
In AWS re:Invent In 2023, we are announcing general availability of knowledge bases for amazon Bedrock. With Knowledge Bases for amazon Bedrock, you can securely connect base models (FM) in amazon Bedrock to your enterprise data for fully managed recovery augmented generation (RAG).
In previous posts, we covered new capabilities like hybrid search support, metadata filtering to improve retrieval accuracy, and how Knowledge Bases for amazon Bedrock manages the end-to-end RAG workflow.
Today we're introducing the new ability to chat with your document out of the box in Knowledge Bases for amazon Bedrock. With this new capability, you can securely ask questions about individual documents, without the overhead of setting up a vector database or ingesting data, making it easier for companies to use their enterprise data. You just need to provide a relevant data file as input and choose your FM to get started.
But before we get into the details of this feature, let's start with the basics and understand what RAG is, its benefits, and how this new capability enables content retrieval and generation for temporary needs.
What is augmented generation recovery?
FM-powered artificial intelligence (ai) assistants have limitations, such as providing outdated information or struggling with context outside of their training data. RAG addresses these issues by allowing FMs to compare authoritative knowledge sources before generating answers.
With RAG, when a user asks a question, the system retrieves the relevant context from a selected knowledge base, such as company documentation. It provides this context to the FM, which uses it to generate a more informed and accurate response. RAG helps overcome the limitations of FM by augmenting its capabilities with an organization's unique knowledge, enabling chatbots and ai assistants to provide up-to-date, context-specific information tailored to business needs without retraining the entire workforce. FM. At AWS, we recognize the potential of RAG and have worked to simplify its adoption through knowledge bases for amazon Bedrock, providing a fully managed RAG experience.
Instant and short-term information needs.
Although a knowledge base does all the heavy lifting and serves as a large persistent store of business knowledge, you may need temporary access to data for specific tasks or analysis within isolated user sessions. Traditional RAG approaches are not optimized for these short-term session-based data access scenarios.
Companies incur charges for data storage and management. This can make RAG less cost-effective for organizations with highly dynamic or ephemeral information requirements, especially when the data is only needed for specific, isolated tasks or analyses.
Ask questions in a single document without configuration
This new ability to chat with your document within amazon Bedrock knowledge bases addresses the aforementioned challenges. Provides a configuration-free method to use your single document for content retrieval and generation-related tasks, along with FMs provided by amazon Bedrock. With this new capability, you can ask questions about your data without the overhead of setting up a vector database or ingesting data, making it easier to use your business data.
Now you can interact with your documents in real time without prior data ingestion or database configuration. There is no need to perform any further data preparation steps before querying the data.
This no-configuration approach makes it easy to use your company's information assets with generative ai using amazon Bedrock.
Use cases and benefits
Consider a recruiting company that needs to screen resumes and find candidates with suitable job opportunities based on their experience and skills. Previously, you would have to set up a knowledge base, invoking a data ingestion workflow to ensure that only authorized recruiters can access the data. Additionally, you'll need to manage cleanup when data is no longer needed for a session or candidate. In the end, you would pay more for vector database storage and management than for actual FM usage. This new feature in amazon Bedrock knowledge bases allows recruiters to quickly and quickly analyze resumes and match candidates with suitable job opportunities based on the candidate's experience and skill set.
For another example, consider a product manager at a technology company who needs to quickly analyze customer feedback and support tickets to identify common problems and areas for improvement. With this new capability, you can simply upload a document to extract information in no time. For example, you could ask “What are the requirements for the mobile app?” or “What are the common pain points mentioned by clients regarding our onboarding process?” This feature allows you to quickly synthesize this information without the hassle of data preparation or any management overhead. You can also ask for summaries or key takeaways, such as “What are the highlights of this requirements document?”
The benefits of this feature go beyond cost savings and operational efficiency. By eliminating the need for vector databases and data ingestion, this new capability within amazon Bedrock knowledge bases helps protect your proprietary data, making it accessible only within the context of isolated user sessions.
