 NEWSLETTER
NEWSLETTER
The usefulness of large language models (LLMs) has been increasingly recognized, demonstrating remarkable capabilities in processing and interpreting large data sets. These models have been instrumental in a variety of tasks, from facilitating clinical trial matching to enabling answers to sophisticated biomedical questions. A major challenge they face is the production of plausible but inaccurate answers, a phenomenon often attributed to the inability of models to directly query verified sources of information. This limitation underscores the pressing need for methods that can bridge the gap between LLMs and the precise, specialized knowledge contained in biomedical databases.
LLMs typically have to play catch-up in retrieving accurate information from specialized fields such as genomics. The crux of the issue lies in the inherent limitations of these models in navigating and utilizing domain-specific databases effectively. Recognizing this, researchers have been exploring innovative solutions that augment LLMs with the ability to directly access and interpret data from such specialized sources.
An innovative approach in this context is the development of GeneGPT, a methodology that significantly improves the ability of LLMs to access biomedical information. By integrating LLMs with the National Center for Biotechnology Information (NCBI) web APIs, GeneGPT allows these models to perform targeted searches and retrieve information directly from NCBI databases. This method represents a fundamental advance, allowing LLMs to avoid the limitations of traditional database queries and now access the most current and relevant biomedical data.
GeneGPT's methodology involves training LLMs to effectively generate and execute API calls to NCBI Web APIs. This is achieved through in-context learning and a specialized decoding algorithm to recognize and act on these API requests. This approach not only facilitates real-time data retrieval but also significantly reduces instances of inaccuracies in model results. Additionally, by allowing direct access to NCBI databases, GeneGPT ensures that the information retrieved is up-to-date and highly relevant to the user's query.
GeneGPT's performance demonstrates superior accuracy and efficiency in biomedical information retrieval, outperforming existing models and methodologies. In particular, GeneGPT excels at handling complex multi-hop questions that require sequential API calls, demonstrating its ability to navigate through a series of interconnected queries to arrive at a precise answer. This level of performance is underscored by a thorough analysis of the model components, which reveals the critical role that API demos and documentation play in enhancing the learning process.
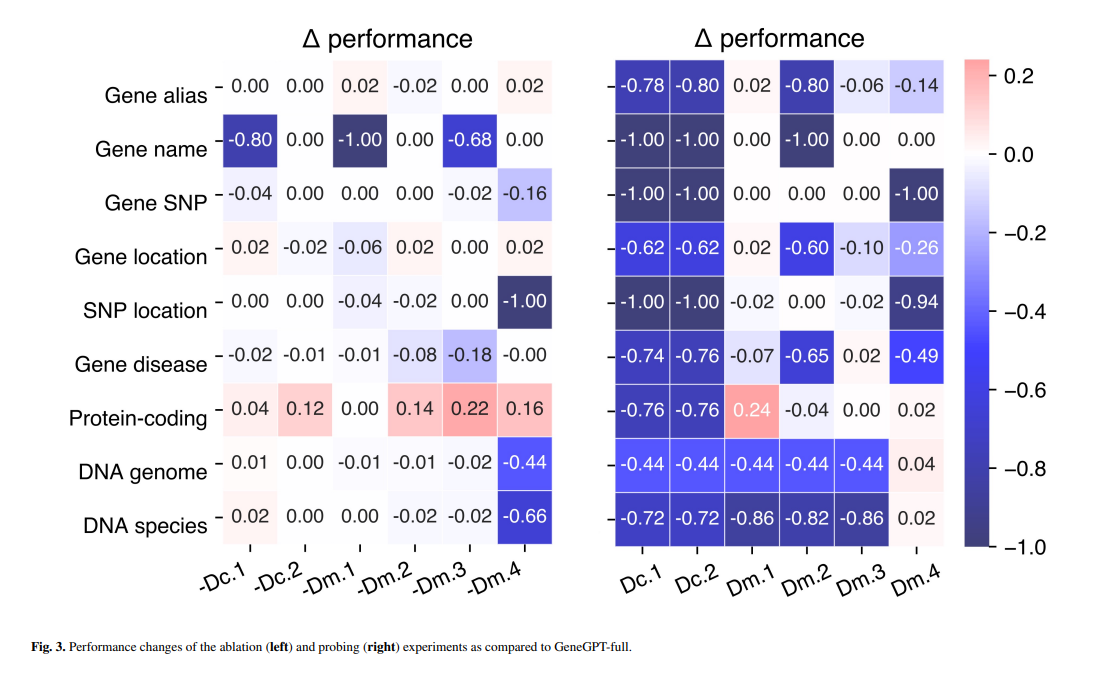
Beyond its immediate usefulness in the biomedical field, the success of GeneGPT heralds a new era for the application of LLM in various domains. By bridging the gap between LLMs and specialized databases, GeneGPT addresses the challenge of inaccurate information retrieval and opens up new possibilities for leveraging LLMs in tasks that require access to specific, verified knowledge. This advancement promises to expand the scope of LLM applications, making them more versatile and reliable tools for researchers and practitioners alike.
In conclusion, GeneGPT represents an important advance in the quest to improve the capabilities of LLMs in biomedical research. By allowing these models to access and use specialized knowledge from NCBI databases directly, GeneGPT addresses a critical challenge in information retrieval. Its success not only underscores the potential of integrating LLMs with domain-specific tools, but also paves the way for future innovations in the application of artificial intelligence in biomedical research and beyond. The development and implementation of GeneGPT marks a milestone in the journey towards more accurate, efficient and reliable information retrieval systems, showcasing the transformative potential of augmented LLMs for navigating the vast and complex landscape of biomedical knowledge.
Review the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on Twitter and Google news. Join our 37k+ ML SubReddit, 41k+ Facebook community, Discord Channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our Telegram channel
![]()
Sana Hassan, a consulting intern at Marktechpost and a dual degree student at IIT Madras, is passionate about applying technology and artificial intelligence to address real-world challenges. With a strong interest in solving practical problems, she brings a new perspective to the intersection of ai and real-life solutions.
<!– ai CONTENT END 2 –>






{kind=link}