
Machine learning (ML) may seem complex, but what if you could train a model without writing any code? This guide unlocks the power of ML for everyone by demonstrating how to train an ML model without code.
Data set used
The Iris dataset is a classic in the field of machine learning and offers an easy path for beginners to explore the process of training a machine learning model. It consists of 150 samples of three species of Iris (Iris setosa, Iris virginica and Iris versicolor), with four characteristics each: sepal length, sepal width, petal length and petal width.
This project presents ai/home/ai-for-data-analytics” target=”_blank” rel=”noreferrer noopener nofollow”>Julio ai, a powerful no-code ai tool that simplifies machine learning. Using natural language commands, Julius generates and executes the Python code necessary for each step. We will take advantage of Julius to classify Iris plants into their respective species according to characteristics such as the dimensions of the sepals and petals. This demonstrates how you can train a machine learning model completely without writing code!
Steps involved in training ML model without code
Traditionally, training machine learning models required coding experience. But with no-code tools like Julius, anyone can participate! This guide provides a step-by-step approach to training a model on the Iris dataset, using Julius and natural language commands throughout. No coding experience necessary – let's explore the process!
- Import the data set
- Initial data evaluation
- Data Cleaning
- Feature Selection
- Data division
- Choose the type of model
- Setting up the model
- Training the model
- Model performance evaluation
- Adjustments and improvements
Read also: Guide to academic data analysis with Julius ai
Starting
Import the Iris dataset into Julius
Start by navigating to Julius.ai and importing the Iris dataset. Typically, you would upload a compatible file containing your data set (CSV, Excel, or Google Sheets). However, since Iris is such a well-known data set, you can simply request ai/home/ai-for-data-analytics” target=”_blank” rel=”noreferrer noopener nofollow”>July to “Load Iris Dataset” and you can write Python code to extract the data set.
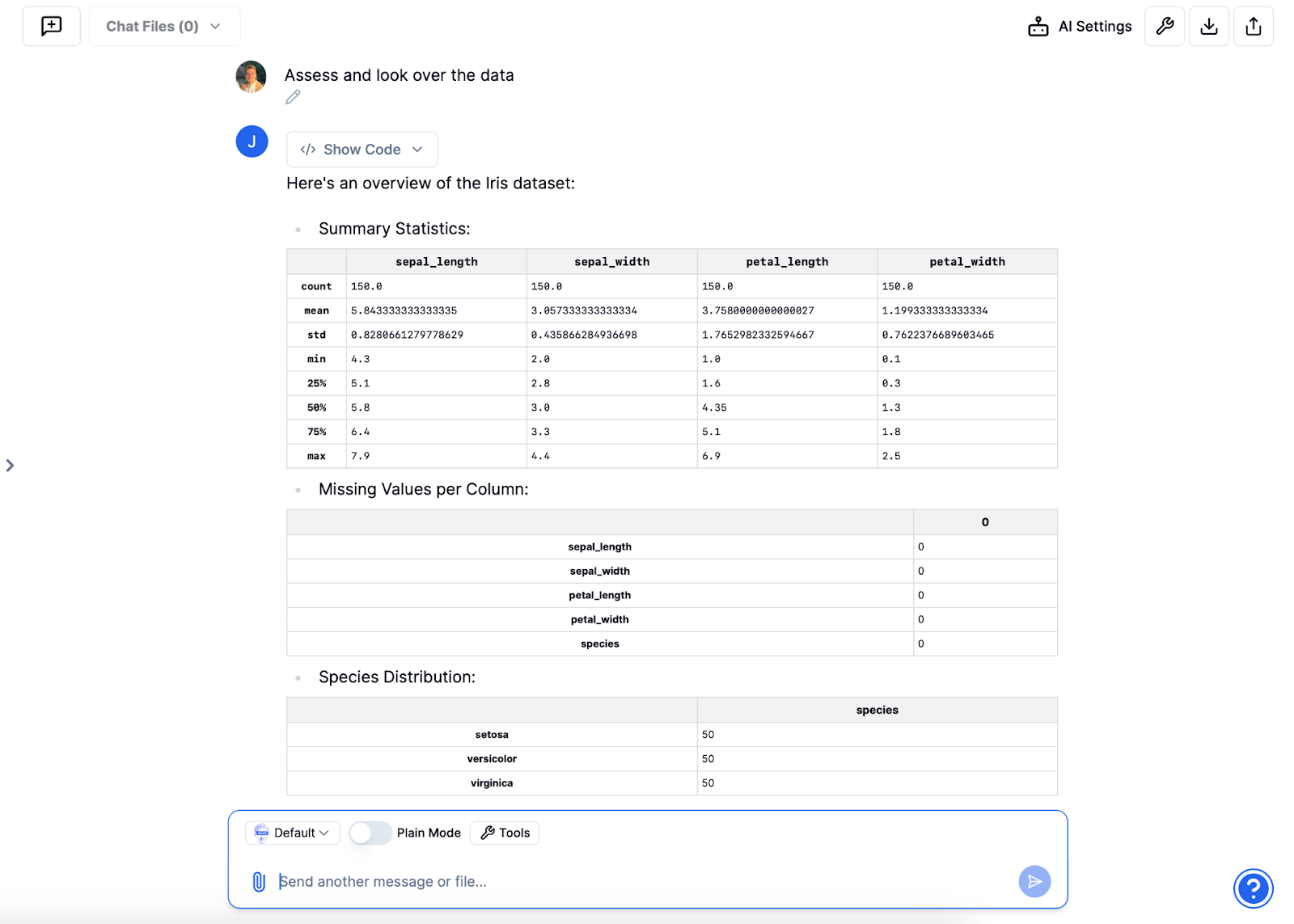
Initial data evaluation
