
With the widespread implementation of large language models (LLMs) for long content generation, there is a growing need for efficient long sequence inference support. However, the key-value (KV) cache, crucial to avoid recomputation, has become a critical bottleneck, the size of which increases linearly with the length of the sequence. The autoregressive nature of LLMs requires loading the entire KV cache for each generated token, resulting in low computational core utilization and high latency. Although compression methods have been proposed, they often compromise the quality of the generation. LLMs such as GPT-4, Gemini and LWM are gaining importance in applications such as chatbots, vision generation and financial analysis. However, serving these LLMs efficiently remains a challenge due to the autoregressive nature and increasing memory footprint of the KV cache.
The above methodologies propose KV cache eviction strategies to reduce the memory footprint of the KV cache by selectively dropping peers based on the eviction policies. This allows models to operate within a limited cache budget. However, these strategies face challenges due to the potential loss of information, leading to problems such as hallucinations and contextual incoherence, particularly in long-term contexts. Speculative decoding, which involves using a lightweight preliminary model to predict next tokens, has been introduced to speed up LLM inference while preserving the model output. However, implementing this for long sequence generation presents challenges, including the need for substantial computation to train preliminary models and the risk of poor speculative performance, especially with existing untrained methods such as KV cache eviction strategies. .
Researchers from Carnegie Mellon University and Meta ai (FAIR) present Triforce, a hierarchical speculative decoding system designed for scalable generation of long sequences. TriForce uses the weights of the original model and the dynamically sparse KV cache through retrieval as a preliminary model, serving as an intermediate layer in the hierarchy. Maintaining the full cache enables superior selection of the KV cache using recovery-based redaction, which is characterized by being lossless compared to eviction-based methods such as StreamingLLM and H2O. The hierarchical system addresses dual memory bottlenecks, combining a lightweight model with a StreamingLLM cache for early speculation to reduce compose latency and speed up end-to-end inference.
TriForce features a hierarchical speculative decoding system with recovery-based KV cache selection. The hierarchical system addresses two bottlenecks, improving speed. Retrieval-based drawing segments the KV cache and highlights relevant information. Lightweight models with StreamingLLM cache speed up initial speculation and reduce compose latency. TriForce uses model weights and KV cache to improve the speed of LLM inference for long sequences. The implementation uses Transformers, FlashAttention, and PyTorch CUDA graphics, maintaining full layer sparsity and minimizing kernel launch overhead.
TriForce evaluation reveals significant speedups, up to 2.31× with a 4K KV cache for on-chip Llama2-7B128K. Offloading to consumer GPUs achieves notable efficiency, particularly with Llama2-13B-128K on two RTX 4090 GPUs being 7.94x faster than optimized systems. Llama2-7B-128K with TriForce operates at 0.108 s/token, half as slow as the autoregressive baselines on A100. Batch inference also benefits, achieving a 1.9x speedup for a batch size of six, each with 19K contexts.
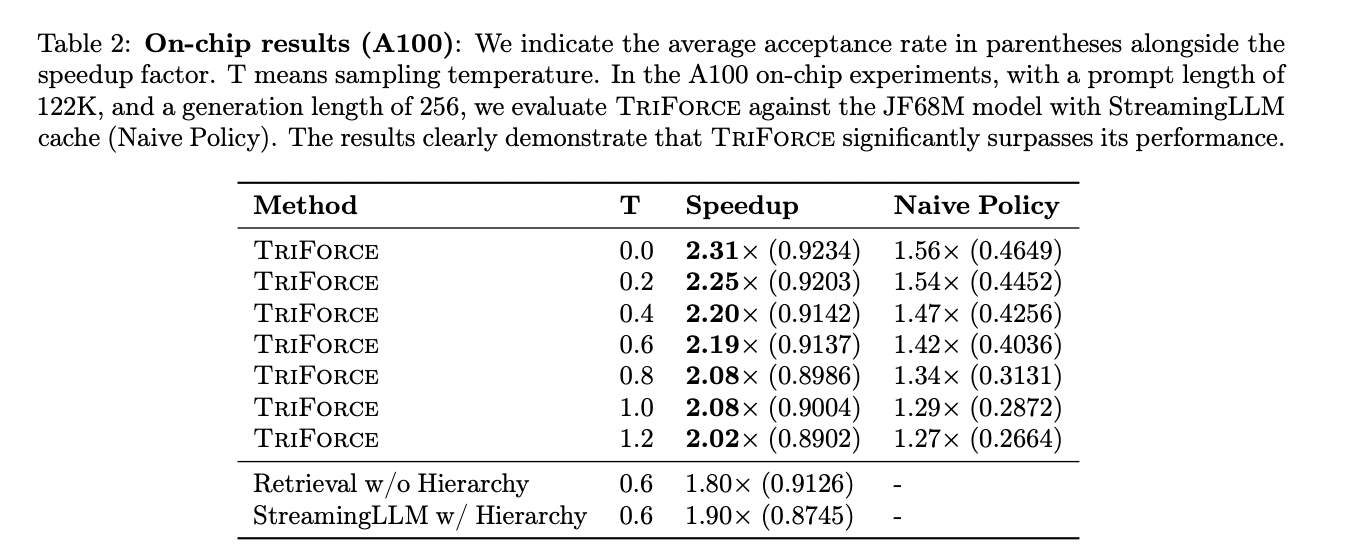
To conclude, this work presents TriForce, a hierarchical speculative decoding system aimed at efficient delivery of LLM in long contexts. TriForce addresses the dual bottlenecks of KV cache and model weights, resulting in significant speedups, including up to 2.31× on A100 GPUs and a remarkable 7.78× on RTX 4090 GPUs. TriForce achieves 0.108 s/token, half as slow as the autoregressive baselines on A100. Compared to DeepSpeed-Zero-Inference, TriForce on a single RTX 4090 GPU is 4.86x faster and achieves a 1.9x speedup with large batches, showing its potential to revolutionize modeling serving. long context.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter. Join our Telegram channel, Discord Channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our SubReddit over 40,000ml
For content association, please Complete this form here.
![]()
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering at Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}