
Advances in artificial intelligence (ai) and machine learning (ML) are revolutionizing the financial industry for use cases such as fraud detection, creditworthiness assessment, and trading strategy optimization. To develop models for such use cases, data scientists need access to various data sets, such as credit decision engines, customer transactions, risk appetite, and stress tests. Managing proper access control to these data sets among the data scientists working on them is crucial to meeting strict regulatory and compliance requirements. Typically, these data sets are aggregated into a centralized Amazon Simple Storage Service (Amazon S3) location from multiple business applications and enterprise systems. Data scientists in all business units working on developing models using Amazon SageMaker have access to relevant data, which can lead to the need to manage access controls at the prefix level. With an increase in use cases and data sets using bucket policy statements, managing cross-account access on a per-application basis is too complex and lengthy for a bucket policy to accommodate.
Amazon S3 Access Points simplify managing and securing data access at scale for applications that use shared data sets on Amazon S3. You can create unique host names using access points to apply distinct and secure network permissions and controls to any requests made through the access point.
S3 access points simplify the management of specific access permissions for each application that accesses a shared data set. Enables high-speed, secure data copying between access points in the same region using internal AWS and VPC networks. S3 access points can restrict access to VPCs, allowing you to secure data within private networks, test new access control policies without affecting existing access points, and configure VPC endpoint policies to restrict access. access to account ID specific S3 buckets.
This post explains the steps required to configure S3 access points to enable cross-account access from a SageMaker notebook instance.
Solution Overview
For our use case, we have two accounts in an organization: account A (1111111111111), which is used by data scientists to develop models using a SageMaker notebook instance, and account B (222222222222), which requires data sets in bucket S3. test-bucket-1. The following diagram illustrates the architecture of the solution.
To deploy the solution, complete the following high-level steps:
- Configure account A, including VPC, subnet security group, VPC gateway endpoint, and SageMaker notebook.
- Configure account B, including S3 bucket, access point, and bucket policy.
- Configure AWS Identity and Access Management (IAM) permissions and policies on account A.
You must repeat these steps for each SageMaker account that needs access to Account B's shared data set.
The names of each resource mentioned in this post are examples; you can replace them with other names depending on your use case.
Set up account A
Complete the following steps to set up Account A:
- Create a VPC called
DemoVPC. - Create a subnet called
DemoSubnetin the VPCDemoVPC. - Create a security group called
DemoSG. - Create a VPC S3 gateway endpoint named
DemoS3GatewayEndpoint. - Create the SageMaker Execution role.
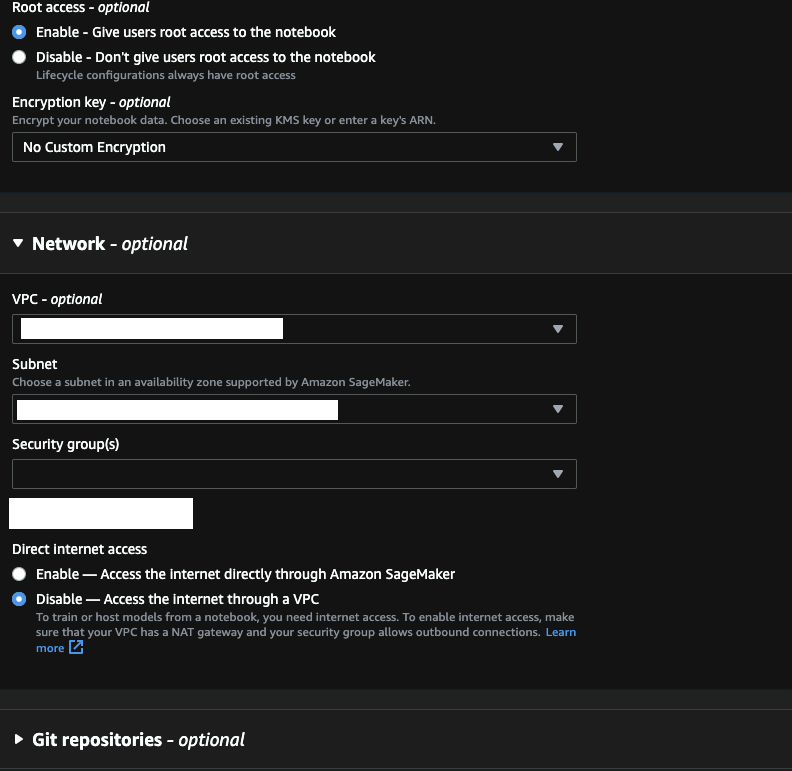
- Create a notebook instance called
DemoNotebookInstanceand security guidelines as described in How to configure security in Amazon SageMaker.- Specify the Sagemaker runtime role you created.
