
Aligning large language models (LLMs) with human preferences has become a crucial area of research. As these models gain complexity and capability, it is paramount to ensure that their actions and outcomes align with human values and intentions. The conventional route to this alignment has involved sophisticated reinforcement learning techniques, with Proximate Policy Optimization (PPO) leading the way. While effective, this method presents its own challenges, including high computational demands and the need for delicate hyperparameter tuning. These challenges beg the question: Is there a more efficient but equally effective way to achieve the same goal?
A research team from Cohere For ai and Cohere conducted an exploration to address this question, focusing on a less computationally intensive approach that does not compromise performance. They reviewed the fundamentals of reinforcement learning in the context of human feedback, specifically evaluating the efficiency of REINFORCE-style optimization variants versus traditional PPO and the recent “RL free”Methods such as DPO and RAFT. His research revealed that simpler methods could match or even outperform their more complex counterparts in aligning LLMs with human preferences.
The methodology employed analyzed the RL component of RLHF, removing the complexities associated with PPO to highlight the effectiveness of simpler and more direct approaches. Through their analysis, they identified that the basic principles driving PPO development, primarily its focus on minimizing variation and maximizing stability in updates, may not be as critical in the context of RLHF as previously thought.
Their empirical analysis, using Google Vizier datasets, demonstrated a notable improvement in performance when employing REINFORCE and its multi-sample extension, REINFORCE Leave-One-Out (RLOO), compared to traditional methods. His findings showed a more than 20% increase in performance, marking a major advance in the efficiency and effectiveness of aligning LLM with human preferences.
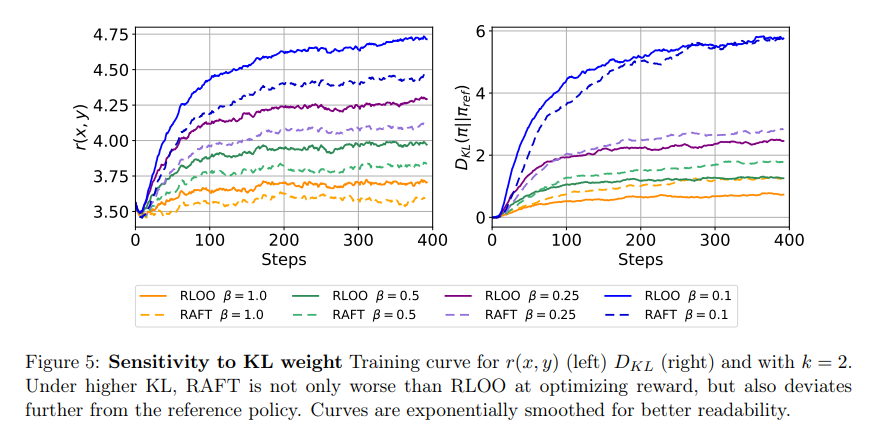
This research challenges prevailing norms regarding the need for complex reinforcement learning methods for LLM alignment and opens the door to more accessible and potentially more effective alternatives. Key insights from this study underscore the potential for simpler reinforcement learning variants to achieve high-quality LLM alignment at lower computational cost.
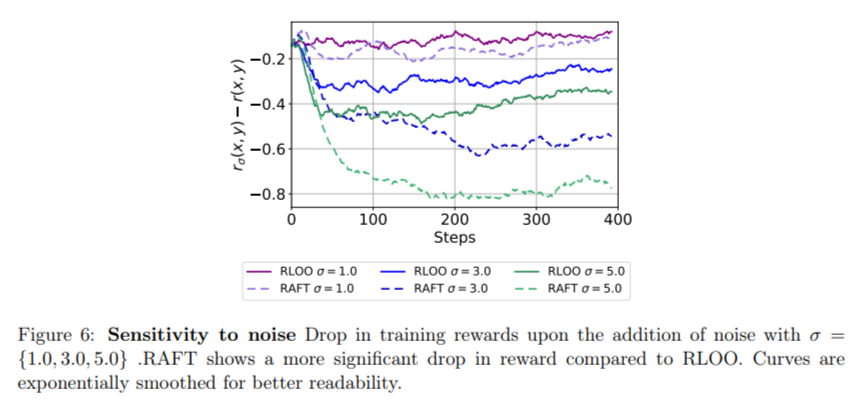
In conclusion, Cohere's research suggests some key insights, including:
- Simplifying the RL component of RLHF can lead to better alignment of LLMs with human preferences without sacrificing computational efficiency.
- Traditional and complex methods such as PPO may not be indispensable in RLHF settings, paving the way for simpler and more efficient alternatives.
- REINFORCE and its multi-sample extension, RLOO, emerge as promising candidates, offering a combination of performance and computational efficiency that challenges the status quo.
This work marks a fundamental shift in the approach to LLM alignment, suggesting that simplicity, rather than complexity, could be the key to more effective and efficient alignment of artificial intelligence with human values and preferences.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on Twitter and Google news. Join our 37k+ ML SubReddit, 41k+ Facebook community, Discord Channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our Telegram channel
![]()
Hello, my name is Adnan Hassan. I'm a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a double degree from the Indian Institute of technology, Kharagpur. I am passionate about technology and I want to create new products that make a difference.
<!– ai CONTENT END 2 –>






{kind=link}