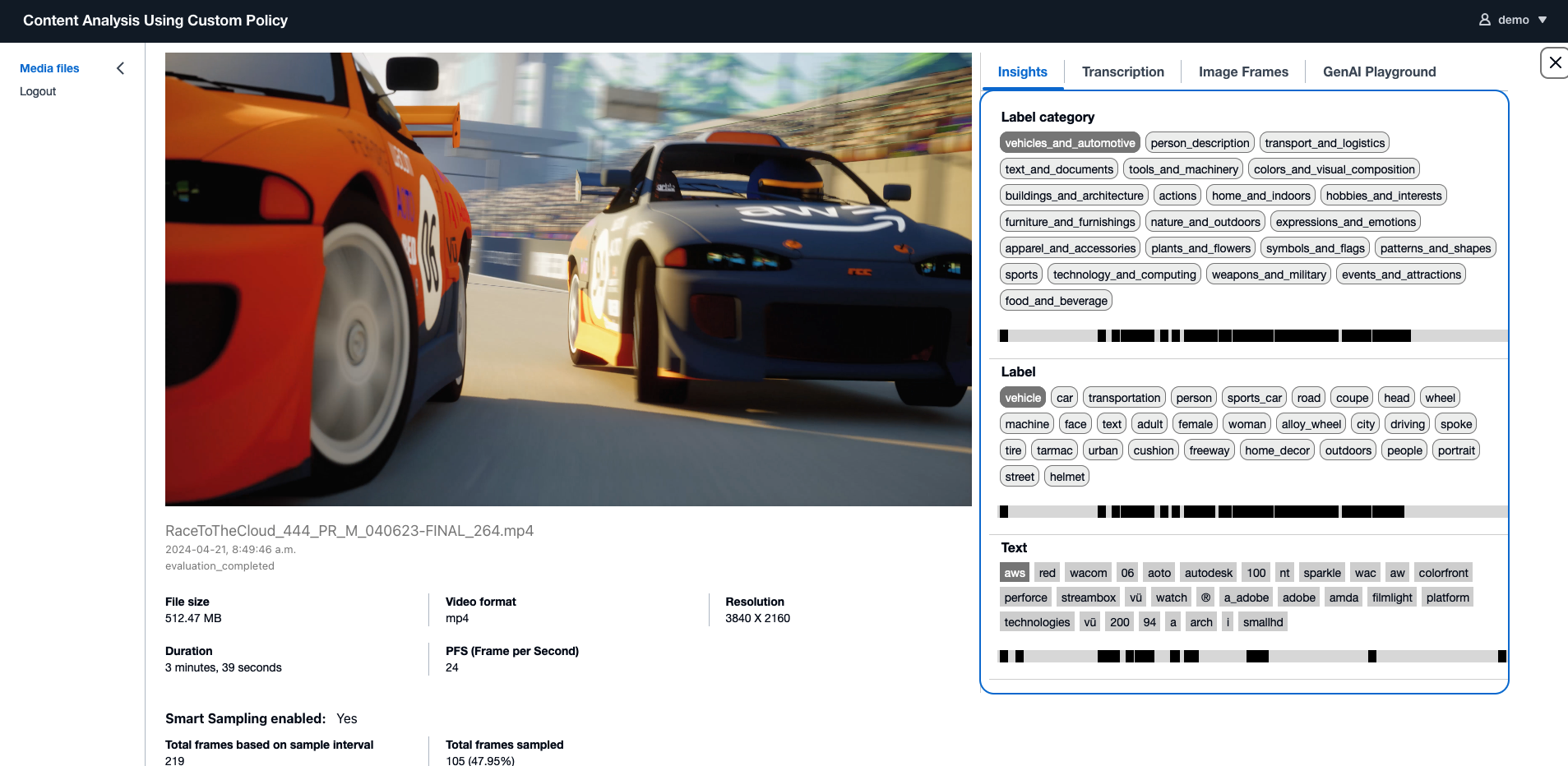
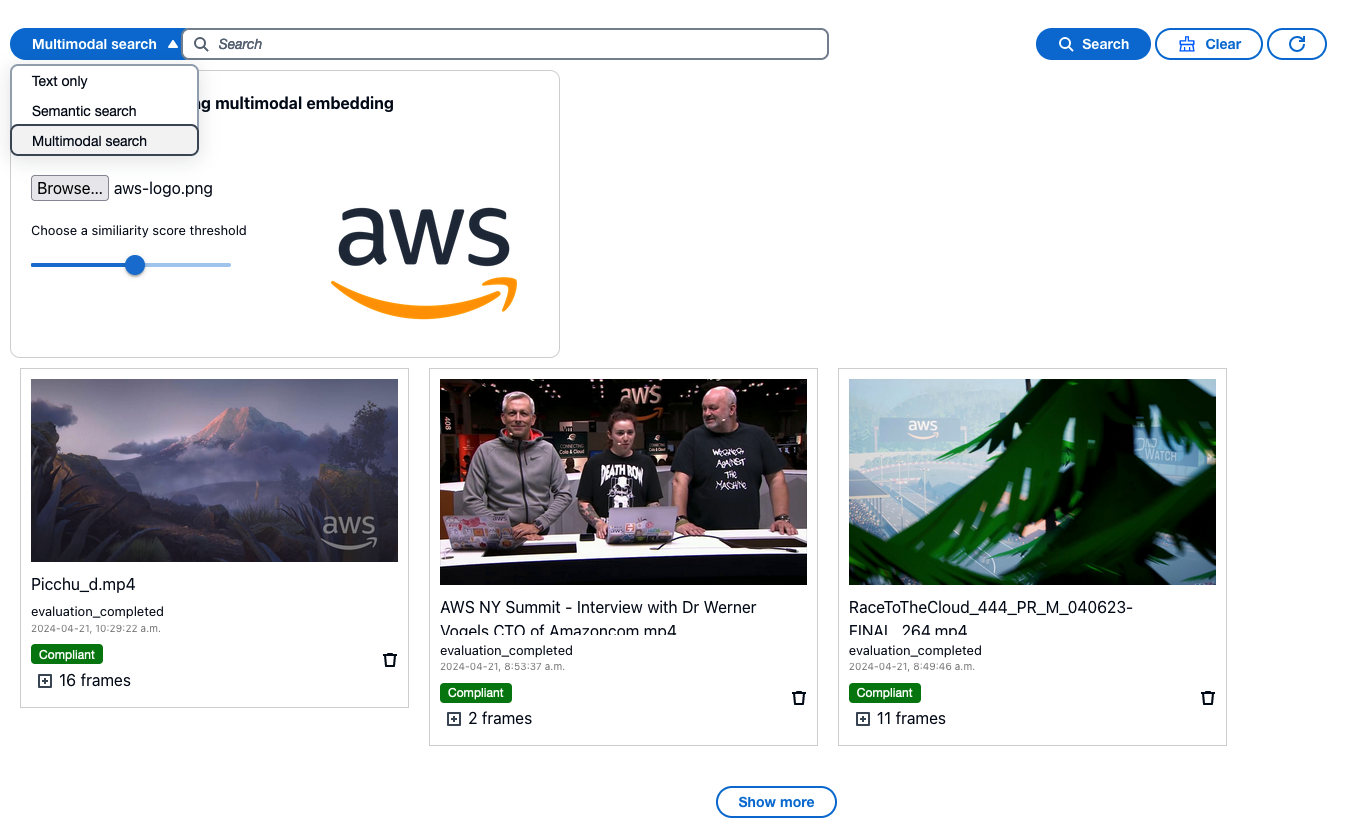
La siguiente captura de pantalla de la interfaz de usuario muestra el uso de incrustación multimodal para buscar videos que contengan el logotipo de AWS. La interfaz de usuario web muestra tres vídeos con fotogramas que tienen una alta puntuación de similitud en comparación con la imagen del logotipo de AWS proporcionada. También puede encontrar las otras dos opciones de búsqueda de texto en el menú desplegable, lo que le brinda la flexibilidad de cambiar entre las opciones de búsqueda.
analiza los vídeos
Después de recopilar información valiosa de los videos, puede analizar los datos. La solución presenta una interfaz de usuario liviana, implementada como una aplicación web React estática, impulsada por un microservicio de backend llamado servicio de evaluación. Este servicio actúa como un proxy sobre los LLM de amazon Bedrock para proporcionar una evaluación en tiempo real. Puede utilizar esto como una función de espacio aislado para probar las indicaciones de LLM para análisis de video dinámico. La interfaz de usuario web contiene algunas plantillas de mensajes de muestra para mostrar cómo se puede analizar vídeo para diferentes casos de uso, incluidos los siguientes:
- Moderación de contenido – Marcar escenas, textos o discursos inseguros que violen su política de confianza y seguridad.