Once the data set is imported, you can request an initial evaluation to help Julius understand its structure and content. This includes producing summary statistics, identifying the number of features, recognizing data types, and detecting missing values, if any.
Preparing your data for training
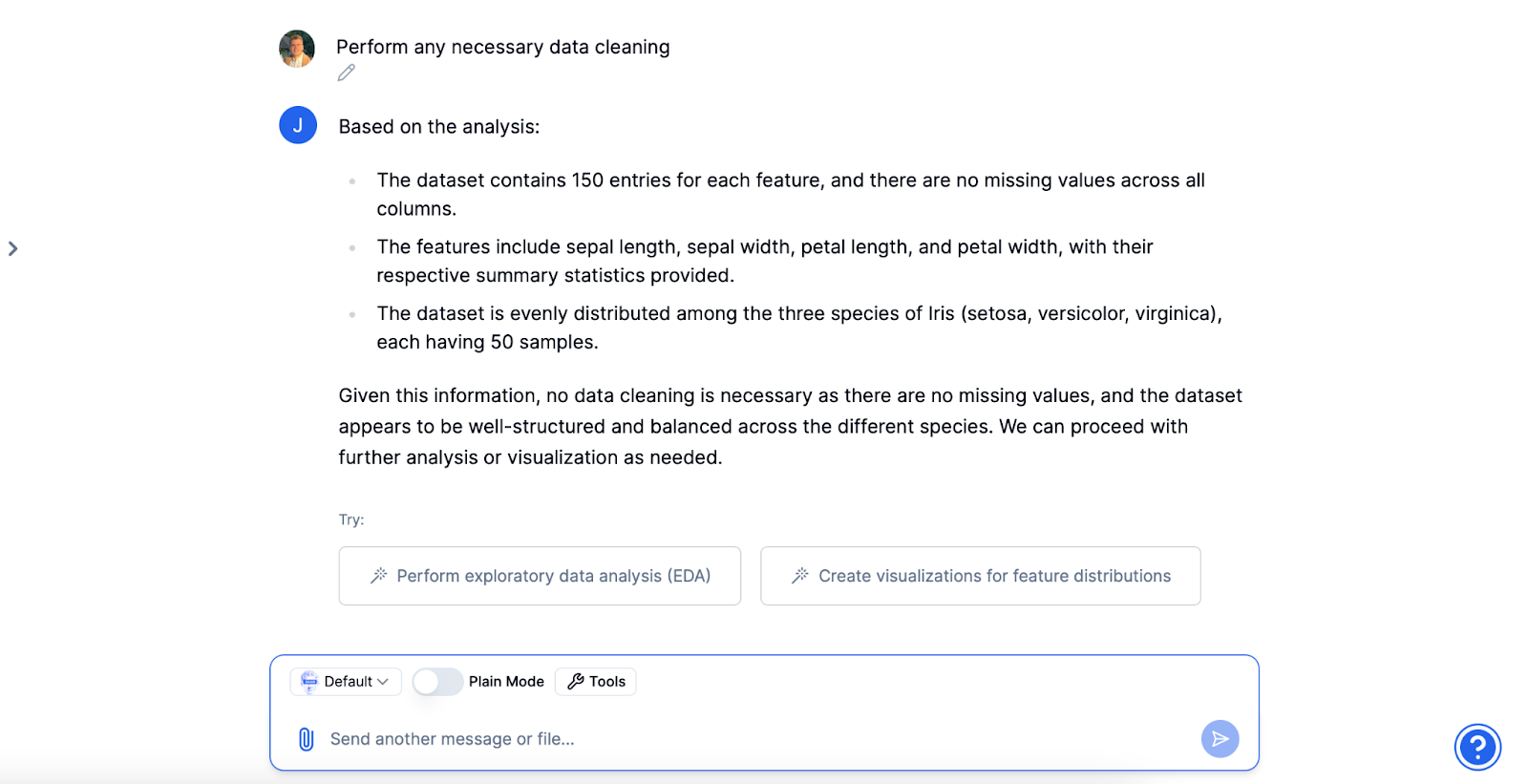
Data Cleaning
The Iris data set typically requires minimal cleaning. But don't worry, Julius is here to help you! It will automatically look for missing or inconsistent data and suggest solutions. In this case, Julius will ensure that all numeric values are correctly formatted and that there are no missing entries, all without you writing a single line of code.
Feature Selection
Since all four features in the Iris dataset contribute to classifying species, we will use all of them. However, Julius allows you to explore the importance of features for more complex data sets, giving you valuable insights into your data.”
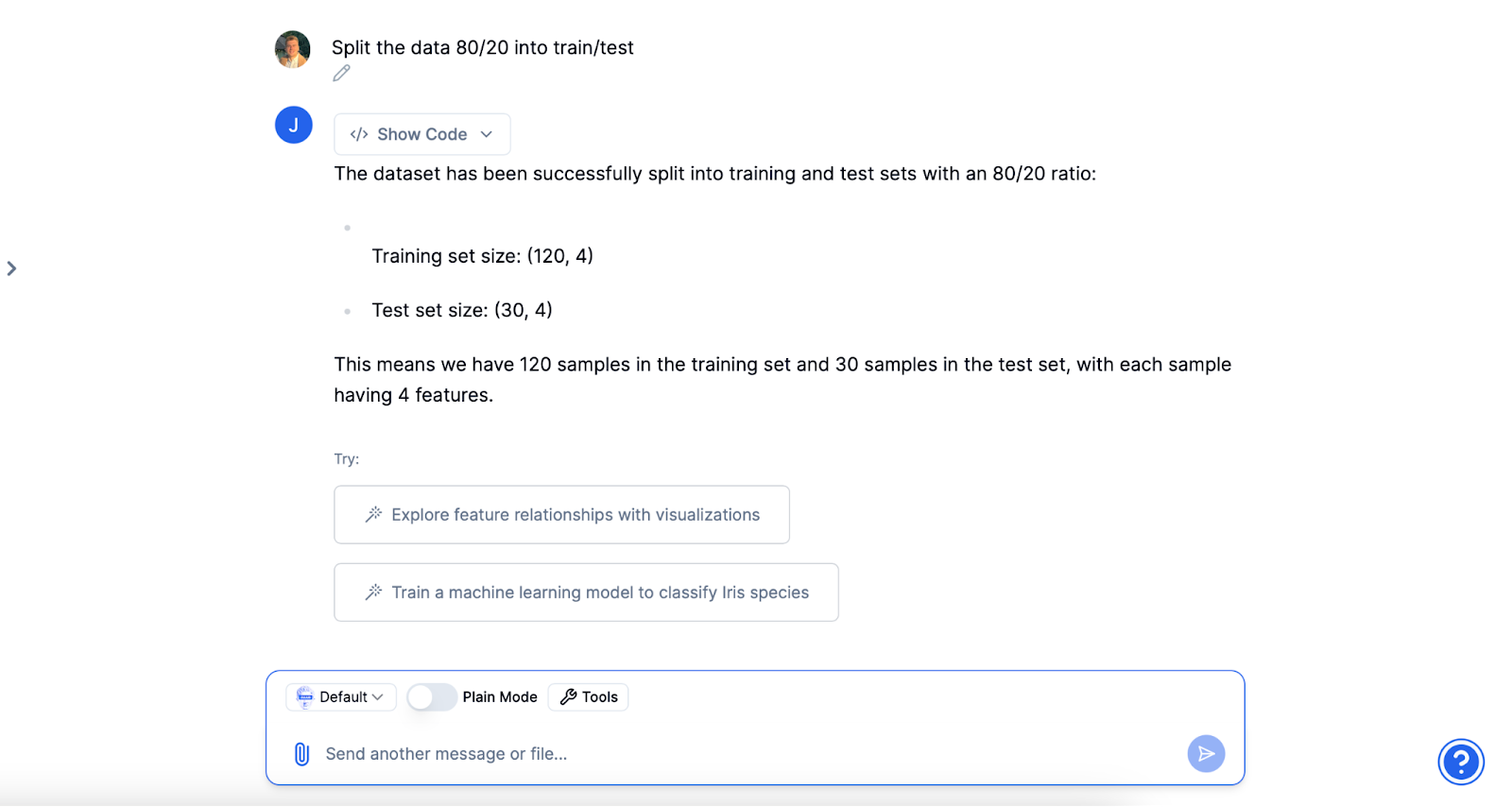
Data division
Before training, split your data into training and test sets. A common split ratio is 80% for training and 20% for testing. Julius automates this process, ensuring that his model is trained on one part of the data set and tested on an unseen part for unbiased evaluation.
