
Today, we are pleased to announce that the basic Code Llama models, developed by Meta, are available for customers through Amazon SageMaker JumpStart to deploy with a single click to run inferences. Code Llama is a next-generation large language model (LLM) capable of generating code and natural language on top of code from code and natural language prompts. You can try this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to ML algorithms, models, and solutions to get you started quickly with ML. In this post, we explain how to discover and deploy the Code Llama model through SageMaker JumpStart.
Code Llama
Code Llama is a model launched by ai.meta.com/” target=”_blank” rel=”noopener”>Goal which is built on Llama 2. This next-generation model is designed to improve the productivity of developers' programming tasks by helping them create high-quality, well-documented code. The models excel in Python, C++, Java, PHP, C#, TypeScript, and Bash, and have the potential to save developers time and make software workflows more efficient.
It comes in three variants, designed to cover a wide variety of applications: the fundamental model (Code Llama), a specialized Python model (Code Llama Python), and an instruction-tracing model for understanding natural language instructions (Code Llama Instruct). . All Code Llama variants come in four sizes: 7B, 13B, 34B and 70B parameters. The 7B and 13B instruction and base variants support padding based on surrounding content, making them ideal for code assistant applications. The models were designed using Llama 2 as a base and then trained with 500 billion tokens of code data, with the specialized version of Python trained with 100 billion incremental tokens. Code Llama models provide stable generations with up to 100,000 context tokens. All models are trained on sequences of 16,000 tokens and show improvements on inputs with up to 100,000 tokens.
