
With the advent of generative ai, today’s foundation models (FMs), such as the large language models (LLMs) Claude 2 and Llama 2, can perform a range of generative tasks such as question answering, summarization, and content creation on text data. However, real-world data exists in multiple modalities, such as text, images, video, and audio. Take a PowerPoint slide deck, for example. It could contain information in the form of text, or embedded in graphs, tables, and pictures.
In this post, we present a solution that uses multimodal FMs such as the Amazon Titan Multimodal Embeddings model and LLaVA 1.5 and AWS services including Amazon Bedrock and Amazon SageMaker to perform similar generative tasks on multimodal data.
Solution overview
The solution provides an implementation for answering questions using information contained in the text and visual elements of a slide deck. The design relies on the concept of Retrieval Augmented Generation (RAG). Traditionally, RAG has been associated with textual data that can be processed by LLMs. In this post, we extend RAG to include images as well. This provides a powerful search capability to extract contextually relevant content from visual elements like tables and graphs along with text.
There are different ways to design a RAG solution that includes images. We have presented one approach here and will follow up with an alternate approach in the second post of this three-part series.
This solution includes the following components:
- Amazon Titan Multimodal Embeddings model – This FM is used to generate embeddings for the content in the slide deck used in this post. As a multimodal model, this Titan model can process text, images, or a combination as input and generate embeddings. The Titan Multimodal Embeddings model generates vectors (embeddings) of 1,024 dimensions and is accessed via Amazon Bedrock.
- Large Language and Vision Assistant (LLaVA) – LLaVA is an open source multimodal model for visual and language understanding and is used to interpret the data in the slides, including visual elements such as graphs and tables. We use the 7-billion parameter version LLaVA 1.5-7b in this solution.
- Amazon SageMaker – The LLaVA model is deployed on a SageMaker endpoint using SageMaker hosting services, and we use the resulting endpoint to run inferences against the LLaVA model. We also use SageMaker notebooks to orchestrate and demonstrate this solution end to end.
- Amazon OpenSearch Serverless – OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service. We use OpenSearch Serverless as a vector database for storing embeddings generated by the Titan Multimodal Embeddings model. An index created in the OpenSearch Serverless collection serves as the vector store for our RAG solution.
- Amazon OpenSearch Ingestion (OSI) – OSI is a fully managed, serverless data collector that delivers data to OpenSearch Service domains and OpenSearch Serverless collections. In this post, we use an OSI pipeline to deliver data to the OpenSearch Serverless vector store.
Solution architecture
The solution design consists of two parts: ingestion and user interaction. During ingestion, we process the input slide deck by converting each slide into an image, generate embeddings for these images, and then populate the vector data store. These steps are completed prior to the user interaction steps.
In the user interaction phase, a question from the user is converted into embeddings and a similarity search is run on the vector database to find a slide that could potentially contain answers to user question. We then provide this slide (in the form of an image file) to the LLaVA model and the user question as a prompt to generate an answer to the query. All the code for this post is available in the GitHub repo.
The following diagram illustrates the ingestion architecture.
The workflow steps are as follows:
- Slides are converted to image files (one per slide) in JPG format and passed to the Titan Multimodal Embeddings model to generate embeddings. In this post, we use the slide deck titled Train and deploy Stable Diffusion using AWS Trainium & AWS Inferentia from the AWS Summit in Toronto, June 2023, to demonstrate the solution. The sample deck has 31 slides, so we generate 31 sets of vector embeddings, each with 1,024 dimensions. We add additional metadata fields to these generated vector embeddings and create a JSON file. These additional metadata fields can be used to perform rich search queries using OpenSearch’s powerful search capabilities.
- The generated embeddings are put together in a single JSON file that is uploaded to Amazon Simple Storage Service (Amazon S3).
- Via Amazon S3 Event Notifications, an event is put in an Amazon Simple Queue Service (Amazon SQS) queue.
- This event in the SQS queue acts as a trigger to run the OSI pipeline, which in turn ingests the data (JSON file) as documents into the OpenSearch Serverless index. Note that the OpenSearch Serverless index is configured as the sink for this pipeline and is created as part of the OpenSearch Serverless collection.
The following diagram illustrates the user interaction architecture.
