
Chain of thought (CoT) stimulation involves instructing language models (LMs) to reason step by step, resulting in improved performance in various domains of arithmetic, common sense, and symbolic reasoning. However, conventional CoT has limitations. While it shows performance improvements on large LMs of over 100 billion parameters, it often produces repetitive and empty foundations due to its lack of fidelity to input instances and tendency to produce unaligned foundations and responses.
Recent research has explored methods to improve the reasoning abilities of small LMs to achieve computational efficiency or task performance. Fundamental distillation involves a small LM learning from a larger one to generate CoT fundamentals. However, limited research has been conducted to address the errors inherited from the teaching model. Additionally, efforts have been made to evaluate and refine the foundations beyond distillation, emphasizing logic, relevance, informational content, coherence, and repetition. Although reinforcement learning (RL) has been applied to correct misaligned LM behaviors, rational correction should be explored.
Researchers from Penn State University and amazon AGI propose a unique method, LM-guided CoT, using two different LMs for CoT reasoning. The method involves a small LM for rationale generation and a large LM for response prediction. Initially, a basic knowledge distillation (KD) technique is applied to the small LM using foundations generated by the large LM, narrowing the gap in its reasoning capabilities. Subsequently, detailed measurements, including relevance, recency, logic, consistency, coherence, fluency, naturalness, and readability, are used to optimize the LM distilled from knowledge through RL. This approach improves the quality of the generated foundations and ultimately improves the performance of CoT reasoning.
The LM-guided CoT framework features two LMs: a lightweight model (MS) to generate optimal foundations and a large model (ML) to predict outcomes based on these foundations. Fundamental distillation involves learning MS from ML-generated fundamentals, with filtering to avoid inheritance of errors. Rational refinement employs eight measures of linguistic aspects, initially annotated manually and then automated for RL-based EM training. Proximate Policy Optimization (PPO) is used to update MS with rewards based on specific aspect evaluation metrics and specific task accuracy, incorporating penalties for model consistency.
The study compares ML performance (equivalent to FLAN-T5 XXL) with and without CoT cues, and finds a drop in accuracy due to limited reasoning abilities in long contexts. LM-guided CoT, especially with KD alone, outperforms the original CoT prompts by 2% and 10% in HotpotQA and 2WikiMultiHopQA, respectively. This approach significantly improves response prediction and quality of justification, especially for questions with extensive contexts, outperforming CoT+SC prompts and rivaling standard prompts in accuracy.
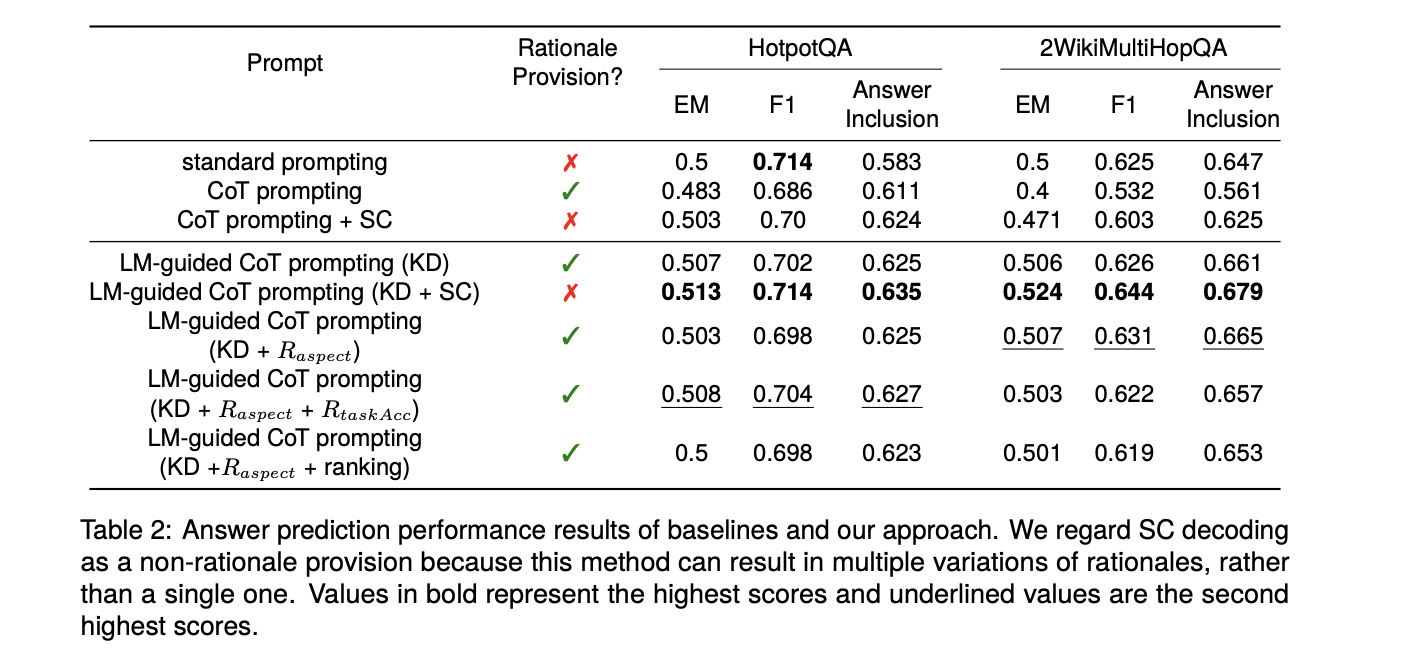
In conclusion, this research presents LM-guided CoT, a framework that improves CoT cues by decomposing them into RL-optimized response prediction and rationale generation steps. By outperforming all baselines, it proves to be an effective and resource-efficient solution to CoT challenges. However, selecting high-quality foundations does not consistently improve task performance, suggesting the need to balance LM-generated foundations and overall task efficiency for optimal results.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter. Join our Telegram channel, Discord channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our SubReddit over 40,000ml
Do you want to be in front of 1.5 million ai audiences? Work with us here
![]()
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering at Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}