
Introducción
El panorama en constante evolución de la inteligencia artificial ha presentado una intersección de datos visuales y lingüísticos a través de grandes modelos de visión y lenguaje (LVLM). MoE-LLaVA es uno de estos modelos que está a la vanguardia de revolucionar la forma en que las máquinas interpretan y comprenden el mundo, reflejando la percepción humana. Sin embargo, el desafío sigue siendo encontrar el equilibrio entre el rendimiento del modelo y el cálculo para su implementación.
MoE-LLaVA, que es una novedosa combinación de expertos (MoE) para modelos de lenguaje-visión de gran tamaño (LVLM), es una solución innovadora que introduce un nuevo concepto en inteligencia artificial. Esto fue desarrollado en la Universidad de Pekín para abordar el complejo equilibrio entre el rendimiento del modelo y la computación. Se trata de un enfoque matizado de los modelos visual-lingüísticos a gran escala.
Objetivos de aprendizaje
- Comprender grandes modelos visión-lenguaje en el campo de la inteligencia artificial.
- Explore las características y capacidades únicas de MoE-LLaVA, una novedosa combinación de expertos para LVLM.
- Obtenga información sobre la estrategia de capacitación de ajuste del MoE, que aborda los desafíos relacionados con el aprendizaje multimodal y la escasez de modelos.
- Evaluar el desempeño de MoE-LLaVA en comparación con los LVLM existentes y sus posibles aplicaciones.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
¿Qué es MoE-LLaVA: el marco?
MoE-LLaVA, desarrollado en la Universidad de Pekín, presenta una innovadora combinación de expertos para modelos de visión y lenguaje de gran tamaño. El poder especial está en poder activar selectivamente sólo una fracción de sus parámetros durante el despliegue. Esta estrategia no sólo mantiene la eficiencia computacional sino que mejora las técnicas del modelo. Veamos mejor este modelo.
¿Qué son las métricas de rendimiento?
La destreza de MoE-LLaVA es evidente en su capacidad para lograr un buen rendimiento con un recuento escaso de parámetros. Con sólo 3 mil millones de parámetros escasamente activados, no solo iguala el rendimiento de modelos más grandes como LLaVA-1.5–7B, sino que también supera a LLaVA-1.5–13B en puntos de referencia de alucinación de objetos. Este avance es un nuevo punto de referencia para los LVLM dispersos. Esto muestra el potencial de eficiencia sin comprometer el rendimiento.
¿Qué es la estrategia de formación MoE-Tuning?
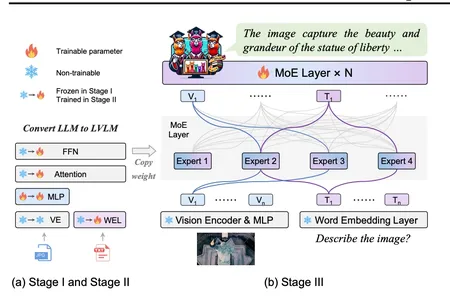
La estrategia de entrenamiento de ajuste de MoE es un elemento fundamental en el desarrollo de MoE-LLaVA, que es una solución para construir modelos dispersos con un recuento de parámetros manteniendo al mismo tiempo la eficiencia computacional. Esta estrategia se implementa en tres etapas cuidadosamente diseñadas, lo que permite que el modelo aborde de manera efectiva los desafíos relacionados con el aprendizaje multimodal y la escasez de modelos.
La primera etapa se encarga de la creación de una estructura dispersa seleccionando y ajustando componentes MoE que facilitan la captura de patrones e información. En las etapas posteriores, el modelo se refina para mejorar la especialización en modalidades específicas y optimizar el rendimiento general. El mayor éxito radica en su capacidad para lograr un equilibrio entre el recuento de parámetros y la eficiencia computacional, lo que la convierte en una solución confiable y eficiente para aplicaciones que requieren un rendimiento estable y sólido frente a datos diversos.
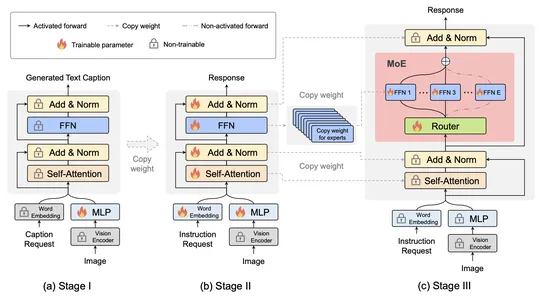
El enfoque único de MoE-LLaVA para la comprensión multimodal implica la activación solo de los mejores expertos a través de enrutadores durante la implementación. Esto no sólo reduce la carga computacional sino que muestra reducciones potenciales en las alucinaciones en los resultados del modelo, lo cual se refleja en la confiabilidad del modelo.
¿Qué es la comprensión multimodal?