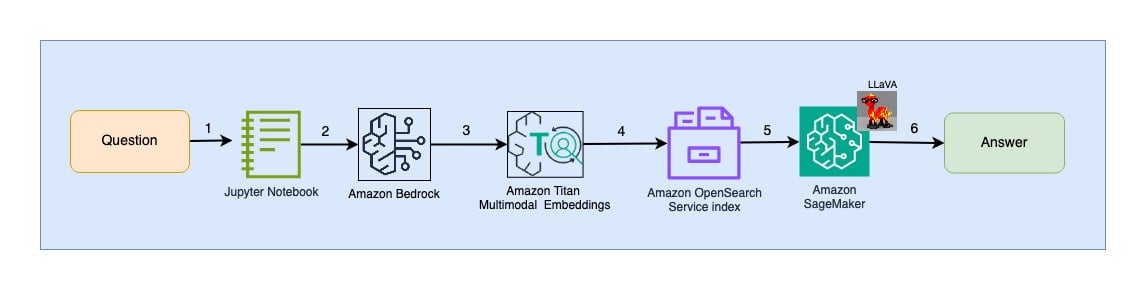
The workflow steps are as follows:
- A user submits a question related to the slide deck that has been ingested.
- The user input is converted into embeddings using the Titan Multimodal Embeddings model accessed via Amazon Bedrock. An OpenSearch vector search is performed using these embeddings. We perform a k-nearest neighbor (k=1) search to retrieve the most relevant embedding matching the user query. Setting k=1 retrieves the most relevant slide to the user question.
- The metadata of the response from OpenSearch Serverless contains a path to the image corresponding to the most relevant slide.
- A prompt is created by combining the user question and the image path and provided to LLaVA hosted on SageMaker. The LLaVA model is able to understand the user question and answer it by examining the data in the image.
- The result of this inference is returned to the user.
These steps are discussed in detail in the following sections. See the Results section for screenshots and details on the output.
Prerequisites
To implement the solution provided in this post, you should have an AWS account and familiarity with FMs, Amazon Bedrock, SageMaker, and OpenSearch Service.
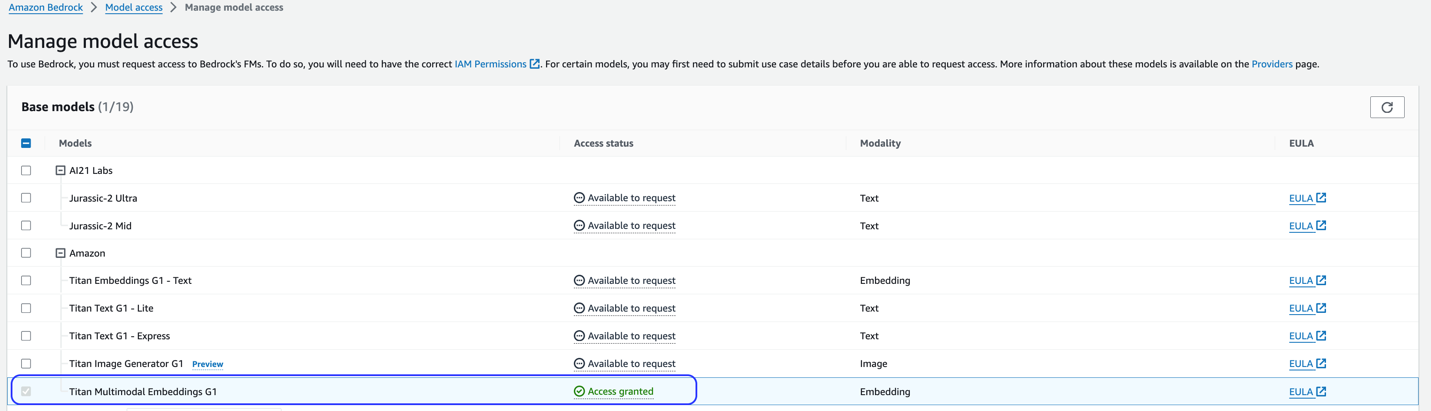
This solution uses the Titan Multimodal Embeddings model. Ensure that this model is enabled for use in Amazon Bedrock. On the Amazon Bedrock console, choose Model access in the navigation pane. If Titan Multimodal Embeddings is enabled, the access status will state Access granted.
