

Image by author
Accessing ChatGPT online is very simple: all you need is an Internet connection and a good browser. However, by doing so, you may be compromising your privacy and data. OpenAI stores your quick responses and other metadata to retrain the models. While this may not be a concern for some, others who care about privacy may prefer to use these models locally without any external tracking.
In this post, we'll look at five ways to use large language models (LLMs) locally. Most of the software is compatible with major operating systems and can be easily downloaded and installed for immediate use. By using LLM on your laptop, you have the freedom to choose your own model. You just need to download the model from the HuggingFace center and start using it. Additionally, you can grant these applications access to your project folder and generate contextual responses.
GPT4All is a cutting-edge open source software that allows users to download and install cutting-edge open source models with ease.
Just download GPT4ALL from the website and install it on your system. Next, choose the model that suits your needs from the panel and start using it. If you have CUDA (Nvidia GPU) installed, GPT4ALL will automatically start using your GPU to generate fast responses of up to 30 tokens per second.
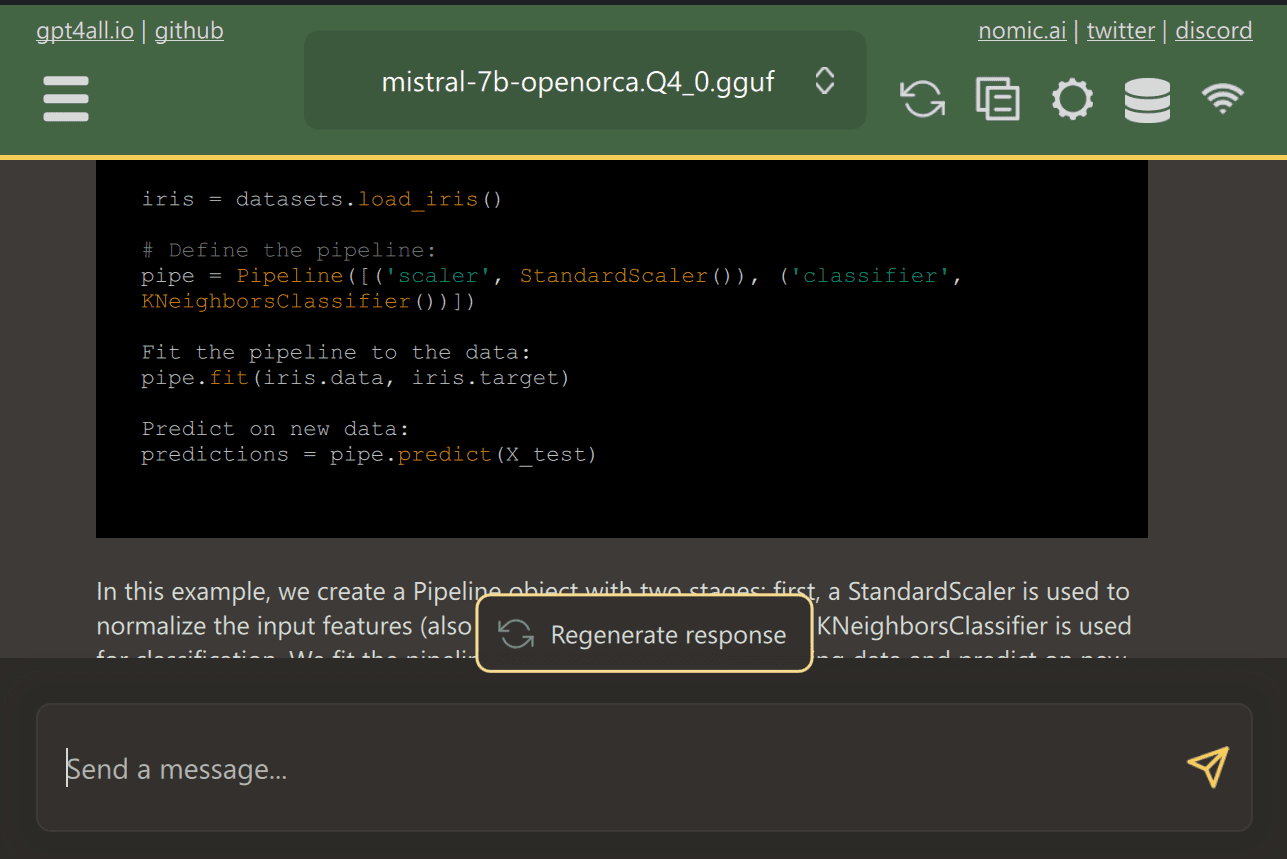
You can provide access to multiple folders containing important codes and documents, and GPT4ALL will generate responses using augmented generation-recovery. GPT4ALL is easy to use, fast, and popular among the ai community.
