
Practical deployment of multi-million-parameter neural classifiers in real-world systems poses a significant challenge in information retrieval (IR). These advanced neural classifiers demonstrate high efficiency, but are hampered by their significant computational requirements for inference, making them impractical for production use. This dilemma poses a critical problem in IR, as it is necessary to balance the benefits of these large models with their operational viability.
There have been significant research efforts in this field, including the use of synthetic text from PaLM 540B and GPT-3 175B for knowledge transfer to smaller models such as T5, multi-step reasoning using FlanT5 and code-DaVinci-002 and cross distillation. -attention scores for click rate prediction, integrating contextual features. Several researchers have worked on distilling the self-attention module of transformers. Progress has also been made using MarginMSE loss for two distinct purposes: one to distill knowledge into different architectural designs and another to refine sparse neural models. Pseudotags from advanced cross-encoder models such as BERT are one of the methods to generate synthetic data for domain adaptation of dense passage retrievals.
Researchers from UNICAMP, NeuralMind, and Zeta Alpha proposed a method called InRanker to distill large neural classifiers into smaller versions with greater effectiveness in out-of-domain scenarios. The approach involves two distillation phases: (1) training on existing supervised teacher soft labels and (2) training on teacher soft labels for synthetic queries generated using a large language model.
The first phase uses real-world data from the MS MARCO dataset to familiarize the student model with the classification task. The second phase uses synthetic queries generated by an LLM based on randomly selected corpus documents. It aims to improve zero generalization using synthetic data generated from an LLM. The distillation process allows smaller models such as monoT5-60M and monoT5-220M to improve their effectiveness using the teacher's knowledge despite being significantly smaller.
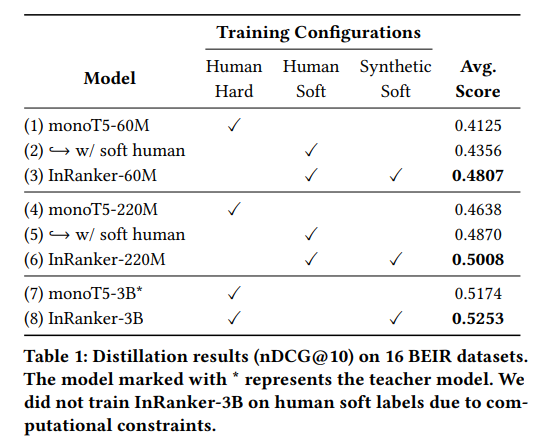
The research successfully demonstrated that smaller models such as monoT5-60M and monoT5-220M, distilled using the InRanker methodology, significantly improved their effectiveness in out-of-domain scenarios. Despite being substantially smaller, these models were able to match and sometimes exceed the performance of their larger counterparts in various test environments. This advancement is particularly beneficial in real-world applications with limited computational resources, as it provides a more practical and scalable solution for IR tasks.
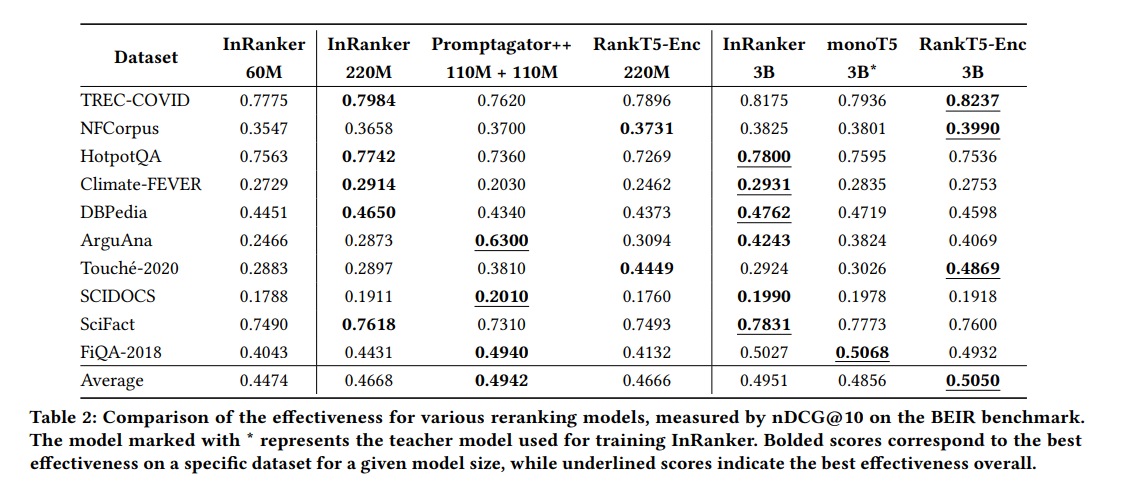
In conclusion, this research marks a significant advance in IR, presenting a practical solution to the challenge of using large neural classifiers in production environments. The InRanker method effectively distills knowledge from large models into smaller, more efficient versions without compromising out-of-domain effectiveness. This approach addresses the computational limitations of deploying large models and opens new avenues for scalable and efficient IR. The findings have substantial implications for future research and practical applications in the field of IR.
Review the Paper and Github. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook community, Discord channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our Telegram channel
![]()
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<!– ai CONTENT END 2 –>






{kind=link}