Now that we've covered the benefits of the features and the use cases it enables, let's dive into how you can start using this new feature of amazon Bedrock Knowledge Bases.
Chat with your document in Knowledge Bases for amazon Bedrock
You have multiple options to start using this feature:
Let's see how we can start using the amazon Bedrock console:
- In the amazon Bedrock console, in Orchestration In the navigation pane, choose Knowledge bases.
- Choose Chat with your document.
- Low Modelchoose Select model.
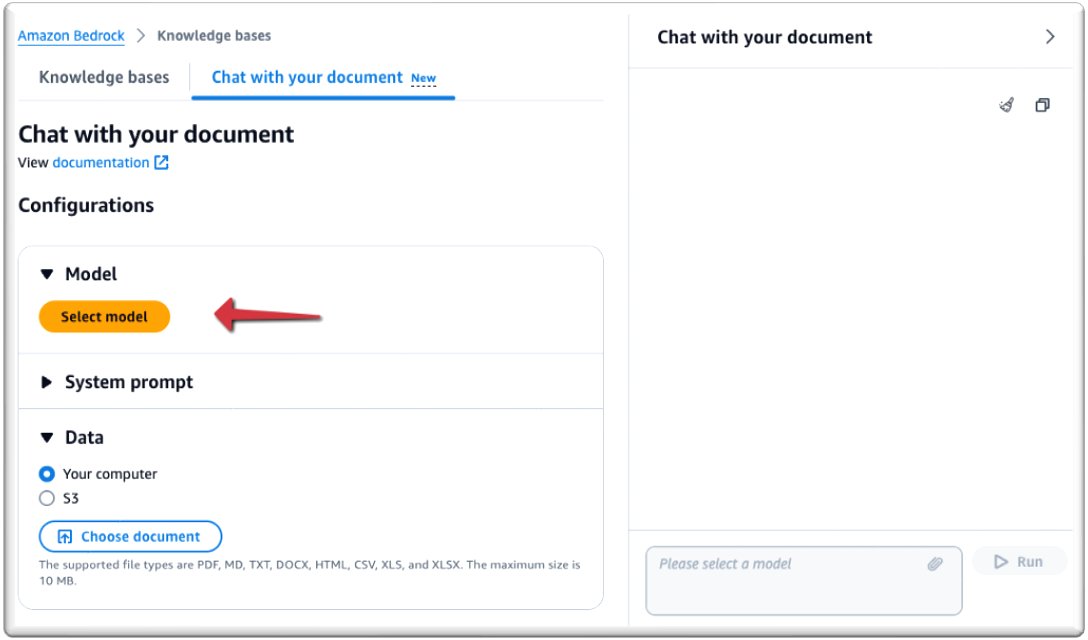
- Choose your model. For this example, we use the Claude 3 Sonnet model (we only support Sonnet at launch).
- Choose Apply.
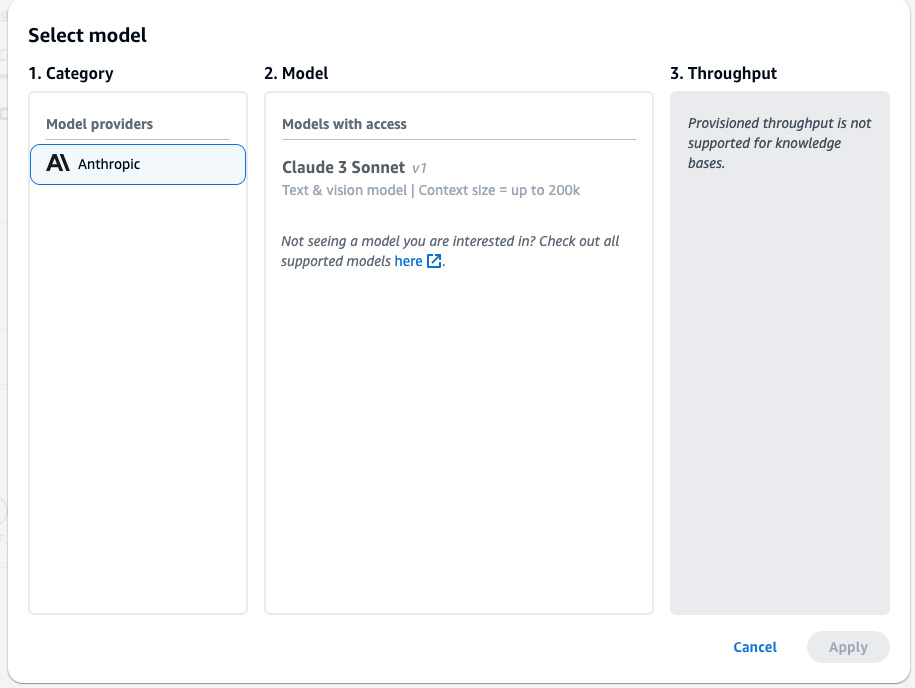
- Low Data, you can upload the document you want to chat with or point to the location of the amazon Simple Storage Service (amazon S3) bucket that contains your file. For this post, we uploaded a document from our computer.