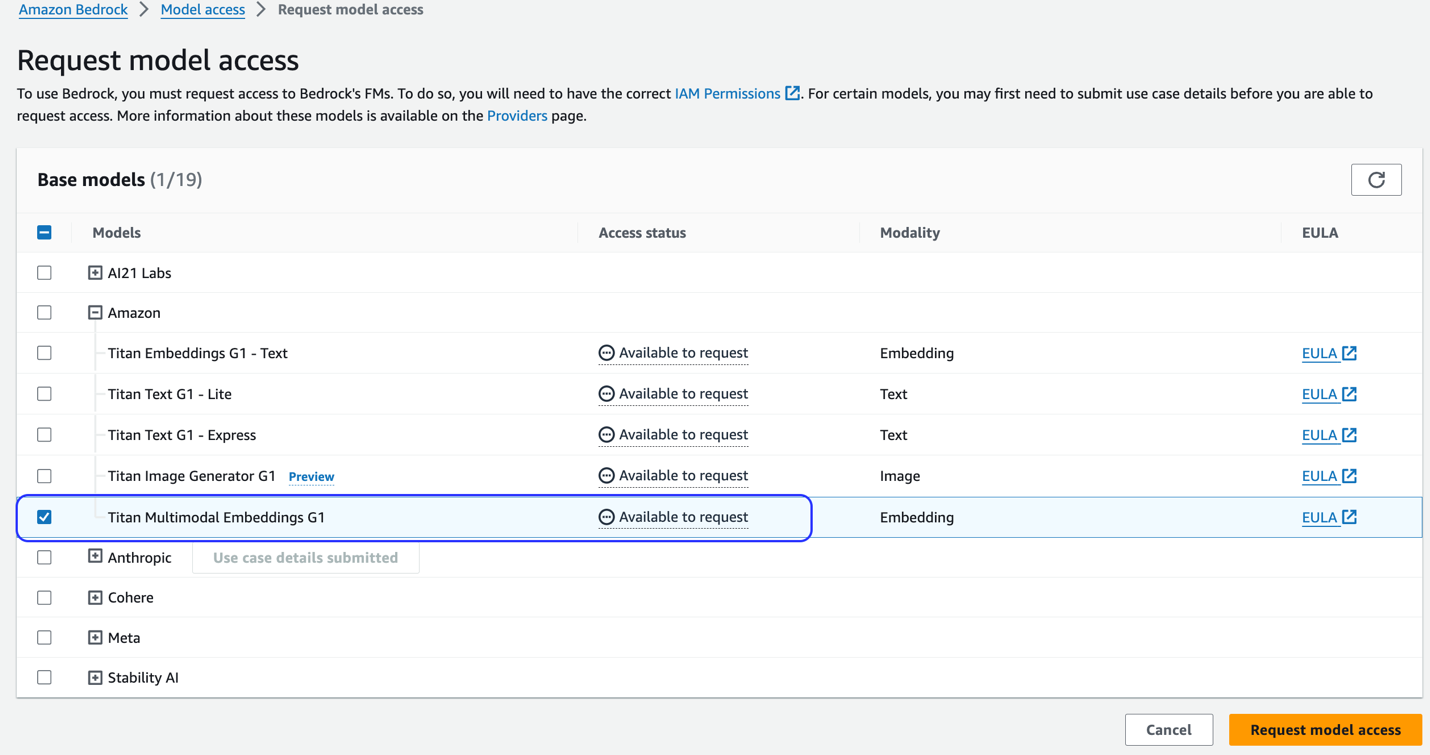
If the model is not available, enable access to the model by choosing Manage Model Access, selecting Titan Multimodal Embeddings G1, and choosing Request model access. The model is enabled for use immediately.