The model is available under the same Community license as Llama 2.
Foundation models in SageMaker
SageMaker JumpStart provides access to a variety of models from popular model hubs, including Hugging Face, PyTorch Hub, and TensorFlow Hub, which you can use within your machine learning development workflow in SageMaker. Recent advances in ML have given rise to a new class of models known as foundation models, which are typically trained on billions of parameters and tailored to a broad category of use cases, such as text summarization, digital art generation, and language translation. Because these models are expensive to train, customers prefer to use basic pre-trained models and tune them as needed, rather than training these models themselves. SageMaker provides a curated list of models that you can choose from in the SageMaker console.
You can find basic models from different model providers within SageMaker JumpStart, allowing you to get up and running with basic models quickly. You can find basic models based on different tasks or model providers, and easily review model features and terms of use. You can also test these models using a test UI widget. When you want to use a basic scale model, you can do so without leaving SageMaker by using pre-designed notebooks from model vendors. Because the models are hosted and deployed on AWS, you can rest assured that your data, whether used to evaluate or use the model at scale, is never shared with third parties.
Discover the Code Llama model in SageMaker JumpStart
To deploy the Code Llama 70B model, complete the following steps in Amazon SageMaker Studio:
- On the SageMaker Studio home page, choose Good start in the navigation panel.
- Search for Code Llama models and choose the Code Llama 70B model from the list of models shown.
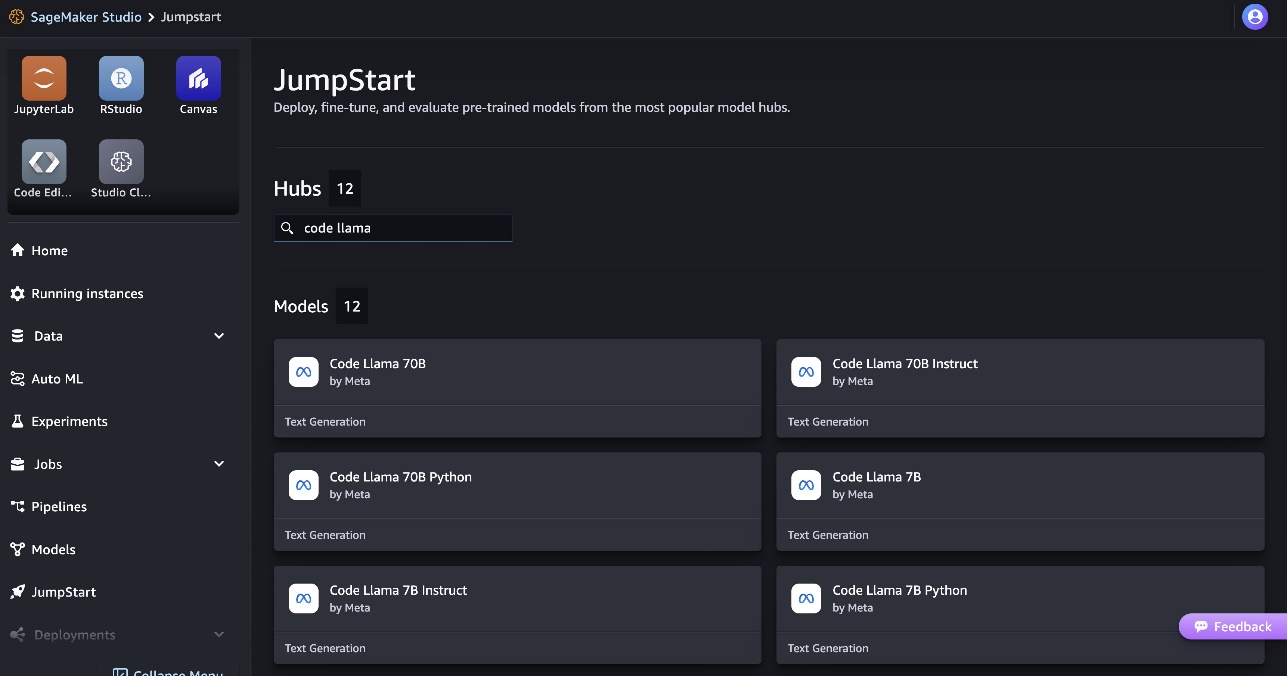
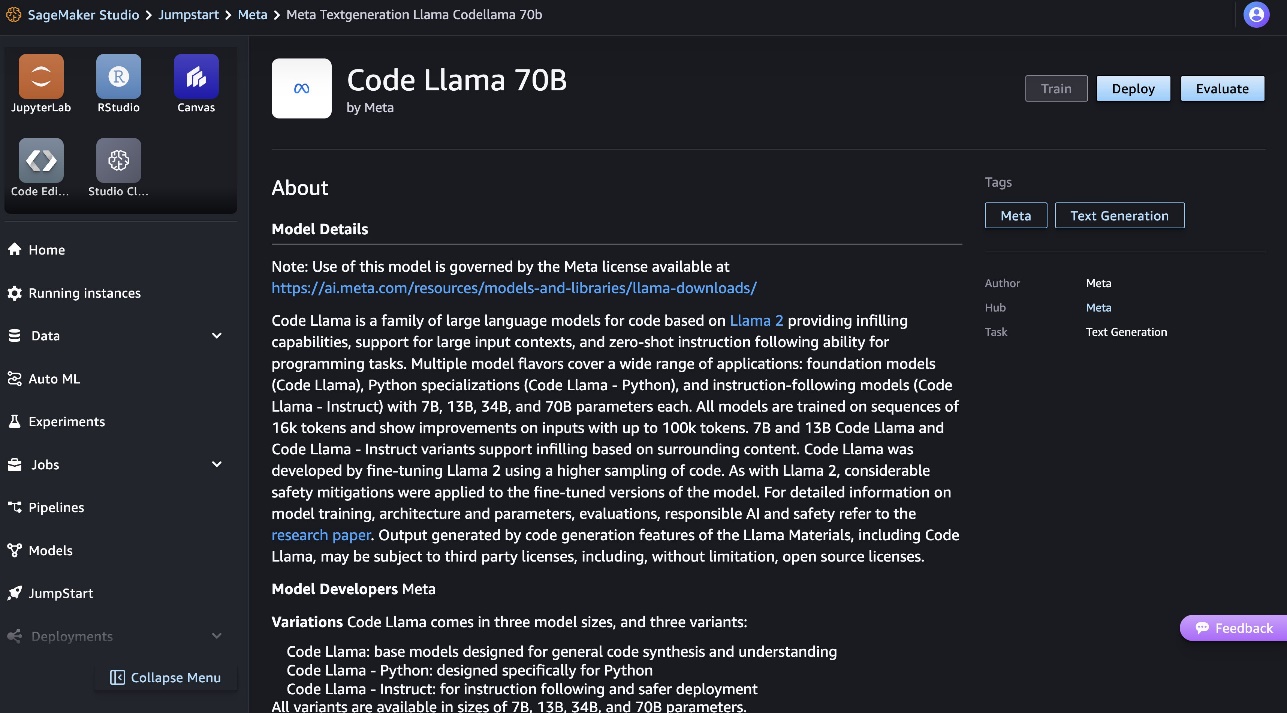
You can find more information about the model in the Code Llama 70B model sheet.
