
Image by author
Running large language models (LLMs) locally can be very useful, whether you want to play with LLMs or create more powerful applications using them. But setting up your work environment and getting LLMs running on your machine is not trivial.
So how do you run LLM locally without any hassle? Enter Ollama, a platform that facilitates local development with large open source language models. With Ollama, everything you need to run an LLM (model weights and all configuration) is packaged in a single Modelfile. Think Docker for LLM.
In this tutorial, we'll look at how to get started with Ollama to run large language models locally. So let's get straight to the steps!
Step 1 – Download Ollama to get started
As a first step, you need to download Ollama on your machine. Ollama is compatible with all major platforms: MacOS, Windows and Linux.
To download Ollama, you can visit the official GitHub repository and follow the download links from there. Or visit the official website and download the installer if you are on a Mac or Windows machine.
I'm on Linux: Ubuntu distribution. So if you are a Linux user like me, you can run the following command to run the installer script:
$ curl -fsSL https://ollama.com/install.sh | shThe installation process usually takes a few minutes. During the installation process, any NVIDIA/AMD GPU will be detected automatically. Make sure you have the drivers installed. CPU only mode also works fine. But it may be much slower.
Step 2: Get the model
You can then visit the model library to see the list of all currently supported model families. The default model downloaded is the one with the latest label. On each model page, you can get more information, such as the size and quantization used.
You can search the list of tags to locate the model you want to run. For each model family, there are usually basic models of different sizes and variants adapted to the instructions. I am interested in running the Gemma 2B model from the ai.google.dev/gemma” target=”_blank” rel=”noopener”>Gemma family of light models from Google DeepMind.
You can run the model using the ollama run Command to pull and start interacting with the model directly. However, you can also place the model on your machine first and then run it. This is very similar to how you work with Docker images.
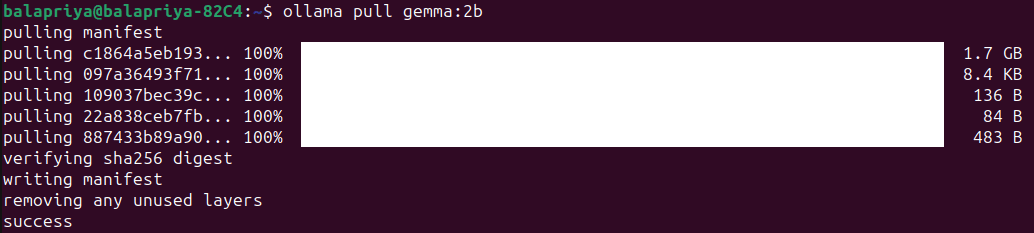
For Gemma 2B, running the following extract command downloads the model to your machine:
The model is size 1.7B and the pull should take a minute or two:
Step 3: Run the model
Run the model using the ollama run command as shown:
Doing so will start an Ollama REPL where you can interact with the Gemma 2B model. Here is an example:

For a simple question about the Python standard library, the answer seems pretty good. And it includes the most used modules.
Step 4: Customize model behavior with system prompts
You can customize LLMs by configuring system prompts for a specific desired behavior like this:
- Configure the system message for the desired behavior.
- Save the model by giving it a name.
- Exit REPL and run the model you just created.
Let's say you want your model to always explain concepts or answer questions in plain English with as little technical jargon as possible. Here's how you can do it:
>>> /set system For all questions asked answer in plain English avoiding technical jargon as much as possible
Set system message.
>>> /save ipe
Created new model 'ipe'
>>> /byeNow run the model you just created:
Here is an example:

Step 5: Use Ollama with Python
Running the Ollama command line client and interacting with the LLMs locally in the Ollama REPL is a good start. But often you will want to use LLM in your applications. You can run Ollama as a server on your machine and execute cURL requests.
But there are simpler ways. If you like using Python, you'll want to create LLM applications and here are a couple of ways to do it:
- Using the official Ollama Python library
- Using Ollama with LangChain
Extract the models you need to use before running the snippets in the following sections.
Using the Ollama Python library
You can use Ollama Python library, you can install it using pip like this:
There is also an official JavaScript library, which you can use if you prefer to develop with JS.
Once you install the Ollama Python library, you can import it into your Python application and work with large language models. Here is the snippet of a simple language generation task:
import ollama
response = ollama.generate(model="gemma:2b",
prompt="what is a qubit?")
print(response('response'))Use LangChain
Another way to use Ollama with Python is to use LangChain. If you have existing projects using LangChain, it's easy to integrate them or switch to Ollama.
Make sure you have LangChain installed. If not, install it using pip:
Here is an example:
from langchain_community.llms import Ollama
llm = Ollama(model="llama2")
llm.invoke("tell me about partial functions in python")Using LLMs like this in Python applications makes it easier to switch between different LLMs depending on the application.
Ending
With Ollama you can run large language models locally and create LLM-based applications with just a few lines of Python code. Here we explore how to interact with LLMs in the Ollama REPL, as well as from Python applications.
Next we will try to create an application using Ollama and Python. Until then, if you want to dive deeper into LLMs, check out 7 Steps to Mastering Large Language Models (LLMs).
twitter.com/balawc27″ rel=”noopener”>Bala Priya C. is a developer and technical writer from India. He enjoys working at the intersection of mathematics, programming, data science, and content creation. His areas of interest and expertise include DevOps, data science, and natural language processing. He likes to read, write, code and drink coffee! Currently, he is working to learn and share his knowledge with the developer community by creating tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource descriptions and coding tutorials.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}