Read the blog on GPT4ALL to learn more about features and use cases: The ultimate open source large language model ecosystem.
ai/” rel=”noopener” target=”_blank”>LM Studio is a new software that offers several advantages over GPT4ALL. The user interface is excellent and you can install any model from Hugging Face Hub with a few clicks. Additionally, it provides GPU offloading and other options that are not available in GPT4ALL. However, LM Studio is closed source and does not have the option to generate contextual responses by reading project files.
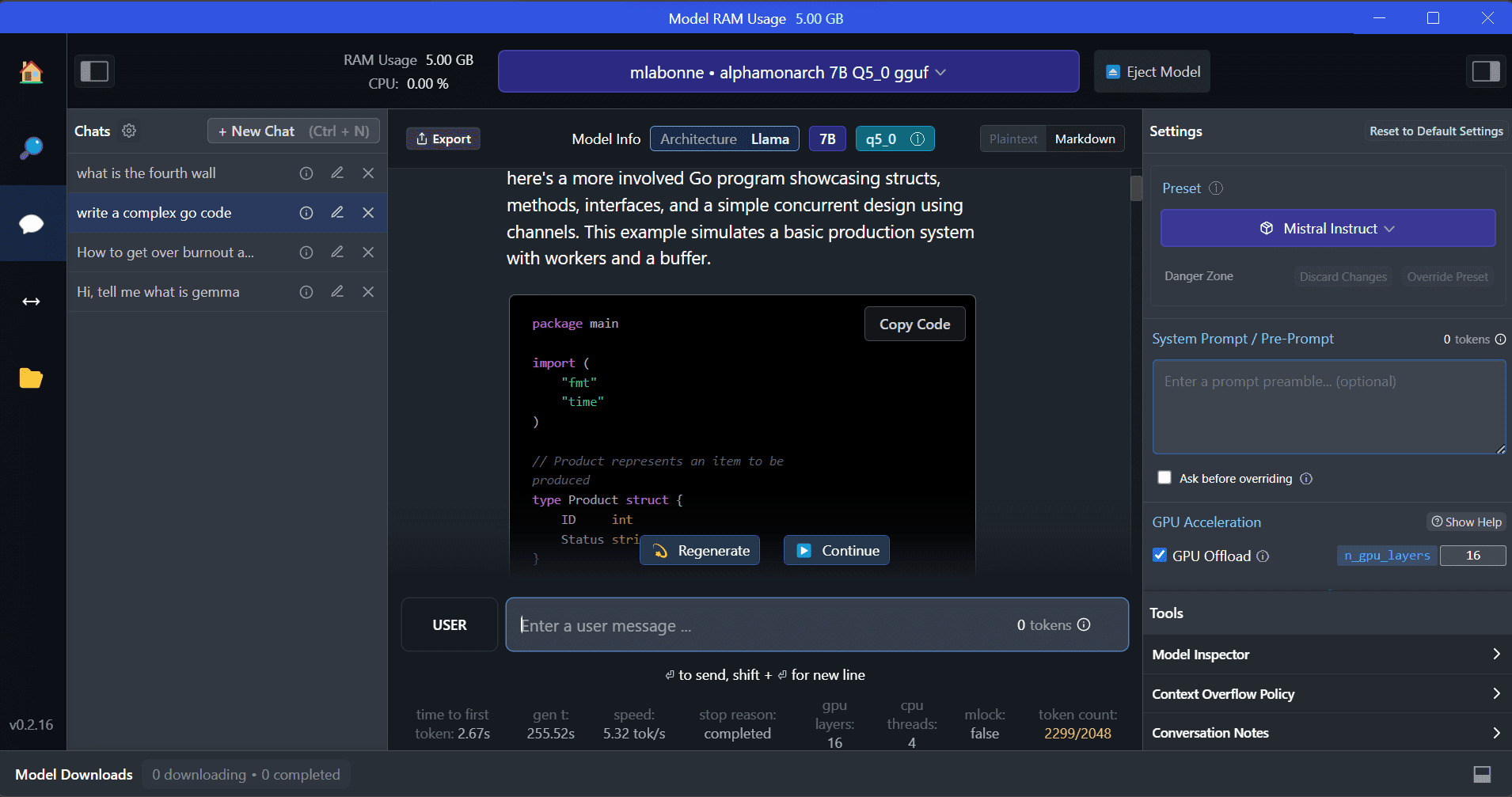
LM Studio offers access to thousands of open source LLMs, allowing you to start a local inference server that behaves like the OpenAI API. You can modify your LLM answer through the interactive user interface with multiple options.
Also read Run an LLM locally with LM Studio to learn more about LM Studio and its key features.