Supported file formats are PDF, MD (Markdown), TXT, DOCX, HTML, CSV, XLS and XLSX. Make sure the file size does not exceed 10 MB and does not contain more than 20,000 tokens. TO symbolic is considered a unit of text, such as a word, subword, number, or symbol, that is processed as a single entity. Due to the preset ingestion token limit, it is recommended to use a file smaller than 10 MB. However, a text-heavy file that is much smaller than 10 MB can potentially exceed the token limit.
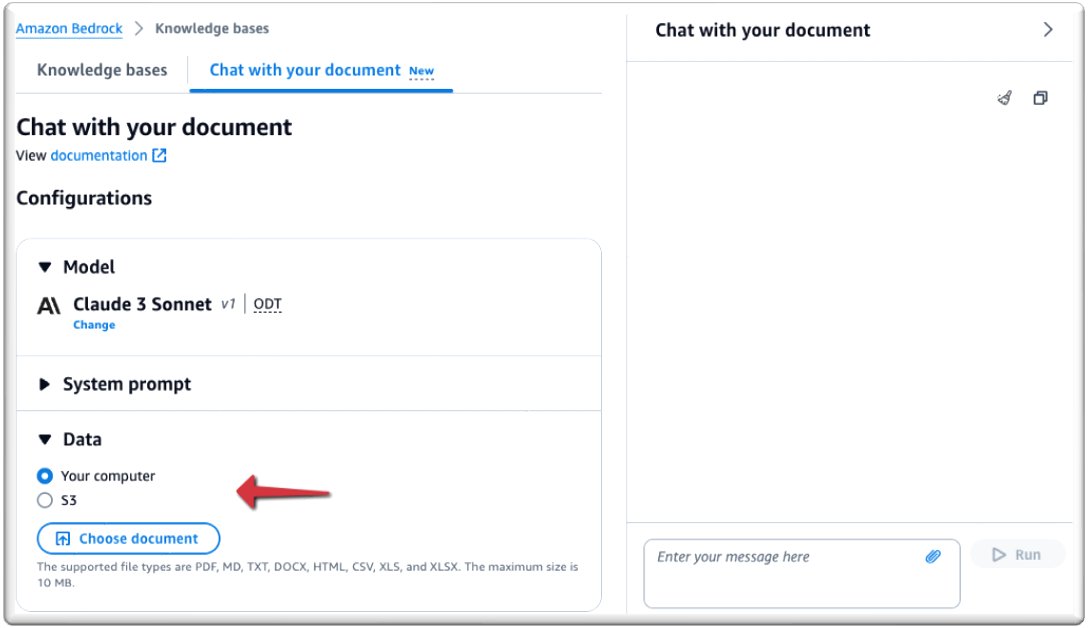
Now you are ready to chat with your document.