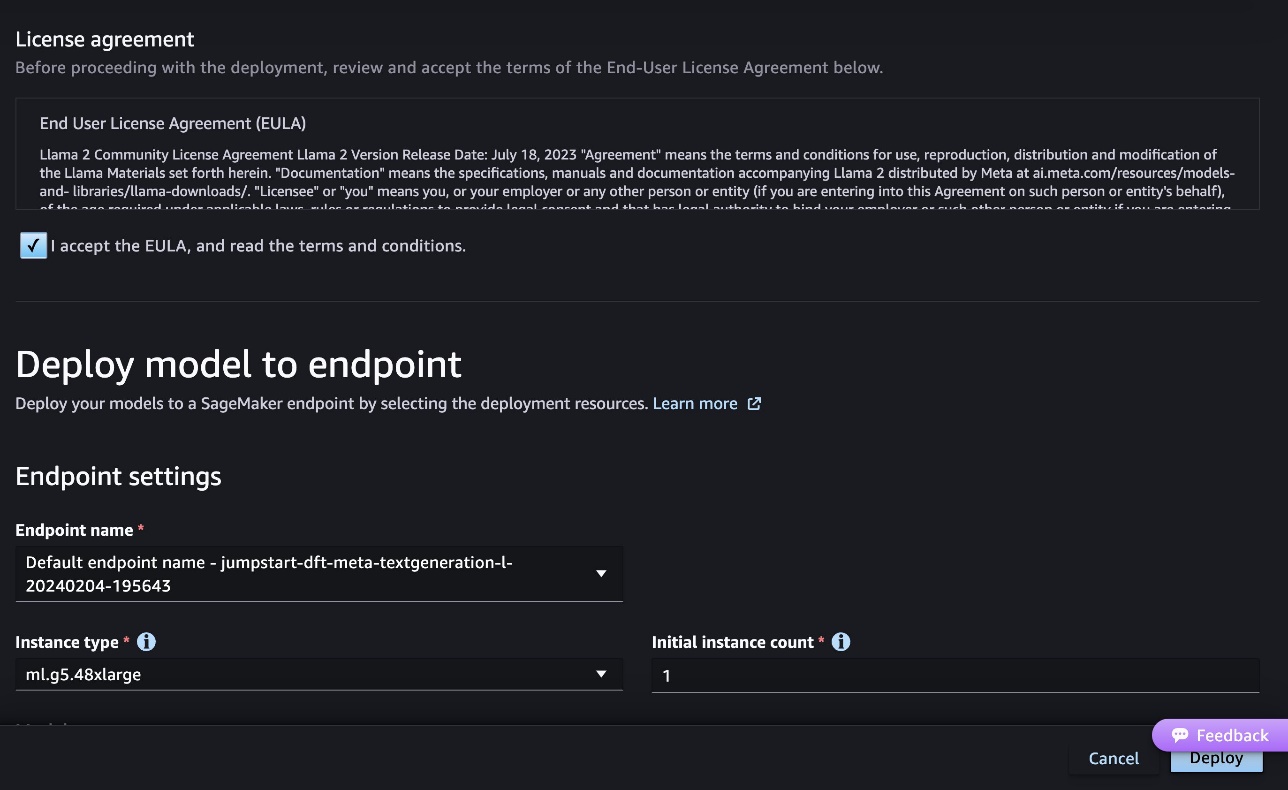
The following screenshot shows the endpoint configuration. You can change the options or use the default ones.
- Accept the End User License Agreement (EULA) and choose Deploy.
