
Multimodal large language models (MLLM) are cutting-edge innovations in artificial intelligence that combine the capabilities of language and vision models to handle complex tasks such as visual question answering and image captioning. These models use large-scale pre-training, integrating multiple data modalities to significantly improve their performance in various applications. The integration of language and vision data allows these models to perform tasks that were previously impossible for single-modality models, marking a substantial advance in ai.
The main problem with MLLMs is their extensive resource requirements, which significantly hinder their widespread adoption. Training these models requires vast computational resources, which are often only available to large companies with substantial budgets. For example, training a model like MiniGPT-v2 requires over 800 GPU hours on NVIDIA A100 GPUs, a cost prohibitive for many academic researchers and smaller companies. Furthermore, the high computational costs of inference further exacerbate this problem, making it difficult to implement these models in resource-constrained environments such as edge computing.
(Featured Article) LLMWare.ai Selected for GitHub 2024 Accelerator: Enabling the Next Wave of Innovation in Enterprise RAG with Small, Specialized Language Models
Current methods to address these challenges focus on optimizing the efficiency of MLLMs. Models such as OpenAI's GPT-4V and Google's Gemini have achieved notable performance through large-scale pre-training, but their computational demands restrict their use. Research has explored various strategies to create efficient MLLMs by reducing model size and optimizing the computational strategy. This includes leveraging pre-training knowledge of each modality, which helps reduce the need to train models from scratch, thereby saving resources.
Researchers from Tencent, SJTU, BAAI, and ECNU have conducted an extensive survey on efficient MLLMs, categorizing recent advances into several key areas: architecture, vision processing, language model efficiency, training techniques, data usage, and practical applications. Their work provides a comprehensive overview of the field and offers a structured approach to improving resource efficiency without sacrificing performance. This research highlights the importance of developing lightweight architectures and specialized components designed to optimize efficiency.
Efficient MLLMs employ several innovative techniques to address resource consumption issues. These include the introduction of lighter architectures designed to reduce parameters and computational complexity. For example, models such as MobileVLM and LLaVA-Phi use vision token compression and efficient vision language projectors to improve efficiency. Vision token compression, for example, reduces the computational burden by compressing high-resolution images into more manageable patch features, significantly reducing the computational cost associated with processing large amounts of visual data.
The survey reveals substantial progress in the performance of efficient MLLMs. By employing token compression and lightweight model structures, these models achieve notable improvements in computational efficiency and expand their application scope. For example, LLaVA-UHD supports image processing at up to six times higher resolutions using only 94% of the computation compared to previous models. This makes it possible to train these models in academic environments; some models train in just 23 hours using 8 A100 GPUs. These efficiency gains do not come at the expense of performance; Models such as MobileVLM demonstrate competitive results in high-resolution image and video understanding tasks.
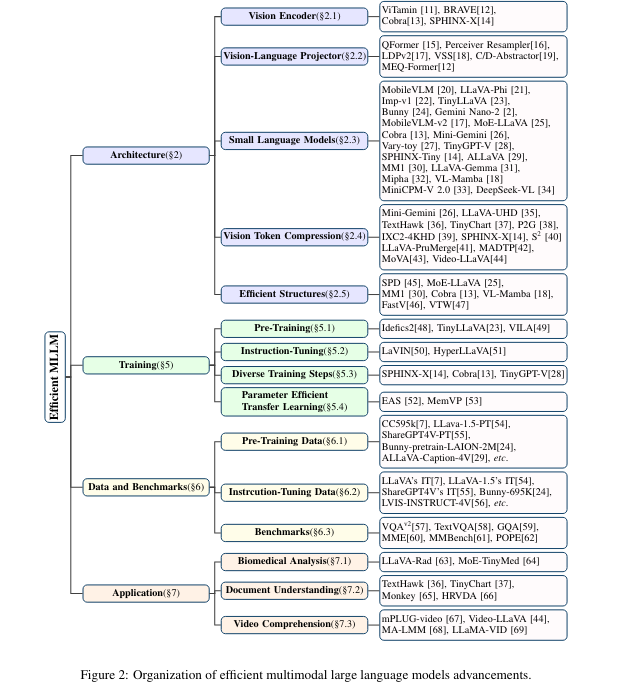
Key points from this survey on efficient multimodal large language models include:
- Resource requirements: MLLMs like MiniGPT-v2 require over 800 GPU hours on NVIDIA A100 GPUs to train, making it difficult for smaller organizations to use these models. The high computational costs of inference further limit its implementation in resource-limited environments.
- Optimization strategies: The research focuses on creating efficient MLLMs by reducing model size and optimizing computational strategies, leveraging pre-trained modality knowledge to save resources.
- Categorization of Advances: The survey ranks advances in architecture, vision processing, language model efficiency, training techniques, data usage, and practical applications, providing a comprehensive overview of the field.
- Vision Token Compression: Techniques such as vision token compression reduce the computational burden by compressing high-resolution images into more manageable patch features, significantly reducing computational costs.
- Training efficiency: Efficient MLLMs can be trained in academic environments; some models train in just 23 hours using 8 A100 GPUs. Adaptive reduction of visual tokens and fusion of information at multiple scales improve detailed visual perception.
- Performance Gains: Models such as LLaVA-UHD support image processing at up to six times higher resolutions using only 94% of the computation compared to previous models, demonstrating significant improvements in efficiency.
- Efficient architectures: MLLMs use lighter architectures, specialized components for efficiency, and novel training methods to achieve notable performance improvements while reducing resource consumption.
- Function information reduction: Techniques such as the funnel transformer and Set Transformer reduce the dimensionality of input features while preserving essential information, improving computational efficiency.
- Approximate attention: Kernelization and low-rank methods transform and decompose high-dimensional matrices, making the attention mechanism more efficient.
- Understanding documents and videos: Efficient MLLMs are applied in document and video understanding, with models such as TinyChart and Video-LLaVA addressing the challenges of high-resolution image and video processing.
- Distillation and Quantization of Knowledge: Through knowledge distillation, smaller models learn from larger models and accuracy is reduced in ViT models using quantization to decrease memory usage and computational complexity while maintaining accuracy.
In conclusion, research on efficient MLLMs addresses critical barriers to their broader use by proposing methods to decrease resource consumption and improve accessibility. By developing lightweight architectures, optimizing computational strategies, and employing innovative techniques such as vision token compression, researchers have significantly advanced the field of MLLM. These efforts make it possible for researchers and organizations to use these powerful models and improve their applicability in real-world scenarios, such as edge computing and resource-constrained environments. The advances highlighted in this survey provide a roadmap for future research, emphasizing the potential of efficient MLLMs to democratize advanced ai capabilities and improve their real-world applicability.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter. Join our Telegram channel, Discord Channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our 43k+ ML SubReddit
![]()
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. She is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}