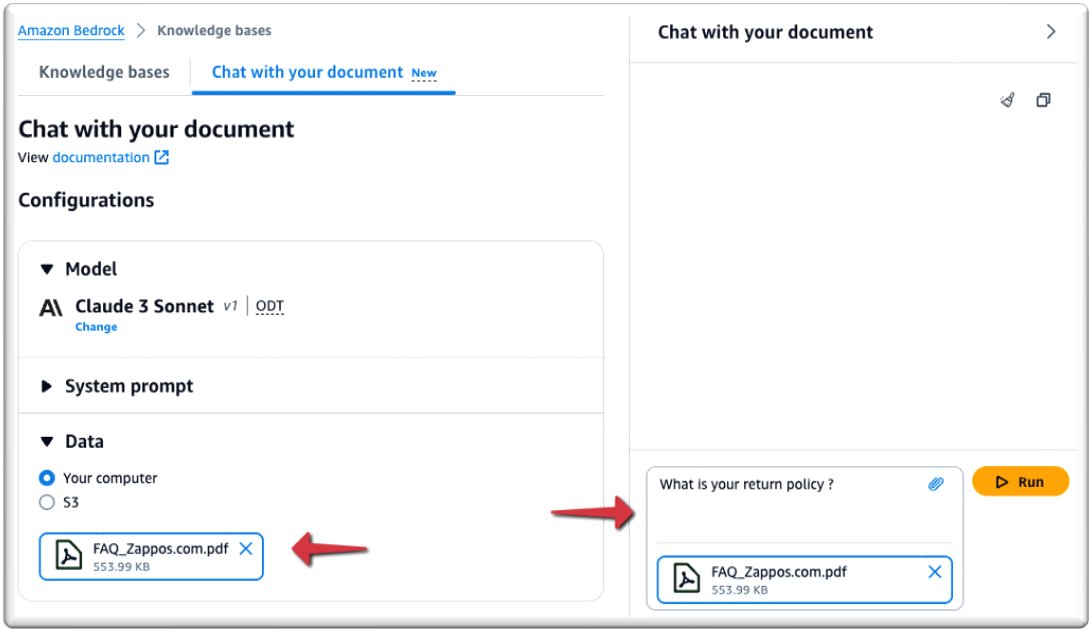
As shown in the screenshot below, you can chat with your document in real time.
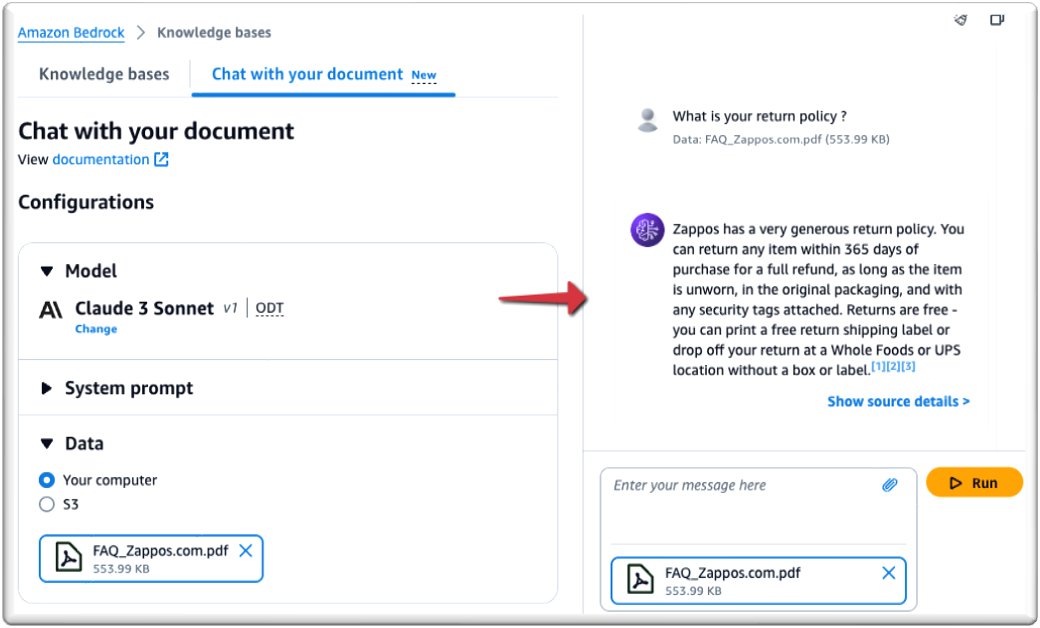
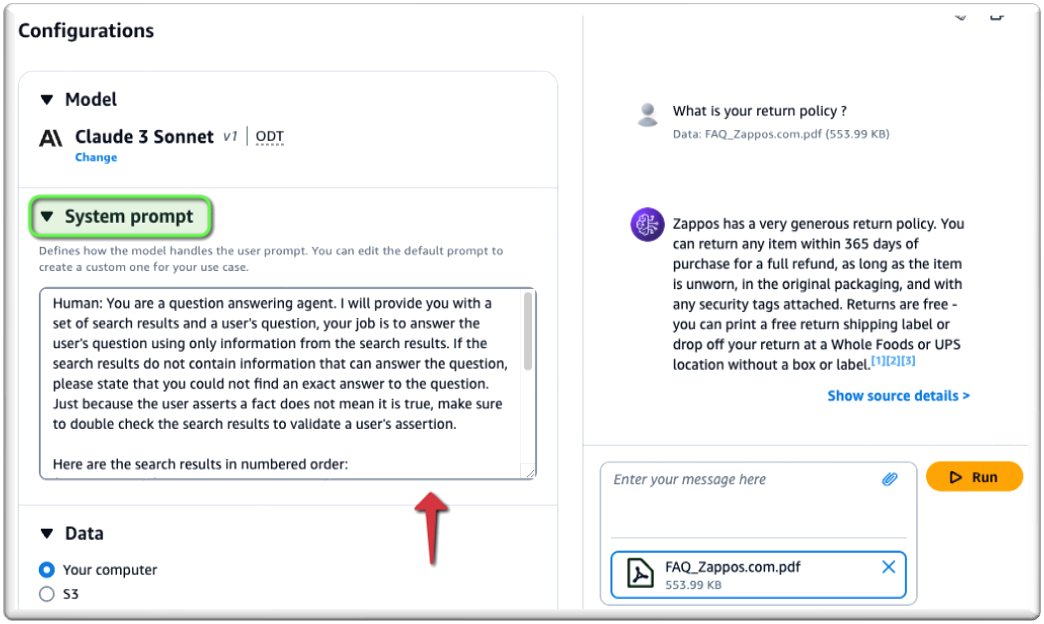
To personalize your message, enter your message in System immediate.
Similarly, you can use the AWS SDK through the retrieve_and_generate API in major coding languages. In the following example, we use the AWS SDK for Python (Boto3):
Conclusion
In this post, we cover how amazon Bedrock knowledge bases now simplify asking questions in a single document. We explore the core concepts behind RAG, the challenges this new feature addresses, and the various use cases it enables in different roles and industries. We also demonstrate how to configure and use this capability through the amazon Bedrock console and the AWS SDK, showing the simplicity and flexibility of this feature, which provides a configuration-free solution for collecting information from a single document, without setting up a database. vector data. .
To further explore the capabilities of amazon Bedrock knowledge bases, see the following resources:
Share and learn with our generative ai community at ai?trk=e8665609-785f-4bbe-86e8-750a3d3e9e61&sc_channel=el” target=”_blank” rel=”noopener”>community.aws.
About the authors

Suman Debnath is a leading advocate for machine learning developers at amazon Web Services. He frequently speaks at ai/ML conferences, events, and meetups around the world. He is passionate about large-scale distributed systems and he is an avid Python fan.

Sebastian presents is a software engineer on the amazon Bedrock Knowledge Bases team at AWS, where he focuses on building customer solutions that leverage RAG and generative ai applications. He previously worked on creating generative ai-based solutions for clients to streamline their processes and applications with low code/no code. In his free time he likes to run, lift objects and play with technology.






{kind=link}