Be is a command line interface (CLI) tool that allows fast operation for large language models such as Llama 2, Mistral and Gemma. If you are a hacker or a developer, this CLI tool is a fantastic option. You can download and install the software and use the command `the llama run llama2` to start using the LLaMA 2 model. You can find other model commands in the GitHub repository.

It also allows you to start a local HTTP server that can be integrated with other applications. For example, you can use the Code GPT VSCode extension by providing the local server address and start using it as an ai coding assistant.
Improve your coding and data workflow with these 5 best ai coding assistants.
LLaMA.cpp is a tool that offers both a CLI and a graphical user interface (GUI). It allows you to use any open source LLM locally without any problem. This tool is highly customizable and provides quick answers to any query as it is completely written in pure C/C++.
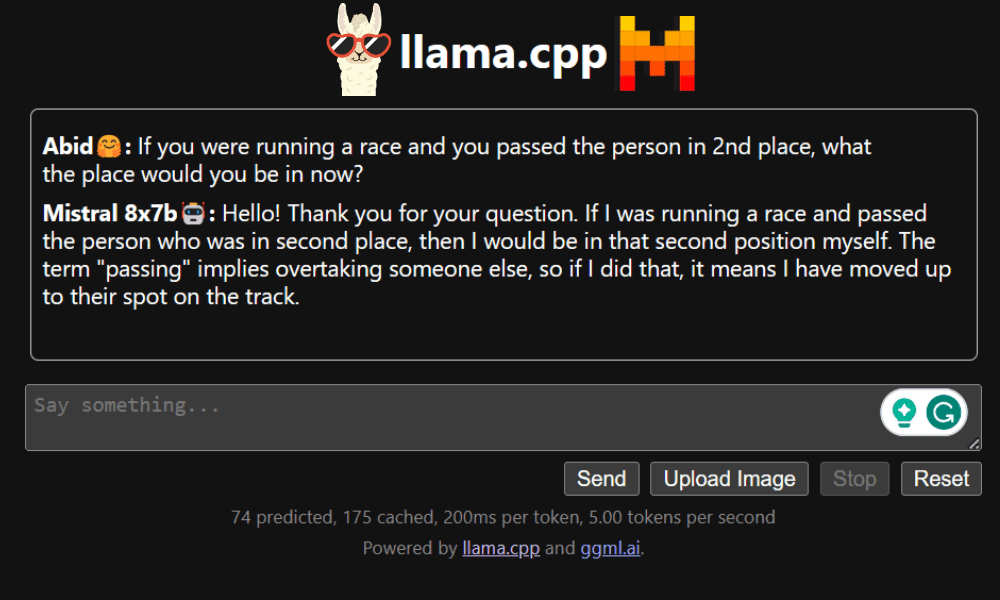
LLaMA.cpp supports all types of operating systems, CPU and GPU. You can also use multi-modal models such as LLaVA, BakLLaVA, Obsidian and ShareGPT4V.