MoE-LLaVA introduce una estrategia para la comprensión multimodal que se produce durante la implementación, donde solo los mejores expertos se activan a través de enrutadores. Este enfoque innovador no sólo da como resultado una reducción de la carga computacional sino que muestra el potencial de minimizar las alucinaciones. La cuidadosa selección de expertos contribuye a la confiabilidad del modelo al centrarse en las fuentes de información más relevantes y precisas.
Este enfoque coloca al MoE-LLaVA en una liga propia en comparación con los modelos tradicionales. La activación selectiva de los expertos top-k no sólo agiliza los procesos computacionales y mejora la eficiencia, sino que también aborda las alucinaciones. Este delicado equilibrio entre eficiencia computacional y precisión posiciona a MoE-LLaVA como una solución valiosa para aplicaciones del mundo real donde la confiabilidad y la información son primordiales.
¿Qué son la adaptabilidad y las aplicaciones?
La adaptabilidad amplía la aplicabilidad de MoE-LLaVA, haciéndolo adecuado para una gran variedad de tareas y aplicaciones. La habilidad del modelo en tareas más allá de la comprensión visual muestra su potencial para abordar desafíos en todos los dominios. Ya sea que se trate de tareas complejas de segmentación y detección o de generación de contenido a través de diversas modalidades, MoE-LLaVA demuestra su fortaleza. Esta adaptabilidad no solo subraya la eficacia del modelo, sino que también resalta su potencial para contribuir a campos donde prevalecen diversos tipos de datos y tareas.
¿Cómo aprovechar el poder del código de demostración?
Interfaz de usuario web con Gradio
Exploraremos las capacidades de MoE-LLaVA a través de una demostración web fácil de usar impulsada por Gradio. La demostración muestra todas las funciones compatibles con MoE-LLaVA, lo que permite a los usuarios experimentar el potencial del modelo de forma interactiva. Encuentra el cuaderno aquí o pegue el código siguiente en un editor; proporcionará una URL para interactuar con el modelo. Tenga en cuenta que puede consumir más de 10 GB de GPU y 5 GB de RAM.
Abra una nueva libreta de Google Colab:
Navegue a Google Colab y cree una nueva libreta haciendo clic en “Nueva libreta” o “Archivo” -> “Nueva libreta”. Ejecute la siguiente celda para instalar las dependencias. Copie y pegue el siguiente fragmento de código en una celda de código y ejecútelo.
%cd /content
!git clone -b dev https://github.com/camenduru/MoE-LLaVA-hf
%cd /content/MoE-LLaVA-hf
!pip install deepspeed==0.12.6 gradio==3.50.2 decord==0.6.0 transformers==4.37.0 einops timm tiktoken accelerate mpi4py
%cd /content/MoE-LLaVA-hf
!pip install -e .
%cd /content/MoE-LLaVA-hf
!python app.py
Pulsa los enlaces para interactuar con el modelo:
Para saber hasta qué punto este modelo puede adaptarse a su uso, vayamos más allá para verlo en otras formas usando Gradio. Puedes usar deepspeed con modelos como phi2. Veamos algunos comandos utilizables.
Inferencia CLI
Podría utilizar la línea de comando para ver el poder de MoE-LLaVA a través de la inferencia de la línea de comando. Realice tareas con facilidad utilizando los siguientes comandos.
# Run with phi2
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e" --image-file "image.jpg"
# Run with qwen
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e" --image-file "image.jpg"
# Run with stablelm
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e" --image-file "image.jpg"¿Cuáles son los requisitos y pasos de instalación?
De manera similar, puede usar el repositorio de PKU-YuanGroup, que es el repositorio oficial de MoE-LLaVA. Garantice una experiencia fluida con MoE-LLaVA siguiendo los requisitos recomendados y los pasos de instalación descritos en la documentación. Todos los enlaces están disponibles a continuación en la sección de referencias.
# Clone
git clone https://github.com/PKU-YuanGroup/MoE-LLaVA
# Move to the project directory
cd MoE-LLaVA
# Create and activate a virtual environment
conda create -n moellava python=3.10 -y
conda activate moellava
# Install packages
pip install --upgrade pip
pip install -e .
pip install -e ".(train)"
pip install flash-attn --no-build-isolationInferencia paso a paso con MoE-LLaVA
Los pasos anteriores que clonamos desde GitHub son más como ejecutar el paquete sin mirar el contenido. En el siguiente paso, seguiremos un paso más detallado para ver el modelo.
Paso 1: requisito de instalación
!pip install transformers
!pip install torchPaso 2: Descarga el Modelo MoE-LLaVA
Aquí se explica cómo obtener el enlace del modelo. Podría considerar la versión para Phi que tiene menos de 3 mil millones de parámetros del repositorio de Huggingface. https://huggingface.co/LanguageBind/MoE-LLaVA-Phi2-2.7B-4e Copie la URL del transformador haciendo clic en “Usar en transformadores” en la parte superior derecha de la interfaz del modelo. Se parece a esto:
# Load model directly
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("LanguageBind/MoE-LLaVA-Phi2-2.7B-4e", trust_remote_code=True)Usaremos esto correctamente a continuación para ejecutar la inferencia y usar la interfaz de usuario de gradio. Puede descargarlo localmente o utilizar el modelo de llamada como se ve arriba. Usaremos el cabezal GPT y los transformadores a continuación. Experimente con cualquier otro modelo disponible en el repositorio de LanguageBind MoE-LLaVA.