Training your machine learning model
Choose your model type
For the Iris data set, a classification model is appropriate. Julius provides several classification algorithms, such as logistic regression, decision trees, and k-nearest neighbors (KNN). For beginners, KNN is a good start due to its simplicity and effectiveness.
Configure the model
With Julius, setting up your model involves selecting the algorithm (e.g. KNN) and setting the relevant parameters. For KNN, you can start with the default number of neighbors (for example, 5) and adjust it based on performance.
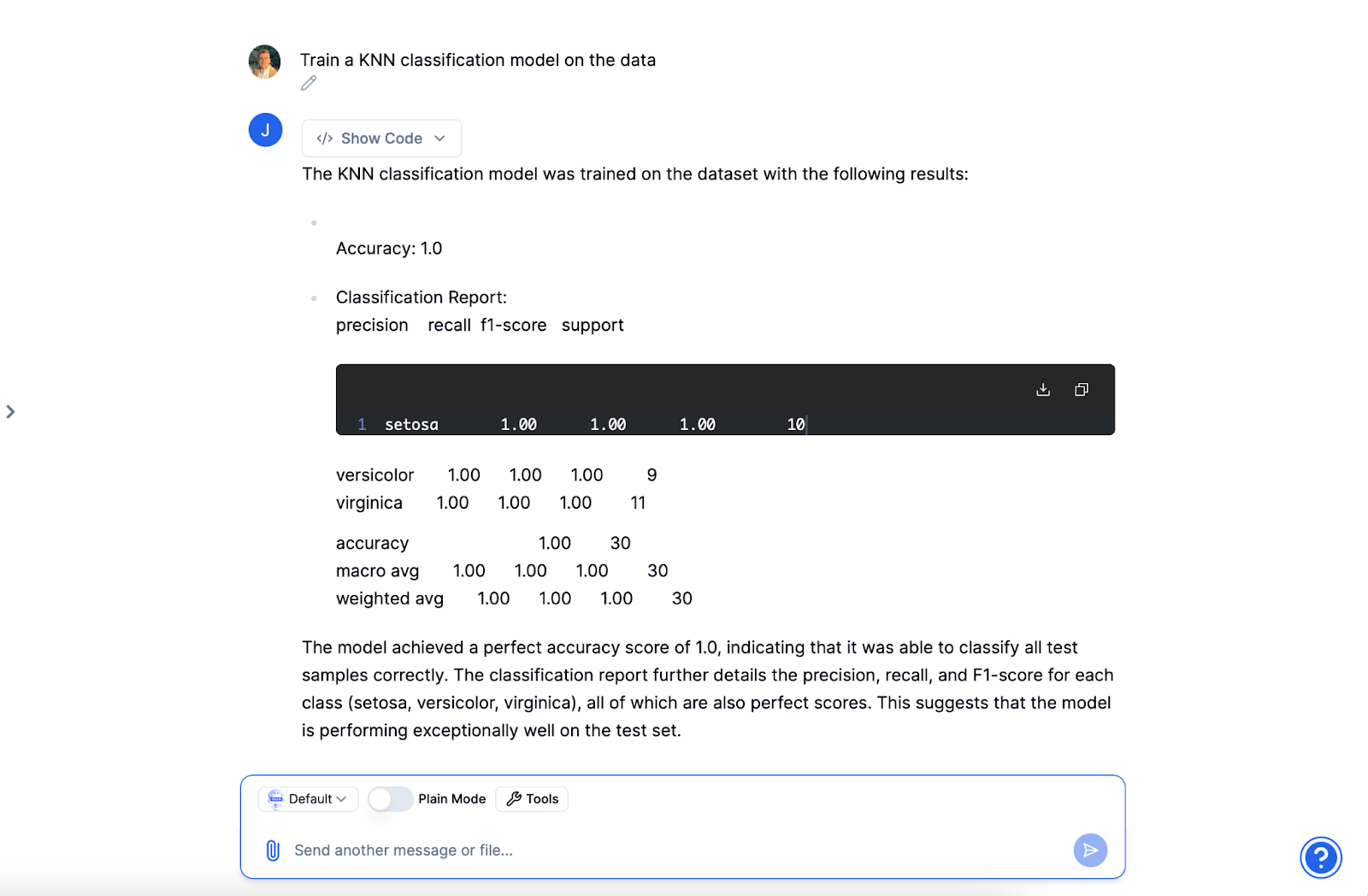
Train the model
Begin the training process by instructing Julius to apply the selected algorithm to your training data. Julius manages computational tasks and keeps you informed with updates on training progress and completion.
Model performance evaluation
Performance metrics
After training, Julius presents the model's performance metrics such as accuracy, precision, recall, and F1 score. These metrics help evaluate how well the model has learned to classify Iris species. Since this is a relatively simple model, the accuracy was perfect and each species was correctly identified.
Adjustments and improvements
If the initial results are not satisfactory, you can adjust the model parameters (for example, change the number of neighbors in KNN) or try a different algorithm. Julius facilitates this experimentation and guides you towards improving model performance.
Exploring Beyond Julius: Alternative No-Code Machine Learning Solutions
While Julius offers an easy-to-use platform for beginners to dive into machine learning, it's just the tip of the iceberg. The landscape of no-code machine learning tools is vast, providing ample opportunities for enthusiasts and professionals alike to build, train, and deploy models without delving into code.
Platforms like Google AutoML and Microsoft Azure Machine Learning Studio have democratized access to powerful machine learning capabilities. These platforms not only simplify the model training process but also offer advanced features for more complex projects. Whether you're looking to build custom image recognition models, forecast business metrics, or analyze sentiment from text, there's a no-code solution for you.
Ideas for your next projects without code