Use an AWS CloudFormation template to create the solution stack
Use one of the following AWS CloudFormation templates (depending on your Region) to launch the solution resources.
| AWS Region | Link |
|---|---|
us-east-1 |
 |
us-west-2 |
|
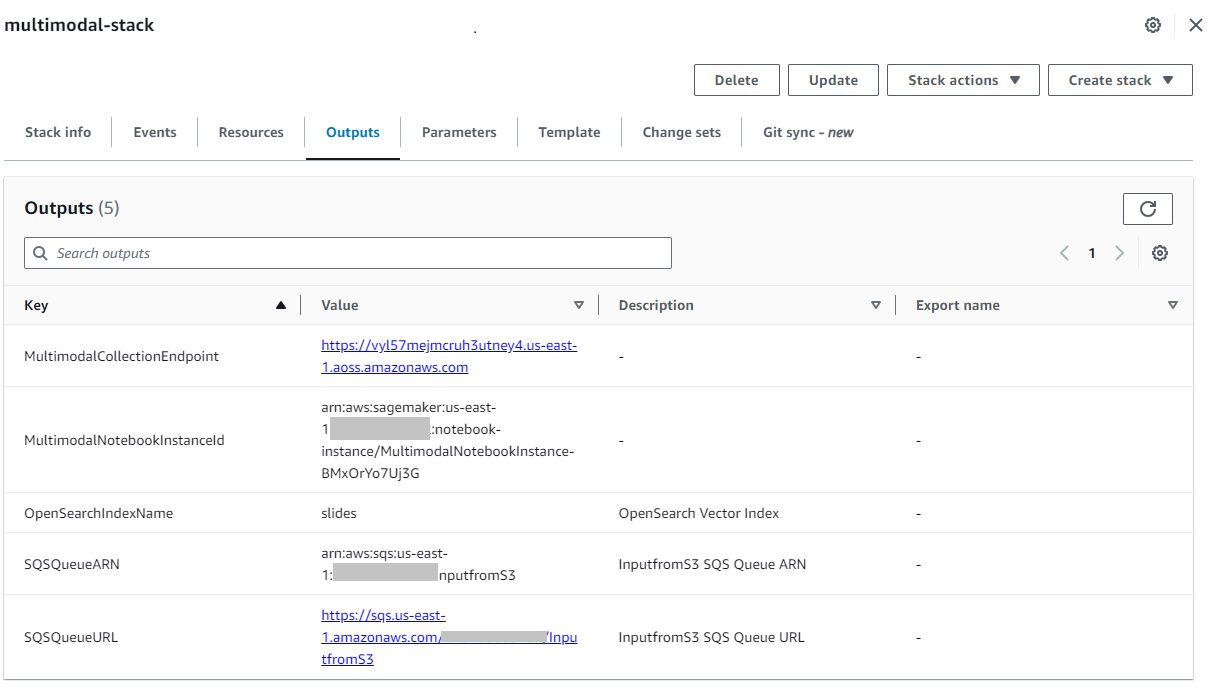
After the stack is created successfully, navigate to the stack’s Outputs tab on the AWS CloudFormation console and note the value for MultimodalCollectionEndpoint, which we use in subsequent steps.
The CloudFormation template creates the following resources:
- IAM roles – The following AWS Identity and Access Management (IAM) roles are created. Update these roles to apply least-privilege permissions.
SMExecutionRolewith Amazon S3, SageMaker, OpenSearch Service, and Bedrock full access.OSPipelineExecutionRolewith access to specific Amazon SQS and OSI actions.
- SageMaker notebook – All the code for this post is run via this notebook.
- OpenSearch Serverless collection – This is the vector database for storing and retrieving embeddings.
- OSI pipeline – This is the pipeline for ingesting data into OpenSearch Serverless.
- S3 bucket – All data for this post is stored in this bucket.
- SQS queue – The events for triggering the OSI pipeline run are put in this queue.
The CloudFormation template configures the OSI pipeline with Amazon S3 and Amazon SQS processing as source and an OpenSearch Serverless index as sink. Any objects created in the specified S3 bucket and prefix (multimodal/osi-embeddings-json) will trigger SQS notifications, which are used by the OSI pipeline to ingest data into OpenSearch Serverless.
The CloudFormation template also creates network, encryption, and data access policies required for the OpenSearch Serverless collection. Update these policies to apply least-privilege permissions.
Note that the CloudFormation template name is referenced in SageMaker notebooks. If the default template name is changed, make sure you update the same in globals.py
Test the solution
After the prerequisite steps are complete and the CloudFormation stack has been created successfully, you’re now ready to test the solution:
- On the SageMaker console, choose Notebooks in the navigation pane.
