
Annotated data is an essential ingredient for training, evaluating, benchmarking, and putting machine learning models into production. Therefore, it is imperative that the annotations are of high quality. Its creation requires good quality management and, therefore, reliable quality estimates. Then, if the quality is insufficient during the annotation process, corrective measures can be taken to improve it. For example, project managers can use quality estimates to improve annotation guidelines, retrain annotators, or catch as many bugs as possible before release.
Quality estimation is often done by having experts manually label instances as correct or incorrect. But checking all annotated instances tends to be expensive. Therefore, in practice, only subsets are normally inspected; The sizes are mostly chosen without justification or without regard to statistical power, and most often they are not relatively small. However, basing estimates on small sample sizes can lead to imprecise values for the error rate. Using unnecessarily large sample sizes requires money that could be better spent, for example, on more annotations.
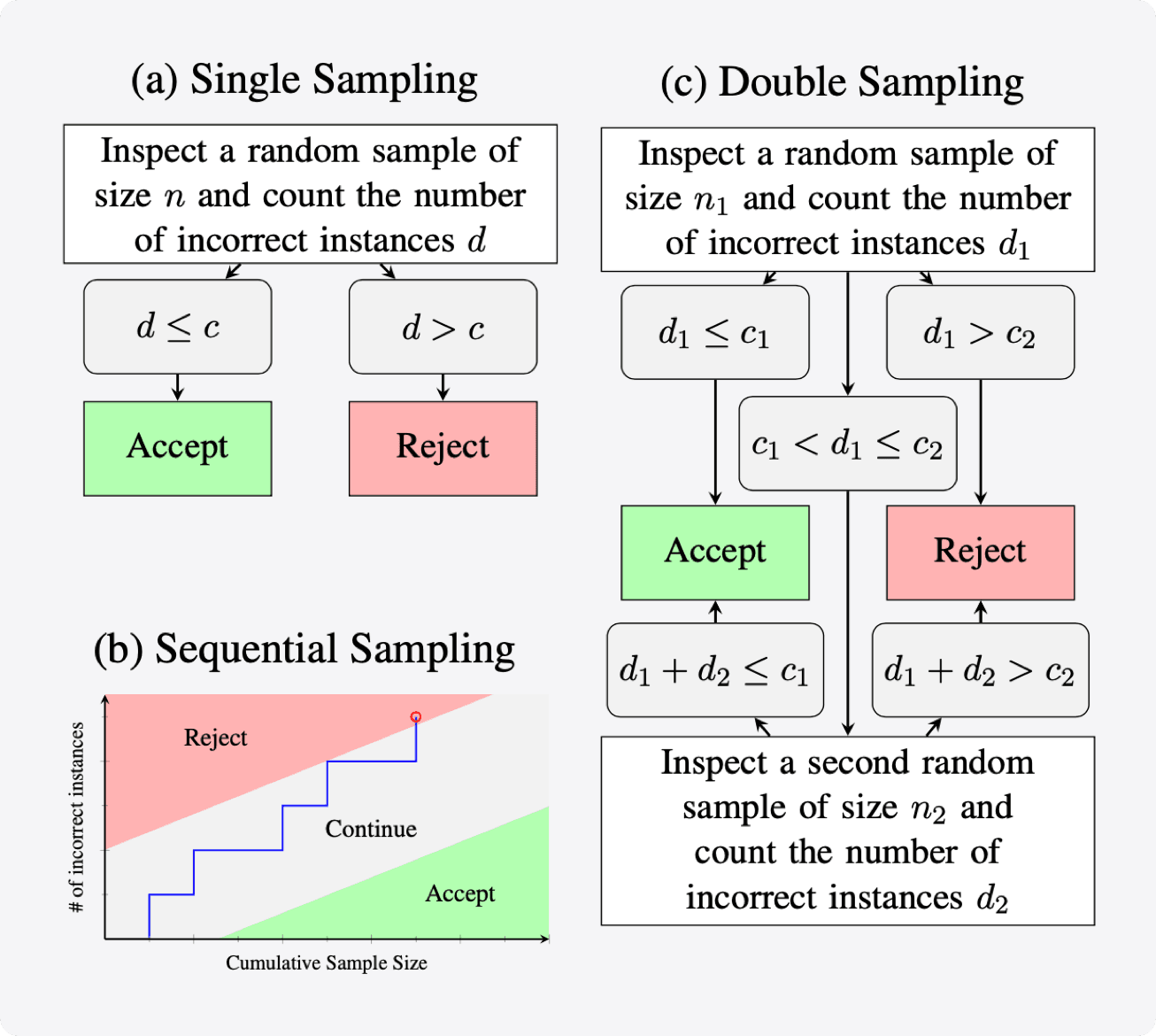
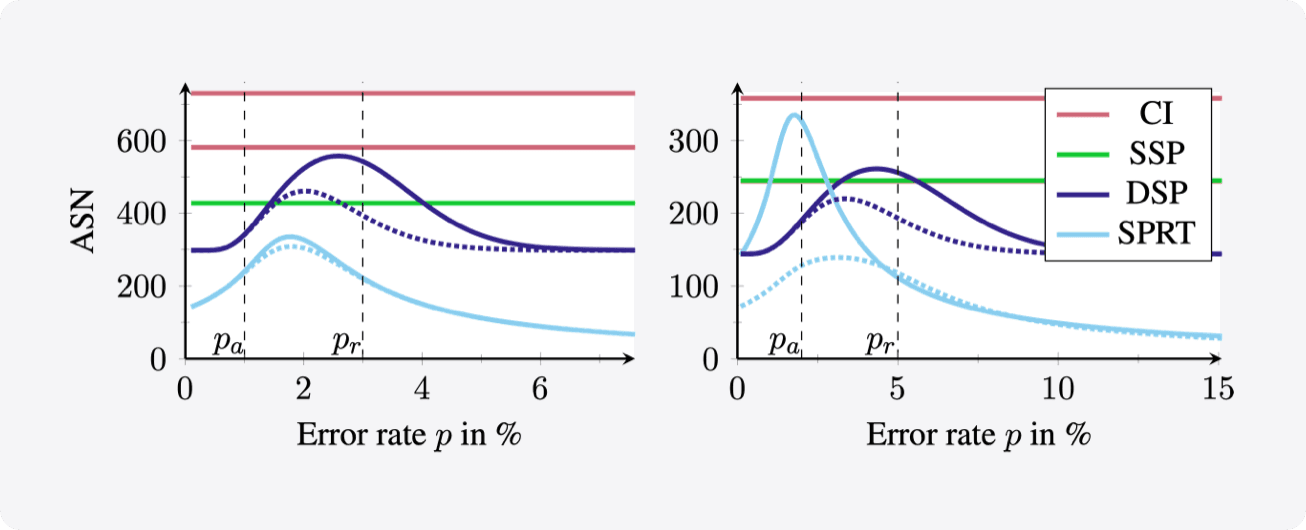
Therefore, we first describe in detail how to use confidence intervals to find the minimum sample size needed to estimate the annotation error rate. Next, we propose to apply acceptance sampling as an alternative to error rate estimation. We show that it can reduce the required sample sizes by up to 50% while providing the same statistical guarantees.






{kind=link}