Paso 3: instale los paquetes necesarios
- Ejecute los siguientes comandos para instalar paquetes.
!pip install gradioPaso 4: ejecutar el código de inferencia
Ahora puede ejecutar el código de inferencia. Copie y pegue el siguiente código en una celda de código.
import torch
import gradio as gr
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load MoE-LLaVA Model
model_path = "path_to_your_model_directory_locally"
model = GPT2LMHeadModel.from_pretrained(model_path)
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
# Function to generate text
def generate_text(prompt):
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output_ids = model.generate(input_ids, max_length=100, num_beams=5, no_repeat_ngram_size=2, top_k=50, top_p=0.95, temperature=0.7)
generated_text = tokenizer.decode(output_ids(0), skip_special_tokens=True)
return generated_text
# Create Gradio Interface
iface = gr.Interface(fn=generate_text, inputs="text", outputs="text")
iface.launch()Esto proporcionará un cuadro de texto donde podrá escribir texto. Después de ingresar, el modelo generará texto basado en su entrada.
¡Eso es todo! Ha configurado con éxito MoE-LLaVA para inferencia en Google Colab. Siéntase libre de experimentar y explorar las capacidades del modelo.
Conclusión
MoE-LLaVA es una fuerza pionera en el ámbito de sistemas de aprendizaje multimodales eficientes, escalables y potentes. Su capacidad para ofrecer un buen rendimiento a modelos más grandes con menos parámetros significa un avance en los modelos de IA más prácticos. Al navegar por los intrincados paisajes de datos visuales y lingüísticos, MoE-LLaVA es una solución que equilibra hábilmente la eficiencia computacional con el rendimiento de última generación.
En conclusión, MoE-LLaVA no sólo refleja la evolución de grandes modelos de visión y lenguaje, sino que también establece nuevos puntos de referencia para abordar los desafíos asociados con la escasez de modelos. La sinergia entre su enfoque innovador y la formación de ajuste del MoE muestra su compromiso con la eficiencia y el rendimiento. A medida que crece la exploración del potencial de la IA en el aprendizaje multimodal, MoE-LLaVA es pionero en accesibilidad y capacidades de vanguardia.
Conclusiones clave
- MoE-LLaVA presenta una combinación de modelos expertos para visión y lenguaje amplios con rendimiento con menos parámetros.
- La estrategia de capacitación de ajuste del MoE aborda los desafíos asociados con el aprendizaje multimodal y la escasez de modelos, garantizando estabilidad y solidez.
- La activación selectiva de los expertos top-k durante el despliegue reduce la carga computacional y minimiza las alucinaciones.
- Con sólo 3 mil millones de parámetros escasamente activados, MoE-LLaVA establece una nueva base para sistemas de aprendizaje multimodal eficientes y potentes.
- La adaptabilidad del modelo a tareas, incluidas la segmentación, la detección y la generación, abre puertas a diversas aplicaciones más allá de la comprensión visual.
Preguntas frecuentes
A. MoE-LLaVA es una novedosa combinación de modelos expertos (MoE) para modelos de lenguaje-visión amplia (LVLM), desarrollada en la Universidad de Pekín. Contribuye a la IA al introducir un nuevo concepto, activando selectivamente solo una fracción de sus parámetros durante el despliegue, un equilibrio entre el rendimiento del modelo y la eficiencia computacional.
R. MoE-LLaVA se distingue por activar solo una fracción de sus parámetros durante la implementación, manteniendo la eficiencia computacional. Aborda el desafío introduciendo un enfoque matizado que funciona con menos parámetros en comparación con otros modelos como LLaVA-1.5–7B y LLaVA-1.5–13B.
R. MoE-LLaVA amplía su aplicabilidad, haciéndolo adecuado para diversas tareas y aplicaciones más allá de la comprensión visual. Su destreza en tareas como segmentación, detección y generación de contenido brinda una solución confiable y eficiente en todos los dominios.
R. La destreza de desempeño del MoE-LLaVA radica en lograr resultados con un escaso recuento de parámetros de 3 mil millones. Establece nuevos puntos de referencia para LVLM dispersos al superar a los modelos más grandes en puntos de referencia de alucinaciones de objetos con potencial de eficiencia sin comprometer el rendimiento.
R. MoE-LLaVA introduce una estrategia única durante la implementación, activando solo a los mejores expertos a través de enrutadores. Esta estrategia reduce la carga computacional, minimiza las alucinaciones en los resultados del modelo y se centra en las fuentes de información más relevantes y precisas.
Enlaces de referencia
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.