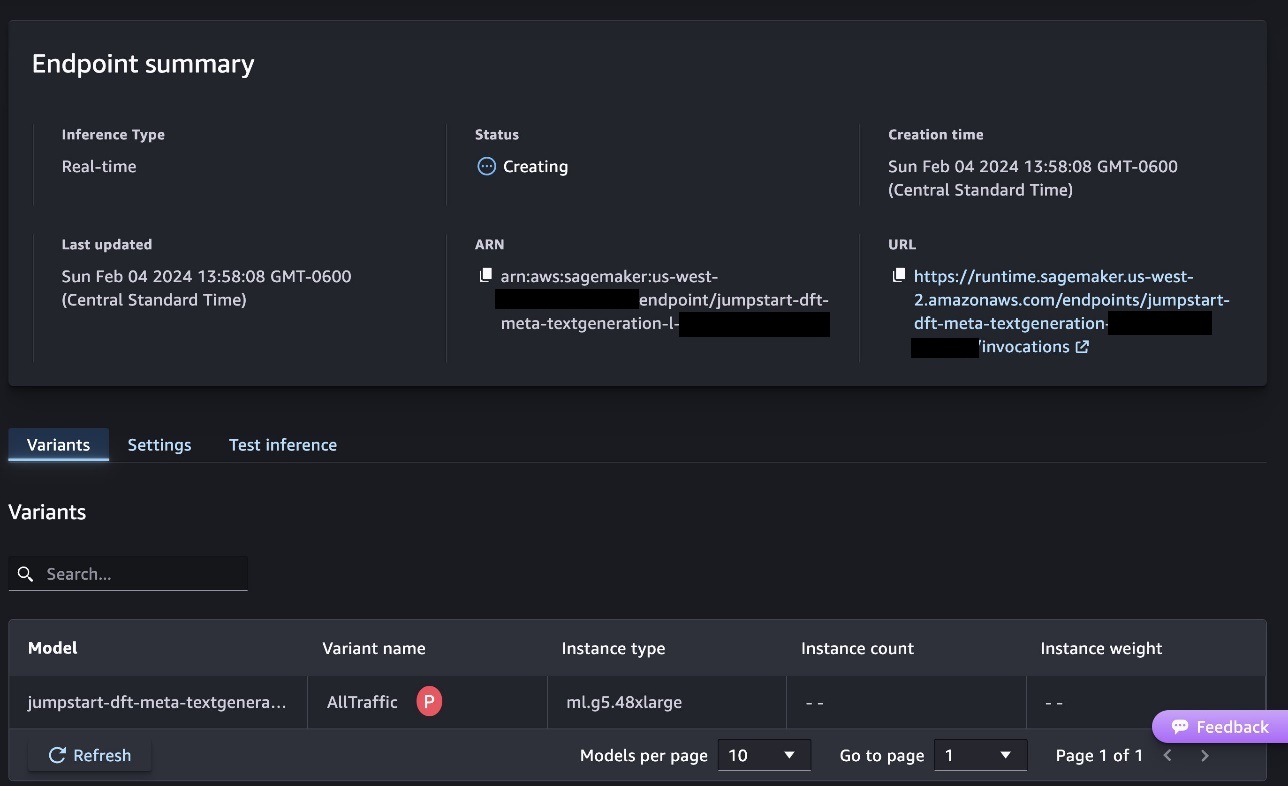
This will start the endpoint deployment process, as shown in the screenshot below.
Deploy the model with SageMaker Python SDK
Alternatively, you can implement via the example notebook by choosing open notebook within the Classic Studio model details page. The example notebook provides comprehensive guidance on how to implement the model for inference and resource cleansing.
To deploy using the laptop, we start by selecting an appropriate model, specified by the model_id. You can deploy any of the selected models in SageMaker with the following code:
This deploys the model to SageMaker with default configurations, including the default instance type and default VPC configurations. You can change these settings by specifying non-default values in JumpStartModel. Please note that by default, accept_eula is set to False. You need to configure accept_eula=True to implement the endpoint successfully. By doing so, you agree to the user license agreement and acceptable use policy as mentioned above. You also can ai.meta.com/resources/models-and-libraries/llama-downloads/” target=”_blank” rel=”noopener”>discharge the license agreement.