- Select the
MultimodalNotebookInstancenotebook instance and choose Open JupyterLab.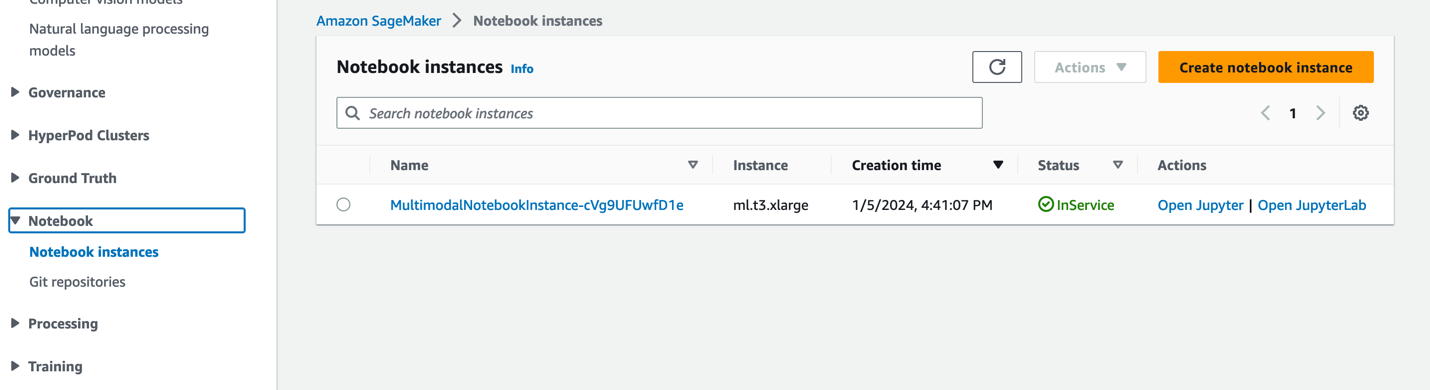
- In File Browser, traverse to the notebooks folder to see the notebooks and supporting files.
The notebooks are numbered in the sequence in which they’re run. Instructions and comments in each notebook describe the actions performed by that notebook. We run these notebooks one by one.
- Choose 0_deploy_llava.ipynb to open it in JupyterLab.
- On the Run menu, choose Run All Cells to run the code in this notebook.
This notebook deploys the LLaVA-v1.5-7B model to a SageMaker endpoint. In this notebook, we download the LLaVA-v1.5-7B model from HuggingFace Hub, replace the inference.py script with llava_inference.py, and create a model.tar.gz file for this model. The model.tar.gz file is uploaded to Amazon S3 and used for deploying the model on SageMaker endpoint. The llava_inference.py script has additional code to allow reading an image file from Amazon S3 and running inference on it.
- Choose 1_data_prep.ipynb to open it in JupyterLab.
- On the Run menu, choose Run All Cells to run the code in this notebook.
This notebook downloads the slide deck, converts each slide into JPG file format, and uploads these to the S3 bucket used for this post.
- Choose 2_data_ingestion.ipynb to open it in JupyterLab.
- On the Run menu, choose Run All Cells to run the code in this notebook.
We do the following in this notebook:
- We create an index in the OpenSearch Serverless collection. This index stores the embeddings data for the slide deck. See the following code:
- We use Titan Multimodal Embeddings model to convert the JPG images created in the previous notebook into vector embeddings. These embeddings and additional metadata (such as the S3 path of the image file) are stored in a JSON file and uploaded to Amazon S3. Note that a single JSON file is created, which contains documents for all the slides (images) converted into embeddings. The following code snippet shows how an image (in the form of a Base64 encoded string) is converted into embeddings:
- This action triggers the OpenSearch Ingestion pipeline, which processes the file and ingests it into the OpenSearch Serverless index. The following is a sample of the JSON file created. (A vector with four dimensions is shown in the example code. The Titan Multimodal Embeddings model generates 1,024 dimensions.)
- Choose 3_rag_inference.ipynb to open it in JupyterLab.
- On the Run menu, choose Run All Cells to run the code in this notebook.
This notebook implements the RAG solution: we convert the user question into embeddings, find a similar image (slide) from the vector database, and provide the retrieved image to LLaVA to generate an answer to the user question. We use the following prompt template:
The following code snippet provides the RAG workflow:
Results
The following is a compilation of some user questions and responses generated by our implementation. The Question column captures the user question, and the Answer column is the textual response generated by LLaVA. Image is the k-nearest (k=1) slide match returned by the OpenSearch Serverless vector search. This slide is interpreted by LLaVA to provide the answer.