Delving into the world of no-code machine learning, here are three interesting project ideas that beginners can tackle to expand their skills and understanding of machine learning:
- stock market Prediction: Use historical stock price data to predict future trends. By feeding your no-code platform with time series data, you can explore various algorithms to forecast stock prices. This project offers hands-on experience with financial data sets and introduces you to the concepts of regression analysis and time series forecasting.
- Customer sentiment analysis: Analyze customer reviews or social media posts to gauge sentiment toward products or brands. This project involves classifying text data into categories such as positive, negative or neutral. It's a great way to learn about natural language processing (NLP) and understand how machine learning can extract information from text.
- Image Classification for Retail: Create a model that can classify product images into categories, such as types of clothing or furniture, based on photographs. This project allows you to delve deeper into computer vision and learn how machine learning models can interpret and categorize visual data. A project of this type can be especially useful for e-commerce platforms looking to automate the categorization of their product listings.
Each of these projects not only offers a different challenge, but also introduces you to different types of data and machine learning algorithms, expanding your experience and showing the versatility of no-code machine learning platforms.
Conclusion
Train a machine learning model on the Iris dataset with ai/home/ai-for-data-analytics” target=”_blank” rel=”noreferrer noopener nofollow”>July introduces you to the essential steps of machine learning: importing data, preparing it for training, choosing and configuring a model, and evaluating performance. Through this hands-on experience, you'll gain insight into the practical aspects of machine learning, paving the way for tackling more complex projects.
This guide simplifies the process into manageable steps, ensuring that even those new to machine learning can successfully train a model with Julius. As you become more comfortable with these steps, you'll find Julius to be an invaluable tool in your machine learning efforts, capable of handling increasingly sophisticated tasks with ease.





{kind=link}