Invoke a SageMaker endpoint
Once the endpoint is deployed, you can perform inference using Boto3 or the SageMaker Python SDK. In the following code, we use the SageMaker Python SDK to call the model to perform inference and print the response:
The function print_response takes a payload consisting of the payload and the model response and prints the output. Code Llama supports many parameters while performing inference:
- maximum length – The model generates text until the output length (which includes the length of the input context) reaches
max_length. If specified, it must be a positive integer. - max_new_tokens – The model generates text until the output length (excluding the input context length) reaches
max_new_tokens. If specified, it must be a positive integer. - num_beams – This specifies the number of beams used in the greedy search. If specified, it must be an integer greater than or equal to
num_return_sequences. - no_repeat_ngram_size – The model ensures that a sequence of words
no_repeat_ngram_sizeit is not repeated in the output sequence. If specified, it must be a positive integer greater than 1. - temperature – This controls the randomness in the output. Higher
temperatureresults in an output sequence with low probability words and lowertemperatureresults in an output sequence with high probability words. Yeahtemperatureis 0, results in greedy decoding. If specified, it must be a positive float value. - early_stop – Yeah
True, text generation ends when all bundle hypotheses reach the end of the sentence token. If specified, it must be boolean. - make_sample – Yeah
True, the model displays the next word based on probability. If specified, it must be boolean. - top_k – At each step of text generation, the model samples only the
top_kmost likely words. If specified, it must be a positive integer. - up_p – At each step of text generation, the model samples the smallest possible set of words with cumulative probability.
top_p. If specified, it must be a float value between 0 and 1. - return_full_text – Yeah
True, the input text will be part of the generated output text. If specified, it must be boolean. The default value for this isFalse. - arrest – If specified, must be a list of strings. Text generation stops if any of the specified strings are generated.
You can specify any subset of these parameters when invoking an endpoint. Below is an example of how to invoke an endpoint with these arguments.
Code Completion
The following examples demonstrate how to perform code completion where the expected response from the endpoint is the natural continuation of the message.
First we execute the following code:
We obtain the following result:
For our next example, we run the following code:
We obtain the following result:
GENERATION CODE
The following examples show Python code generation using Code Llama.
First we execute the following code:
We obtain the following result:
For our next example, we run the following code:
We obtain the following result:
These are some of the examples of code-related tasks using Code Llama 70B. You can use the model to generate even more complicated code. We encourage you to try it out using your own use cases and code-related examples!
Clean
After you have tested the endpoints, be sure to remove the inference endpoints from SageMaker and the model to avoid incurring charges. Use the following code:
Conclusion
In this post, we introduce Code Llama 70B in SageMaker JumpStart. Code Llama 70B is a next-generation model for generating code from natural language prompts and code. You can deploy the model with a few simple steps in SageMaker JumpStart and then use it to perform code-related tasks, such as code generation and code filling. As a next step, try using the model with your own use cases and code-related data.
About the authors
 Dr. Kyle Ulrich is an applied scientist on the Amazon SageMaker JumpStart team. His research interests include scalable machine learning algorithms, computer vision, time series, non-parametric Bayesian processes, and Gaussian processes. His PhD is from Duke University and he has published articles in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an applied scientist on the Amazon SageMaker JumpStart team. His research interests include scalable machine learning algorithms, computer vision, time series, non-parametric Bayesian processes, and Gaussian processes. His PhD is from Duke University and he has published articles in NeurIPS, Cell, and Neuron.
 Dr AS Farooq Sabir is a Senior Solutions Architect specializing in artificial intelligence and machine learning at AWS. He holds a PhD and a master's degree in Electrical Engineering from the University of Texas at Austin and a master's degree in Computer Science from the Georgia Institute of technology. He has over 15 years of work experience and also enjoys teaching and mentoring college students. At AWS, he helps clients formulate and solve their business problems in data science, machine learning, computer vision, artificial intelligence, numerical optimization, and related domains. Based in Dallas, Texas, he and his family love to travel and take long road trips.
Dr AS Farooq Sabir is a Senior Solutions Architect specializing in artificial intelligence and machine learning at AWS. He holds a PhD and a master's degree in Electrical Engineering from the University of Texas at Austin and a master's degree in Computer Science from the Georgia Institute of technology. He has over 15 years of work experience and also enjoys teaching and mentoring college students. At AWS, he helps clients formulate and solve their business problems in data science, machine learning, computer vision, artificial intelligence, numerical optimization, and related domains. Based in Dallas, Texas, he and his family love to travel and take long road trips.
 June won is a product manager for SageMaker JumpStart. He focuses on making basic models easily discoverable and usable to help clients build generative ai applications. His Amazon experience also includes mobile shopping app and last-mile delivery.
June won is a product manager for SageMaker JumpStart. He focuses on making basic models easily discoverable and usable to help clients build generative ai applications. His Amazon experience also includes mobile shopping app and last-mile delivery.






{kind=link}