Learn how to run Mixtral 8x7b on Google Colab for free using LLaMA.cpp and Google GPUs.
Wear ai-on-rtx/chat-with-rtx-generative-ai/” rel=”noopener” target=”_blank”>NVIDIA Chat with RTX, you need to download and install the Windows 11 app on your laptop. This app is compatible with laptops that have an NVIDIA RTX 30 series or 40 series graphics card with at least 8 GB of RAM and 50 GB of free storage space. Additionally, your laptop must have at least 16GB of RAM to run Chat with RTX without any issues.
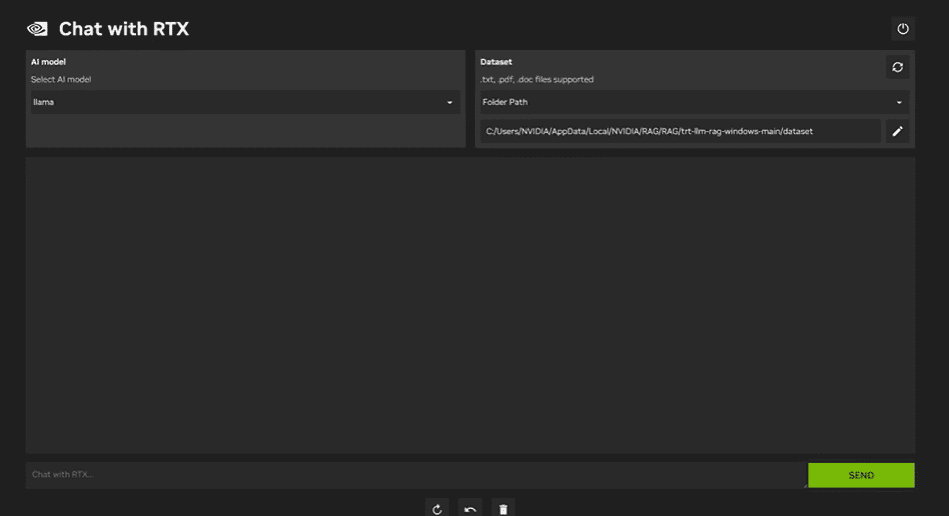
With Chat with RTX, you can run the LLaMA and Mistral models locally on your laptop. It is a fast and efficient application that can even learn from documents you provide or YouTube videos. However, it is important to note that Chat with RTX is based on TensorRTX-LLM, which is only supported on 30-series GPUs or later.
If you want to take advantage of the latest LLM and keep your data secure and private, you can use tools like GPT4All, LM Studio, Ollama, LLaMA.cpp, or NVIDIA Chat with RTX. Each tool has its own unique strengths, whether it's an easy-to-use interface, command-line accessibility, or support for multimodal models. With the right setup, you can have a powerful ai assistant that generates personalized responses based on context.
I suggest starting with GPT4All and LM Studio as they cover most of the basic needs. After that, you can try Ollama and LLaMA.cpp and finally try Chat with RTX.
Abid Ali Awan (@1abidaliawan) is a certified professional data scientist who loves building machine learning models. Currently, he focuses on content creation and writing technical blogs on data science and machine learning technologies. Abid has a Master's degree in technology Management and a Bachelor's degree in Telecommunications Engineering. His vision is to build an artificial intelligence product using a graph neural network for students struggling with mental illness.






{kind=link}