Multimodal RAG results
| Question | Answer | Image |
|---|---|---|
| How does Inf2 compare in performance to comparable EC2 instances? I need numbers. | According to the slide deck, Inf2 instances by AWS Inferentia2 offer up to 4x higher throughput and 10x lower latency compared to comparable EC2 instances. |  |
| As per the ai/ML flywheel, what do the AWS ai/ML services provide? | The AWS ai/ML services provide better $/perfer capabilities, new capabilities, and investment in innovation. | 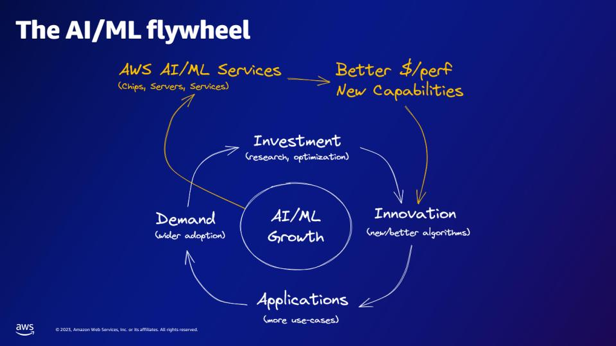 |
| Compared to GPT-2, how many more parameters does GPT-3 have? What is the numerical difference between the parameter size of GPT-2 and GPT-3? | According to the slide, GPT-3 has 175 billion parameters, while GPT-2 has 1.5 billion parameters. The numerical difference between the parameter size of GPT-2 and GPT-3 is 173.5 billion. | 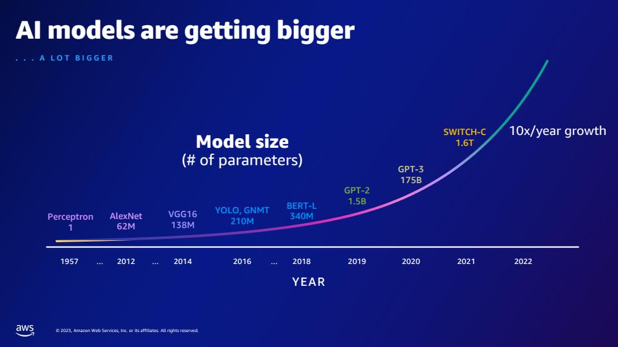 |
| What are quarks in particle physics? | I did not find the answer to this question in the slide deck. |  |
Feel free to extend this solution to your slide decks. Simply update the SLIDE_DECK variable in globals.py with a URL to your slide deck and run the ingestion steps detailed in the previous section.
Tip
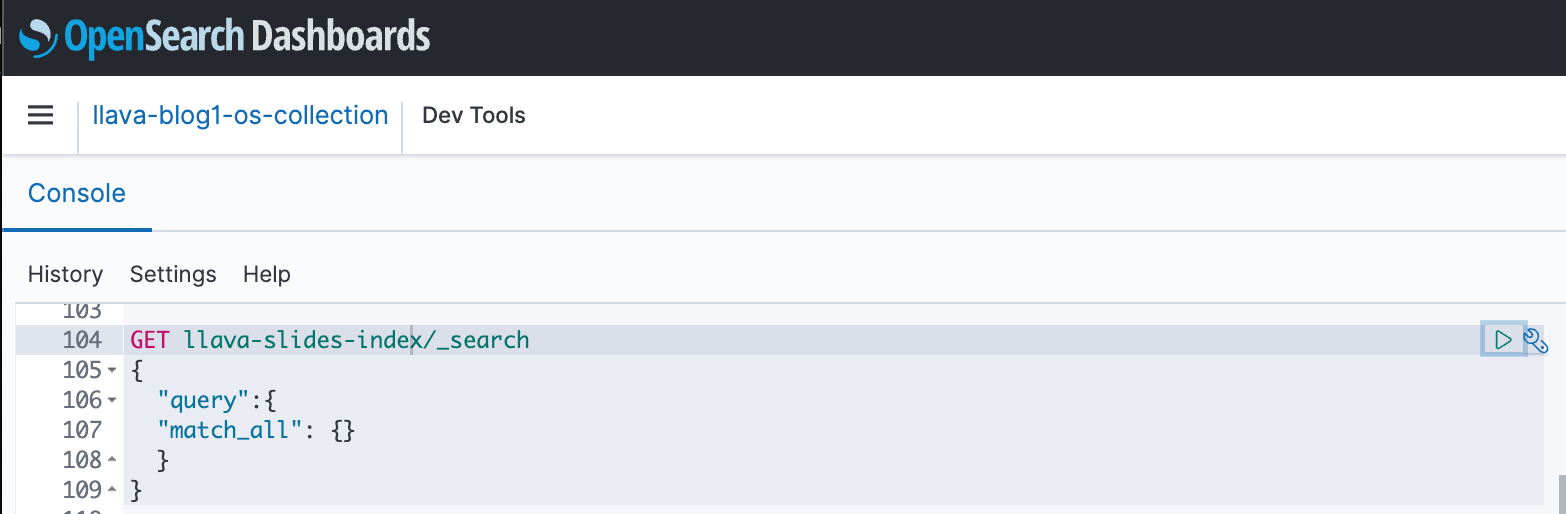
You can use OpenSearch Dashboards to interact with the OpenSearch API to run quick tests on your index and ingested data. The following screenshot shows an OpenSearch dashboard GET example.
Clean up
To avoid incurring future charges, delete the resources you created. You can do this by deleting the stack via the CloudFormation console.

Additionally, delete the SageMaker inference endpoint created for LLaVA inferencing. You can do this by uncommenting the cleanup step in 3_rag_inference.ipynb and running the cell, or by deleting the endpoint via the SageMaker console: choose Inference and Endpoints in the navigation pane, then select the endpoint and delete it.
Conclusion
Enterprises generate new content all the time, and slide decks are a common mechanism used to share and disseminate information internally with the organization and externally with customers or at conferences. Over time, rich information can remain buried and hidden in non-text modalities like graphs and tables in these slide decks. You can use this solution and the power of multimodal FMs such as the Titan Multimodal Embeddings model and LLaVA to discover new information or uncover new perspectives on content in slide decks.
