
In the rapidly advancing field of computer vision, the development of models capable of learning and adapting through minimal human intervention has opened new avenues of research and application. A key area of this field is the use of machine learning to allow models to switch between tasks efficiently, improving their flexibility and applicability in various scenarios.
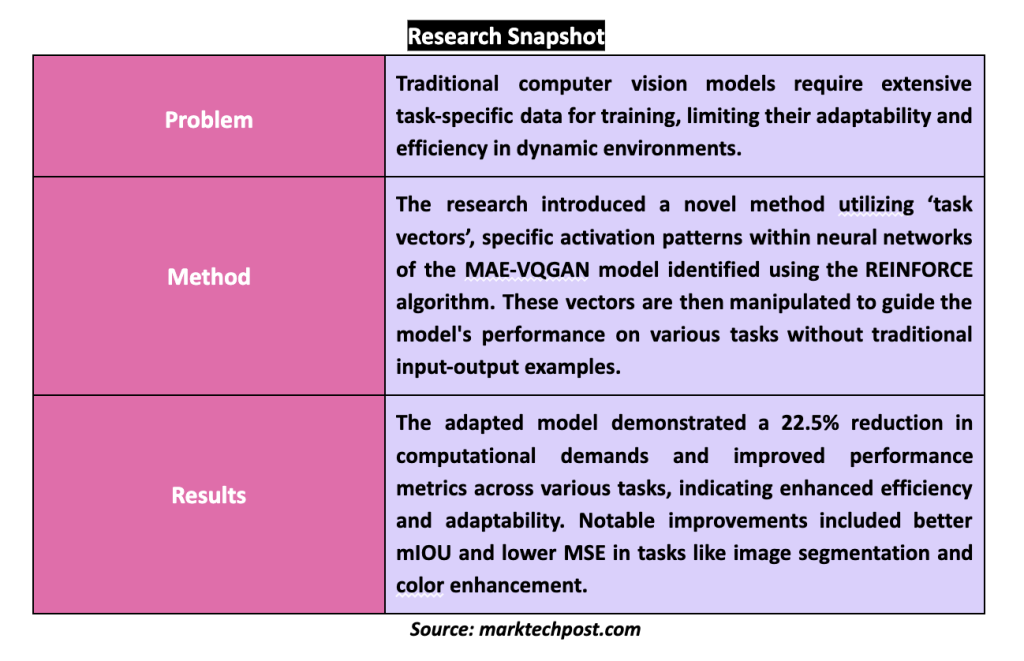
Computer vision systems require comprehensive data sets tailored to each task to function effectively. This need for large amounts of task-specific data posed a significant challenge, limiting the speed and adaptability of model deployment in dynamic environments. Recently, progress has been made in introducing in-context learning models that adapt to new tasks using only a few contextual examples. This method simplifies the training process and reduces dependence on large data sets.
Researchers at UC Berkeley and Tel Aviv University present a breakthrough in task adaptability without the need for input and output examples. His research focuses on identifying and utilizing “task vectors,” specific patterns of activations within a model's neural network that encode task-related information. These vectors can be manipulated to direct the model's focus, allowing it to switch tasks with minimal external input.
The researchers' methodology involves analyzing the activation patterns of the MAE-VQGAN model, a leading visual cueing model. By examining these activations, the team identified specific vectors that consistently encoded information relevant to various visual tasks. Using the REINFORCE algorithm, they strategically searched and modified these task vectors to optimize model performance across multiple tasks.
The modified model reduced its computational demands by 22.5% by employing task vectors, significantly reducing the required resources while maintaining high accuracy. The experiments showed higher task performance, with the patched model achieving better results than the original configuration on several benchmarks. For example, the model demonstrated better mean intersection over union (mIOU) and lower mean square error (MSE) metrics in tasks such as image segmentation and color enhancement.
This innovative approach leverages the inherent capabilities of neural networks to identify and tune task-specific vectors, and researchers have effectively demonstrated a method to improve the adaptability and efficiency of a model. The implications of these findings are enormous and suggest that future models could be designed with an inherent ability to adapt on the fly to new tasks, thereby revolutionizing their use in real-world applications.
Research Overview
In conclusion, the study effectively addresses the limitations of traditional computer vision models, which rely heavily on extensive task-specific data sets, by introducing an innovative method that uses internal “task vectors.” These vectors, specific activation patterns within the neural network of the MAE-VQGAN model, are identified and manipulated to improve task adaptability without traditional training data sets. The results are significant: a 22.5% reduction in computational demands and better performance across multiple tasks, highlighted by better mIOUs and lower MSE scores.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter. Join our Telegram channel, Discord channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our SubReddit over 40,000ml
Do you want to be in front of 1.5 million ai audiences? Work with us here
![]()
Hello, my name is Adnan Hassan. I'm a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a double degree from the Indian Institute of technology, Kharagpur. I am passionate about technology and I want to create new products that make a difference.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}