- For notebook network settings, specify the VPC, subnet, and security group that you created.
- make sure of that Direct Internet Access it's off.
Assign permissions to the role in later steps after creating the necessary dependencies.
Set up account B
To set up Account B, complete the following steps:
- In account B, create an S3 bucket called
test-bucket-1following Amazon S3 security instructions. - Upload your file to the S3 bucket.
- Create an access point called
test-ap-1in account B.- Do not change or edit any Lock settings from public access for this access point (all public access must be blocked).
- Attach the following policy to your access point:
The actions defined in the code above are example actions for demonstration purposes. You can define the actions based on your requirements or use case.
- Add the following bucket policy permissions to access the access point:
The actions above are examples. You can define the actions according to your requirements.
Configure IAM permissions and policies
Complete the following steps on Account A:
- Confirm that the SageMaker runtime role has the AmazonSagemakerFullAccess custom IAM inline policy, which looks like the following code:
The actions in the policy code are sample actions for demonstration purposes.
- Go to the
DemoS3GatewayEndpointendpoint you created and add the following permissions:
- To obtain a list of prefixes, run the describe-prefix-lists command from the AWS command-line interface (AWS CLI):
- On account A, go to the security group.
DemoSGfor the target SageMaker notebook instance - Low Exit rulescreate an outbound rule with all the traffic either All TCPand then specify the destination as the ID of the prefix list you retrieved.
This completes the setup on both accounts.
Try the solution
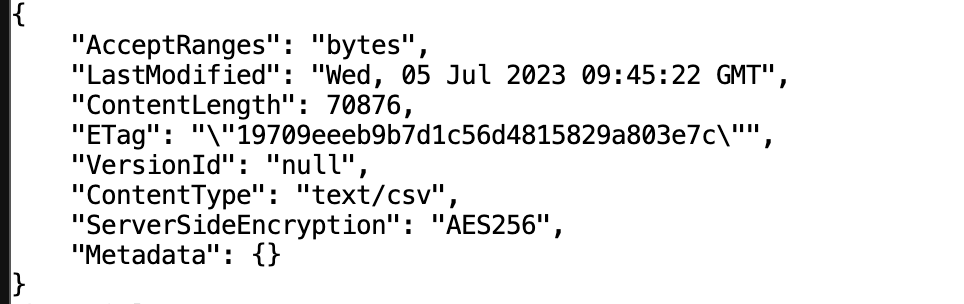
To validate the solution, go to the SageMaker notebook instance terminal and enter the following commands to list the objects through the access point:
- To list objects correctly through the S3 access point
test-ap-1:

- To get the objects successfully through the S3 access point
test-ap-1:
Clean
When you are done testing, delete the S3 access points and S3 buckets. Additionally, delete any instances of the Sagemaker notebook to stop incurring charges.
Conclusion
In this post, we show how S3 hotspots enable cross-account access to large shared data sets from SageMaker notebook instances, bypassing size restrictions imposed by bucket policies while configuring access management. scale on shared data sets.
For more information, see Easily manage shared data sets with Amazon S3 access points.
About the authors
 Kiran Khambte works as a senior technical account manager at Amazon Web Services (AWS). As a TAM, Kiran plays a role as a technical expert and strategic guide to help enterprise clients achieve their business objectives.
Kiran Khambte works as a senior technical account manager at Amazon Web Services (AWS). As a TAM, Kiran plays a role as a technical expert and strategic guide to help enterprise clients achieve their business objectives.
 Ankit Soni With a total of 14 years of experience, he holds the position of Principal Engineer at NatWest Group, where he has served as Cloud Infrastructure Architect for the last six years.
Ankit Soni With a total of 14 years of experience, he holds the position of Principal Engineer at NatWest Group, where he has served as Cloud Infrastructure Architect for the last six years.
 Kesaraju Sai Sandeep is a Cloud Engineer specialized in Big Data Services at AWS.
Kesaraju Sai Sandeep is a Cloud Engineer specialized in Big Data Services at AWS.






{kind=link}