
An effective method to improve LLMs' reasoning skills is to employ supervised fine-tuning (SFT) with chain-of-thought (CoT) annotations. However, this approach has limitations in terms of generalization because it relies heavily on the provided CoT data. In scenarios such as mathematical problem solving, each question in the training data typically has only one annotated reasoning path. In the ideal case, it would be more beneficial for the algorithm to learn from multiple annotated reasoning paths associated with a given question, as this could improve its overall performance and adaptability.
Researchers at ByteDance Research Lab suggest a practical method known as reinforced fine tuning (ReFT) to improve the learning generalization capabilities of LLMs for reasoning, using mathematical problem solving as an illustrative example. The ReFT approach begins by initially warming up the model through SFT. It then leverages online reinforcement learning, specifically employing the proximal policy optimization (PPO) algorithm. During this tuning process, the model is exposed to several automatically sampled reasoning paths based on the given question. The rewards for reinforcement learning come naturally from real answers, contributing to a more robust and adaptable LLM to improve reasoning skills.
Recent research efforts have focused on improving rapid CoT design and data engineering, with the goal of making CoT comprehensive and detailed for step-by-step reasoning solutions. Some approaches have used Python programs as CoT prompts, demonstrating more precise reasoning steps and significant improvements over natural language CoT. Another line of work focuses on improving the quality and quantity of CoT data, including efforts to increase the quantity of CoT data from OpenAI's ChatGPT. Reinforcement learning has been applied to paradigm tuning to improve performance over conventional supervised tuning, specifically for mathematical problem solving.
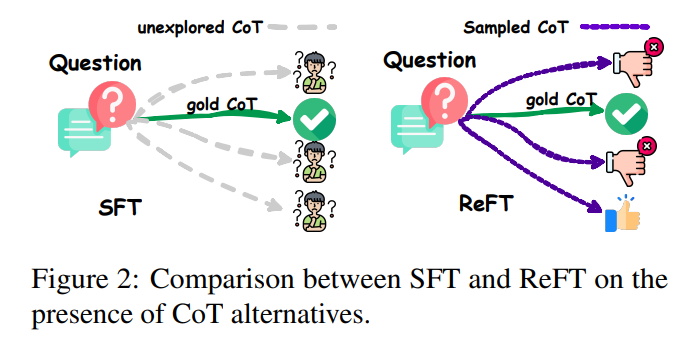
The study proposes ReFT to improve the generalization of LLM learning for reasoning, specifically in mathematical problem solving. ReFT combines SFT with online reinforcement learning using the PPO algorithm. The model is first warmed up with SFT and then fine-tuned using reinforcement learning, where multiple reasoning paths are automatically sampled given the question, and rewards are derived from true answers. Additionally, inference timing strategies such as majority voting and reranking are combined with ReFT to further boost performance.
The ReFT method significantly outperforms the SFT in terms of reasoning ability and generalization for LLMs in mathematical problem solving. Extensive experiments on GSM8K, MathQA, and SVAMP datasets demonstrate the better performance of ReFT over SFT. The performance of ReFT can be further improved by combining inference timing strategies such as majority voting and reranking. They use Python programs as CoT prompts, showing more precise reasoning steps and significant improvements over natural language CoT. Previous work on reinforcement learning and reclassification has also shown better performance than supervised tuning and majority voting.
In conclusion, ReFT stands out as a tuning method to improve models in solving mathematical problems. Unlike SFT), ReFT optimizes a non-differentiable objective by exploring multiple CoT annotations instead of relying on a single one. Extensive experiments on three data sets using two fundamental models have shown that ReFT outperforms SFT in performance and generalization. Models trained with ReFT show support for techniques such as majority voting and reward model reranking. ReFT outperforms several open source models of similar sizes in solving mathematical problems, highlighting its effectiveness and practical value.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook community, Discord channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our Telegram channel
![]()
Sana Hassan, a consulting intern at Marktechpost and a dual degree student at IIT Madras, is passionate about applying technology and artificial intelligence to address real-world challenges. With a strong interest in solving practical problems, she brings a new perspective to the intersection of ai and real-life solutions.
<!– ai CONTENT END 2 –>





{kind=link}