- Resumen de vídeo – Resuma el video en una descripción concisa basada en sus pistas de contenido visual o de audio.
- clasificación BIA – Clasifique el contenido del video en categorías publicitarias IAB para una mejor organización y comprensión.
También puede elegir entre una colección de modelos de LLM ofrecidos por amazon Bedrock para probar los resultados de la evaluación y encontrar el más adecuado para su carga de trabajo. Los LLM pueden utilizar los datos de extracción y realizar análisis según sus instrucciones, lo que los convierte en herramientas de análisis flexibles y ampliables que pueden admitir diversos casos de uso. Los siguientes son algunos ejemplos de plantillas de mensajes para análisis de vídeo. Los marcadores de posición dentro de #### serán reemplazados por los datos correspondientes extraídos del video en tiempo de ejecución.
El primer ejemplo muestra cómo moderar un vídeo basándose en la transcripción de audio y las etiquetas de moderación y objetos detectadas por amazon Rekognition. Este ejemplo incluye una política en línea básica. Puede ampliar esta sección para agregar más reglas. Puede integrar runbooks y documentos de políticas de confianza y seguridad más extensos en un patrón de generación aumentada de recuperación (RAG) utilizando Knowledge Bases for amazon Bedrock.
Clasificar vídeos en categorías IAB solía ser un desafío antes de que la IA generativa se hiciera popular. Por lo general, implicaba modelos de aprendizaje automático de clasificación de imágenes y textos entrenados a medida, que a menudo enfrentaban desafíos de precisión. El siguiente mensaje de muestra utiliza el modelo amazon Bedrock Anthropic Claude V3 Sonnet, que tiene conocimiento integrado de la taxonomía IAB. Por lo tanto, ni siquiera es necesario incluir las definiciones de taxonomía como parte del mensaje de LLM.
Resumen
El análisis de vídeo presenta desafíos que abarcan dificultades técnicas tanto en ML como en ingeniería. Esta solución proporciona una interfaz de usuario fácil de usar para optimizar los procesos de análisis de vídeo y evaluación de políticas. Los componentes de backend pueden servir como bloques de construcción para la integración en su flujo de trabajo de análisis existente, lo que le permite centrarse en tareas de análisis con mayor impacto empresarial.
Puede implementar la solución en su cuenta de AWS utilizando el paquete AWS CDK disponible en repositorio de GitHub. Para obtener detalles sobre la implementación, consulte la instrucciones paso a paso.
Sobre los autores

Lana Zhang es arquitecto de soluciones senior en el equipo de servicios de inteligencia artificial de la organización mundial especializada de AWS, y se especializa en inteligencia artificial e inteligencia artificial generativa con un enfoque en casos de uso que incluyen moderación de contenido y análisis de medios. Con su experiencia, se dedica a promover la IA de AWS y las soluciones de IA generativa, demostrando cómo la IA generativa puede transformar casos de uso clásicos con valor empresarial avanzado. Ayuda a los clientes a transformar sus soluciones comerciales en diversas industrias, incluidas las redes sociales, los juegos, el comercio electrónico, los medios, la publicidad y el marketing.
 Negin Rouhanizadeh es arquitecto de soluciones en AWS y se centra en IA/ML en publicidad y marketing. Más allá de crear soluciones para sus clientes, a Negin le gusta pintar, codificar y pasar tiempo con la familia y sus peludos, Simba y Huchi.
Negin Rouhanizadeh es arquitecto de soluciones en AWS y se centra en IA/ML en publicidad y marketing. Más allá de crear soluciones para sus clientes, a Negin le gusta pintar, codificar y pasar tiempo con la familia y sus peludos, Simba y Huchi.






{kind=link}