We encourage you to learn more by exploring Amazon SageMaker JumpStart, Amazon Titan models, Amazon Bedrock, and OpenSearch Service, and building a solution using the sample implementation provided in this post.
Look out for two additional posts as part of this series. Part 2 covers another approach you could take to talk to your slide deck. This approach generates and stores LLaVA inferences and uses those stored inferences to respond to user queries. Part 3 compares the two approaches.
About the authors
 Amit Arora is an ai and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
Amit Arora is an ai and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
 Manju Prasad is a Senior Solutions Architect within Strategic Accounts at Amazon Web Services. She focuses on providing technical guidance in a variety of domains, including ai/ML to a marquee M&E customer. Prior to joining AWS, she designed and built solutions for companies in the financial services sector and also for a startup.
Manju Prasad is a Senior Solutions Architect within Strategic Accounts at Amazon Web Services. She focuses on providing technical guidance in a variety of domains, including ai/ML to a marquee M&E customer. Prior to joining AWS, she designed and built solutions for companies in the financial services sector and also for a startup.
 Archana Inapudi is a Senior Solutions Architect at AWS supporting strategic customers. She has over a decade of experience helping customers design and build data analytics and database solutions. She is passionate about using technology to provide value to customers and achieve business outcomes.
Archana Inapudi is a Senior Solutions Architect at AWS supporting strategic customers. She has over a decade of experience helping customers design and build data analytics and database solutions. She is passionate about using technology to provide value to customers and achieve business outcomes.
 Antara Raisa is an ai and ML Solutions Architect at Amazon Web Services supporting strategic customers based out of Dallas, Texas. She also has previous experience working with large enterprise partners at AWS, where she worked as a Partner Success Solutions Architect for digital native customers.
Antara Raisa is an ai and ML Solutions Architect at Amazon Web Services supporting strategic customers based out of Dallas, Texas. She also has previous experience working with large enterprise partners at AWS, where she worked as a Partner Success Solutions Architect for digital native customers.






{kind=link}